The field of artificial intelligence has seen rapid advancements in reinforcement learning for reasoning, particularly within large language models (LLMs). This article reviews influential research shaping RL-based reasoning in LLMs, highlighting major methodological shifts and key findings.
To understand these developments, recent research can be divided into three phases: the Rise, the Cooldown, and the Reality Check. The latter two phases have provided critical insights into the effectiveness of RL-based reasoning.
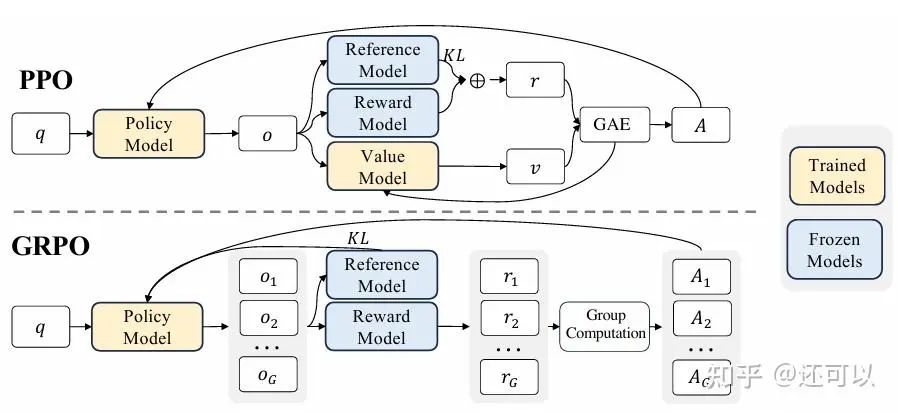
The Rise: The GRPO Era in RL-Based Reasoning
Reinforcement learning for reasoning in LLMs gained momentum with GhostReward Policy Optimization (GRPO). Unlike earlier process-supervised methods, GRPO used simple, rule-based outcome rewards—rewarding only the final correct answer. This approach, validated through algorithms like REINFORCE++, Remax, and Prime, led to significant performance improvements in RL-based reasoning.
Key enhancements followed, notably with Decoupled Advantage Policy Optimization (DAPO):
- Decoupled upper and lower clipping ranges for policy updates, enabling greater exploration and preventing premature convergence.
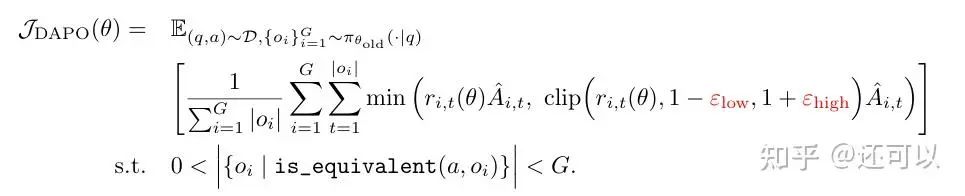
- Filtering out solved/unsolvable prompts to address vanishing gradients and ensure meaningful learning signals in each training batch.
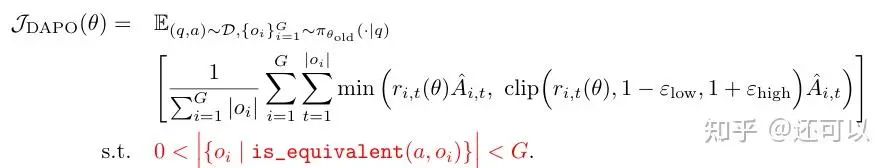
- Transitioning from sample-level to token-level policy gradient loss, accurately weighting each token's contribution.
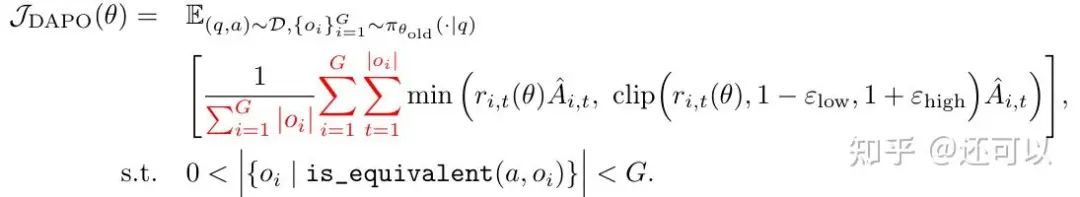
- Introducing a length-aware penalty to stabilize training and reduce reward noise from overly long responses.
