Decoding Strategies for Large Language Models (LLMs)
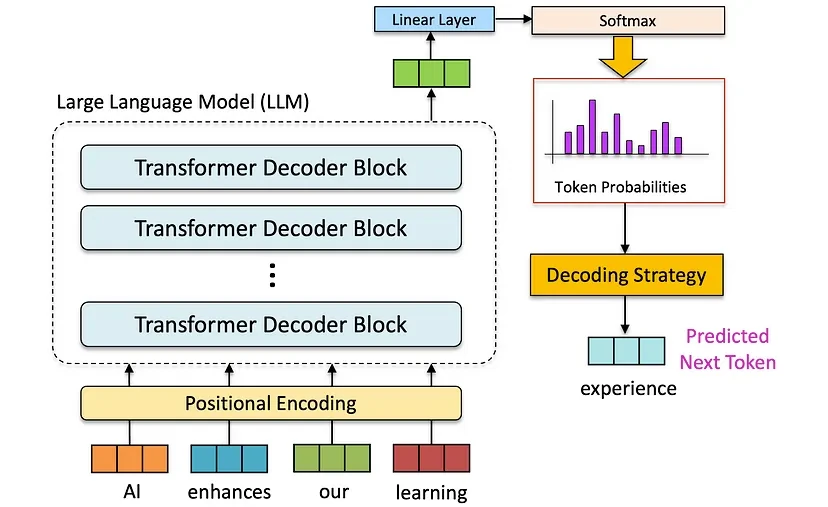
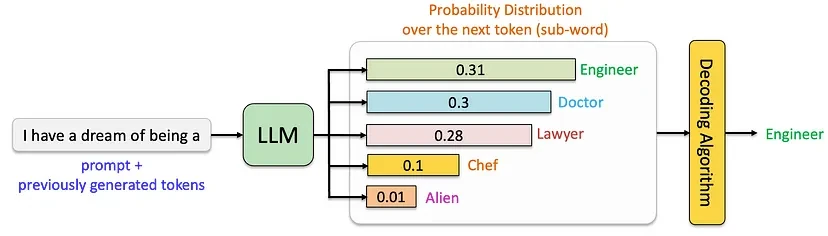
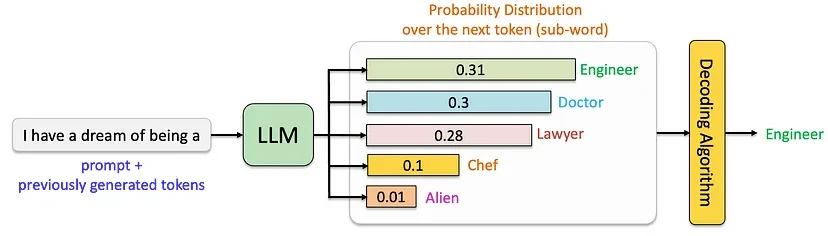
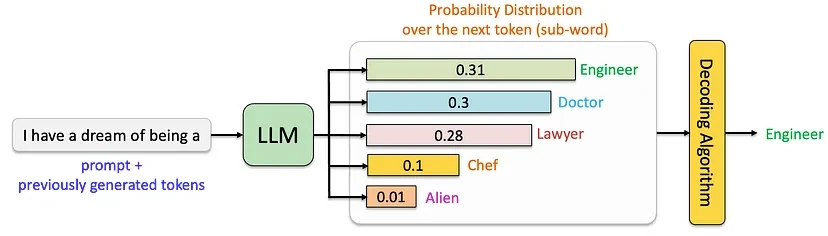
At the core of every large language model (LLM) is a sophisticated process for generating text. Instead of selecting words at random, the model computes a probability distribution over possible next tokens (words or word fragments) based on the input prompt and previously generated text. A decoding strategy is then applied to select the next token, shaping the model's output and balancing predictability with creativity.