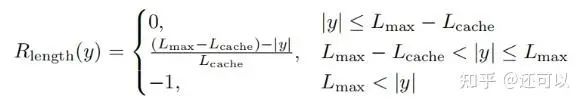
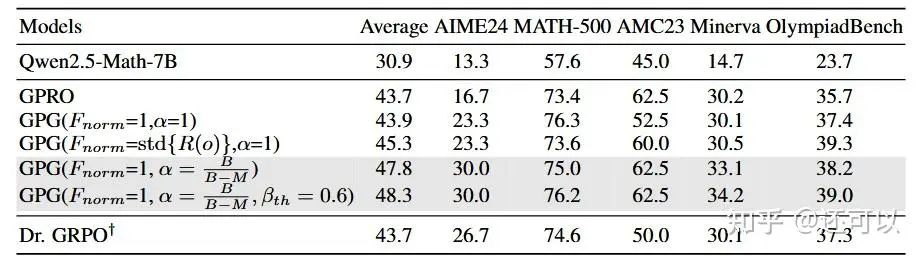
Further research included DR.GRPO, which questioned the standard deviation term in the GRPO formula, and Grafted Policy Gradient (GPG), a minimalist policy-gradient approach with refined implementation techniques. Empirical results showed that removing certain terms could negatively impact performance, emphasizing the importance of careful policy optimization design.


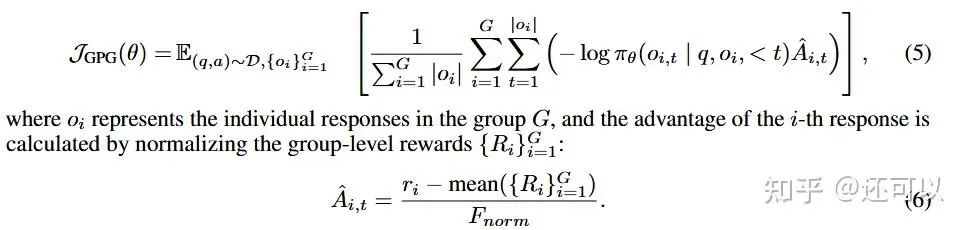
The Cooldown: Competition and Efficient Reasoning Strategies
As RL-based reasoning matured, research focused on optimizing reasoning chains, determining optimal stopping points, and identifying high-quality training samples. This phase was marked by competitive exploration of efficient strategies for reinforcement learning in LLMs.
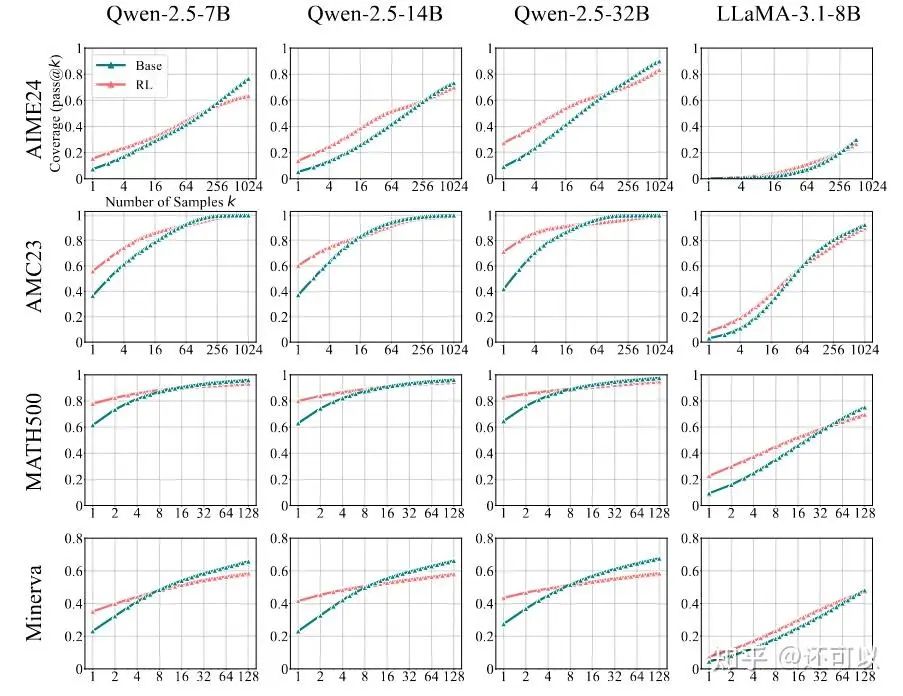
The Reality Check: Evaluating RL's True Impact on Reasoning
A pivotal study from Tsinghua University questioned whether reinforcement learning truly enhances reasoning in large language models beyond what is achieved by supervised fine-tuning (SFT). Results showed that, under the Pass@k metric, RL-tuned models sometimes underperformed compared to their base counterparts, suggesting that many reasoning capabilities could be elicited from SFT models with sufficient sampling. This led to a reevaluation of RL's actual contributions to reasoning tasks in LLMs.
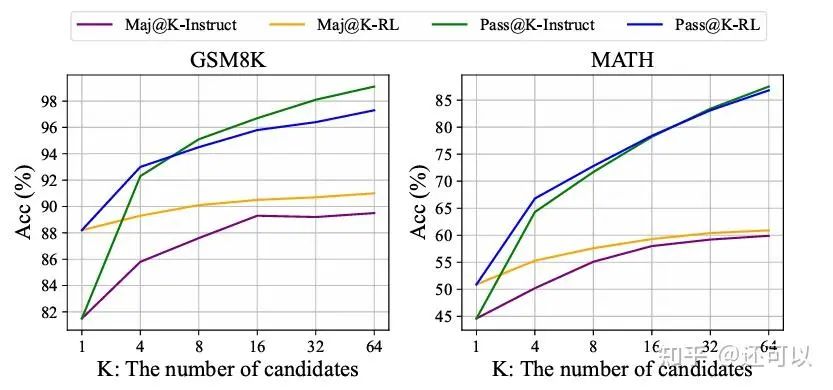
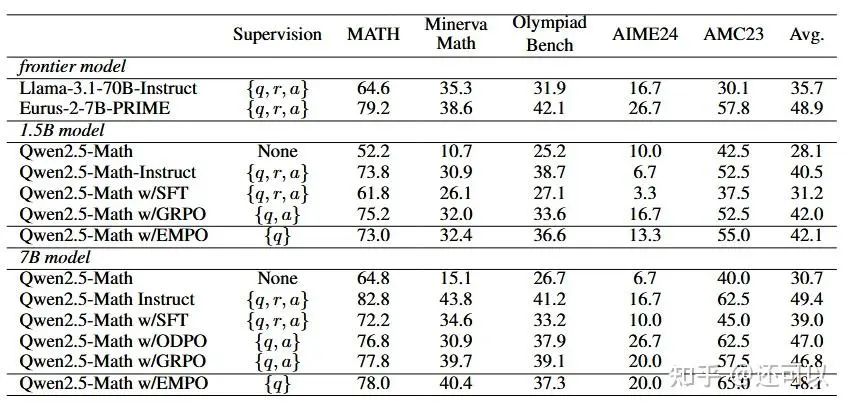
Subsequent research explored model improvement without external ground truth. Expectation-Maximization Policy Optimization (EMPO) rewarded models for generating consistent response clusters, minimizing entropy. Methods like majority voting and test-time training further investigated self-correction through output consistency.