Mathematically, the output probability distribution is represented as:
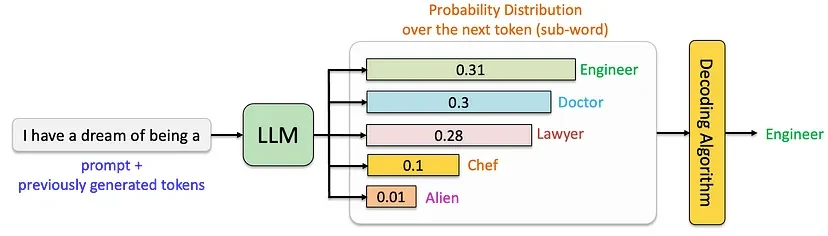
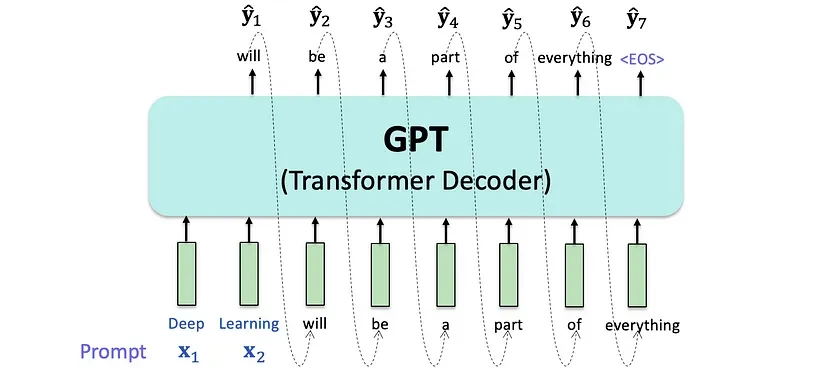
The inference and decoding process can be visualized below:

Overview of LLM Decoding Strategies
How does a model balance predictability and creativity? The answer lies in its decoding strategy. Below, we examine the most widely used large language model decoding strategies, including Greedy Search, Beam Search, Top-K Sampling, Top-P (Nucleus) Sampling, Temperature Sampling, Min-P Sampling, and Mirostat Sampling. Understanding these methods enables practitioners to fine-tune LLM outputs for diverse applications.
📊 API Cost Impact: Different decoding strategies can significantly affect the number of tokens generated and thus your API costs. Use our Token Calculator to estimate costs across different models and sampling parameters before deploying your application.
Greedy Search in LLMs
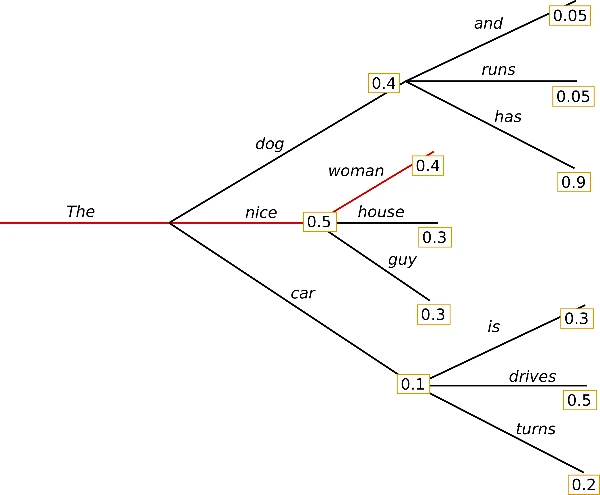
Greedy Search is the simplest decoding algorithm for large language models. At each step, it selects the token with the highest probability.
For example, if the model has generated the word The, and the token nice has the highest conditional probability, it selects nice. This process continues, producing sequences such as The nice woman with a joint probability of 0.5 x 0.4 = 0.2.
Limitation: Greedy Search is shortsighted, optimizing for the best next word, which can lead to locally optimal but globally suboptimal or nonsensical sentences.
Exhaustive Search in Language Models
Exhaustive Search evaluates all possible output sequences and selects the one with the highest overall score. While this guarantees the optimal sequence, the computational cost is prohibitive for modern LLMs, making it impractical in real-world applications.
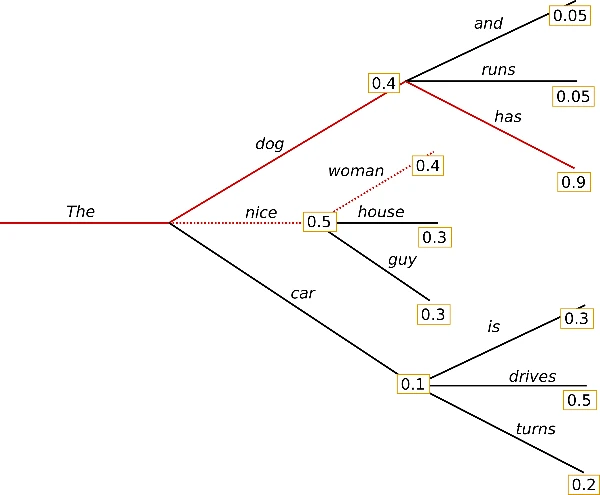
Beam Search Decoding
Beam Search offers a compromise between Greedy Search and Exhaustive Search. By maintaining multiple candidate sequences (beams) at each step, it increases the likelihood of identifying high-probability output sequences without incurring prohibitive computational costs.