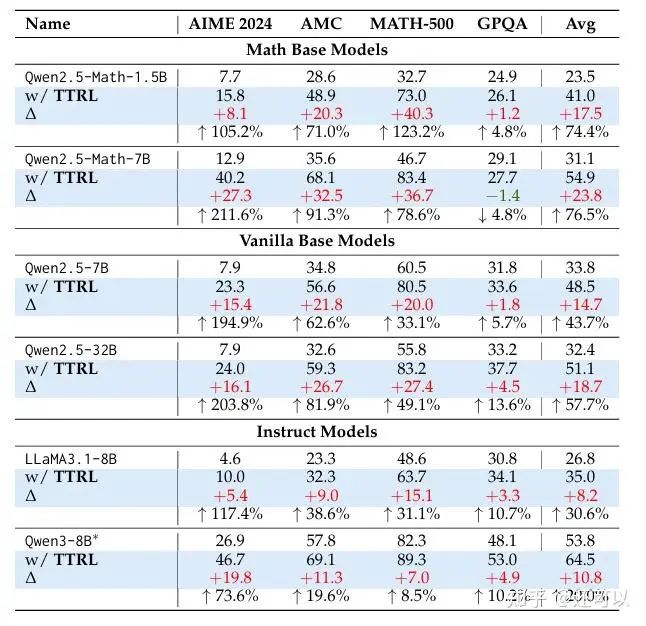
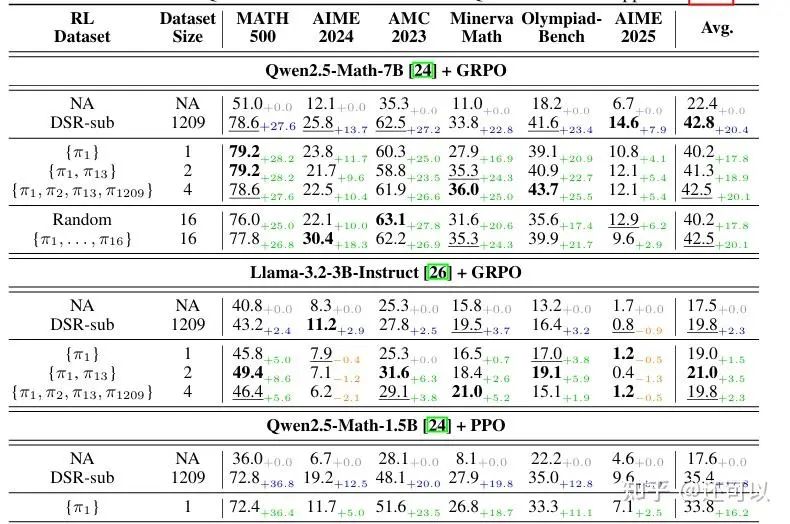
Despite academic debate on novelty and timing, a key theme emerged: LLMs can self-correct by observing their outputs, even without external labels.
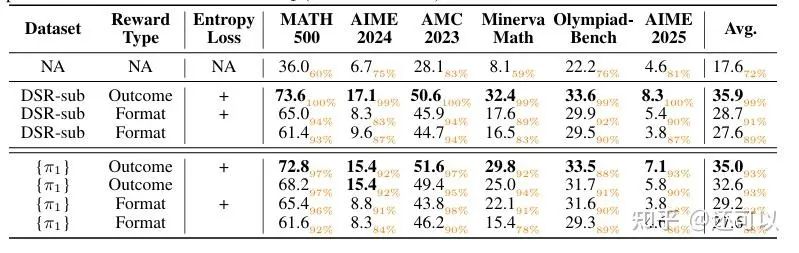
Entropy Minimization: A New Objective in RL-Based Reasoning
Recent research has focused on entropy minimization as a core training objective for RL-based reasoning. Studies demonstrated that training on high-variance samples and minimizing entropy led to significant gains, highlighting the importance of uncertainty reduction. Ablation studies confirmed that entropy loss was central to these improvements.