💡 Cost Consideration: Beam Search with multiple beams can increase computational costs significantly. Calculate your expected token usage and costs using our Token Calculator to optimize your beam width for the best quality-to-cost ratio.
For instance, with num_beams=2, Beam Search tracks both the most likely hypothesis (The nice) and the second most likely (The dog). In the next step, it may find that The dog has has a higher joint probability than The nice woman, which Greedy Search would have chosen.
Drawbacks: Beam Search can produce repetitive outputs. N-gram penalties are often applied to prevent repeated sequences, but must be used judiciously to avoid suppressing necessary repetitions (e.g., "New York").
Best Use Cases: Beam Search is effective for tasks with predictable output lengths, such as machine translation or summarization, but less suitable for open-ended tasks like dialogue or story generation.
A notable limitation is that outputs may lack diversity and feel generic. Human language is characterized by unpredictability and nuance, which Beam Search may not capture. Controlled randomness can help address this issue.
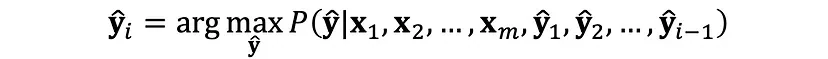
Random Sampling in LLMs
Random Sampling introduces diversity by selecting the next token at random from the entire probability distribution, rather than always choosing the most probable option. While this can yield varied and unexpected outputs, it also risks selecting tokens from the 'long tail'—those with very low probabilities—which can result in incoherent or irrelevant text.

Top-K Sampling Explained
Top-K Sampling addresses the long-tail problem by restricting the candidate pool to the K most probable tokens. The probability mass is redistributed among these K tokens, and sampling occurs within this subset. This approach, popularized by GPT-2, enhances coherence while maintaining diversity.
For example, with K=6, only the top six tokens are considered at each step. This method filters out low-probability, irrelevant candidates, resulting in more coherent text. However, a fixed K may not adapt well to varying probability distributions: a small K may be too restrictive in flat distributions, while a large K may admit less relevant options in peaked distributions.
Top-P (Nucleus) Sampling in LLMs
Top-P (Nucleus) Sampling dynamically selects the smallest set of tokens whose cumulative probability exceeds a predefined threshold, p. This allows the sampling pool to expand or contract based on the model's confidence, balancing coherence and diversity.
Temperature-Based Sampling for LLMs
Temperature scaling adjusts the shape of the probability distribution, controlling the randomness and diversity of generated text. The temperature parameter (t) modifies the distribution as follows:
- When t = 1 (default), the original distribution is used.
- When t > 1, the distribution flattens, increasing the likelihood of selecting less probable tokens and enhancing creativity.
- When 0 < t < 1, the distribution sharpens, concentrating probability on the most likely tokens and improving determinism.
Temperature is typically applied after filtering methods such as Top-K or Top-P, allowing for controlled diversity among a curated set of candidate tokens.
Min-P Sampling: Adaptive Thresholding
Min-P Sampling introduces a dynamic threshold based on the probability of the most likely token. Tokens with probabilities above a fraction (e.g., 0.1) of the maximum are retained for sampling. This approach adapts to the model's confidence, providing a flexible balance between coherence and diversity.

Empirical results show that Min-P can generate more diverse outputs than Top-P at higher temperatures while maintaining coherence. At standard temperatures, its performance is comparable to Top-P.
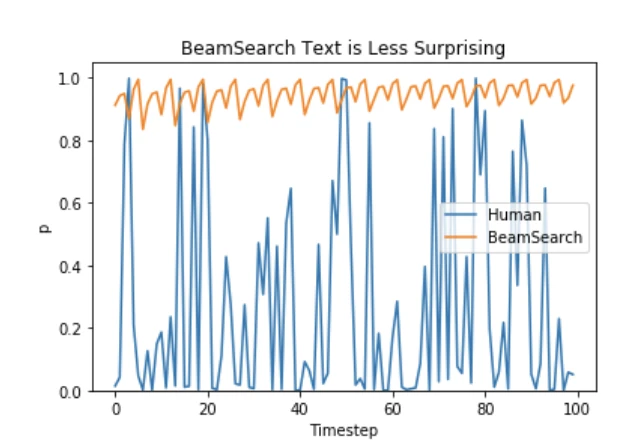
Mirostat Sampling for Controlled Perplexity
Mirostat is an adaptive sampling method designed to maintain a target level of perplexity (a measure of "surprise") in the generated text. By dynamically adjusting the candidate pool, Mirostat helps avoid both repetitive and incoherent outputs.


Mirostat operates in two stages: it estimates the current distribution's characteristics and then adjusts the sampling pool to achieve the desired perplexity. This feedback loop ensures consistent output quality across varying text lengths.
Repetition Control in LLM Decoding
Explicit penalties can be applied to discourage repetition:
- Repetition Penalty: Reduces the probability of tokens that have already appeared.
- Frequency Penalty: Penalizes tokens based on how often they have appeared, encouraging vocabulary diversity.
- Presence Penalty: Applies a fixed penalty to any token that has appeared at least once, promoting the introduction of new concepts.
Best Practices: Sampling Method Execution Order
Combining multiple sampling methods is common practice. The recommended order is:
- Repetition Penalties (Frequency/Presence/Repeat)
- Top-K Filtering
- Top-P Filtering
- Min-P Filtering
- Temperature Scaling
- Final Sampling
This sequence ensures that each step functions as intended, progressively refining the candidate pool before the final selection. Note: Mirostat typically replaces the filtering steps, as it manages the candidate pool dynamically.
Parameter Tuning Recommendations for LLMs
When to Use Min-P Instead of Top-P
- For more diverse output at higher temperatures
- For slightly higher quality at lower temperatures
- For more predictable, adaptive behavior
When to Increase Repetition Penalty
- To address repetitive or looping outputs
- To encourage vocabulary diversity
- To reduce verbosity
When to Avoid a High Repetition Penalty
- If output becomes incoherent
- If phrasing becomes unnatural
- If the model drifts off-topic
Recommended Sampling Settings for Different Scenarios
Sampling settings significantly influence model behavior. Suggested starting points:
- Precise/Factual Tasks (e.g., Q&A, code generation): Low temperature (0.2-0.5)
- Creative/Diverse Tasks (e.g., story writing, brainstorming): Higher temperature (0.7-1.0)
- Balanced Approach: Temperature 0.7 and Top-P 0.9

For most factual scenarios, Min-P with a value around 0.1 is often effective.
Troubleshooting Common LLM Output Issues
Before adjusting sampling parameters, consider model selection, prompt engineering, and context management. Parameter tuning should be iterative, with one change at a time.
Problem: Repetition or Lack of Diversity
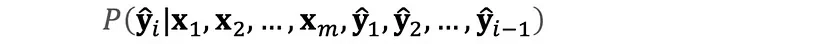
- Increase Repetition Penalty (start at 1.1, increment by 0.05)
- Increase Temperature
- Increase Top-P / Min-P
- Decrease Top-K (use with caution)
Problem: Incoherent or Nonsensical Output

- Decrease Temperature
- Decrease Top-P / Min-P
- Increase Top-K
- Decrease Repetition Penalty
Problem: Factual Inaccuracies or Hallucinations
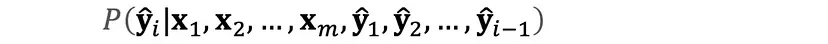
- Decrease Temperature
- Decrease Top-P / Min-P
- Increase Top-K
- Decrease Repetition Penalty
Problem: Output is Too Verbose or Too Short
- Adjust Repetition Penalty
- Adjust Temperature
- Adjust Top-P / Min-P
- Adjust Top-K
Summary: Choosing the Right LLM Decoding Strategy
This guide has explored the principal large language model decoding strategies, from foundational approaches like Greedy Search and Beam Search to advanced techniques such as Top-P (Nucleus) Sampling, Min-P, and Mirostat. Each method offers distinct trade-offs between coherence, diversity, and computational efficiency. Understanding and appropriately tuning these strategies is essential for optimizing LLM output across a range of applications, from factual Q&A to creative writing.
While this article has covered the most widely used algorithms, the field is rapidly evolving. Techniques such as Tail-Free Sampling, Typical Sampling, Contrastive Decoding, and Top-A Sampling are also gaining attention. Continued exploration and experimentation will be key to achieving optimal results in LLM text generation.