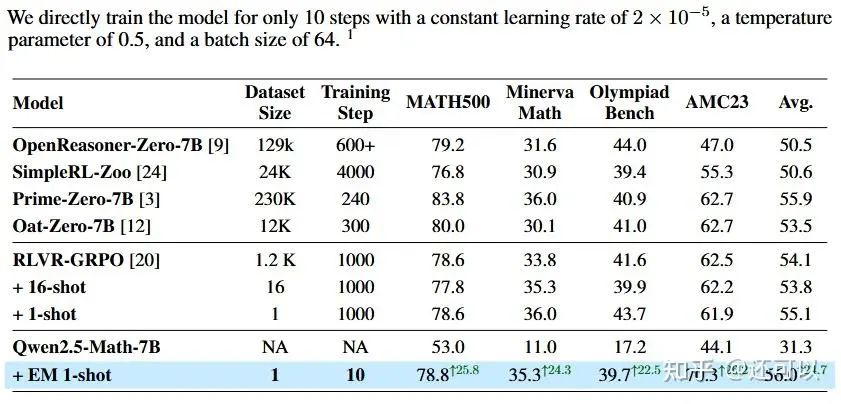
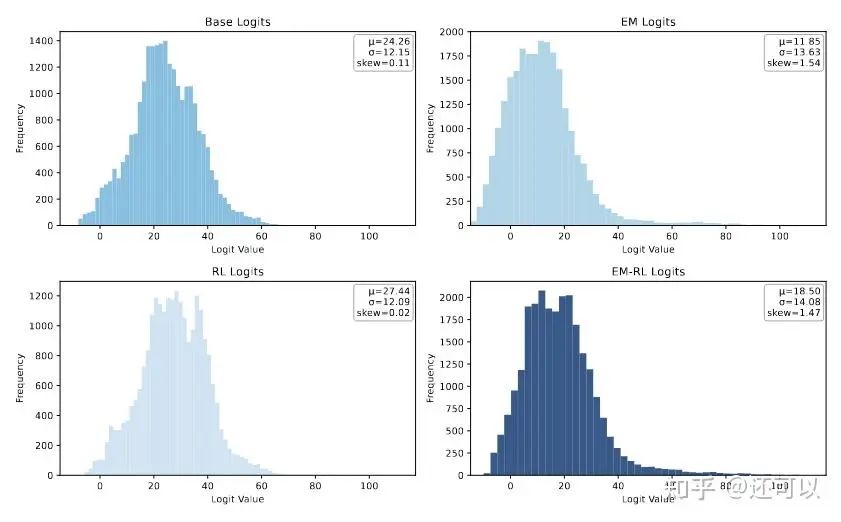
Further work involved multi-step training on single samples using entropy as the reward, achieving strong—though sometimes unstable—results. Analysis of logit distributions showed that entropy regularization increased model confidence across related outputs, reshaping the probability landscape for reasoning tasks.

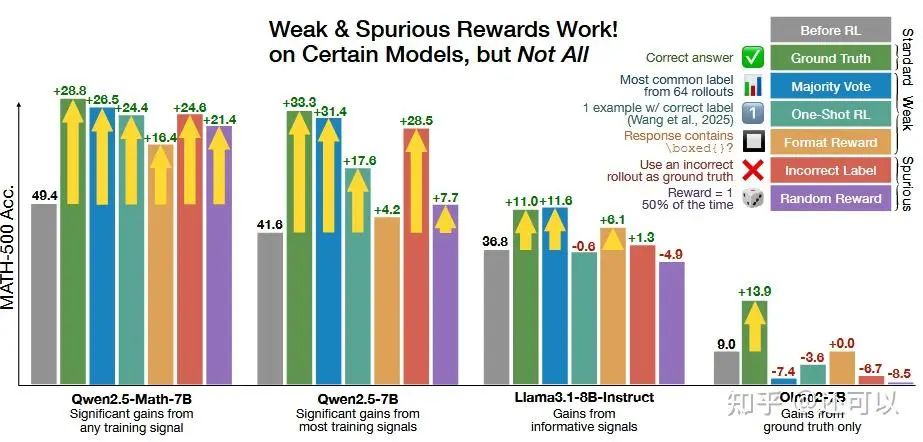
The Final Twist: Effects of Spurious Rewards in RL
A comprehensive study evaluated various reward signals, including random and incorrect rewards. Surprisingly, even spurious signals improved model performance, suggesting that RL reward mechanisms primarily amplify a model's existing confidence. However, this effect was model-dependent; on some base models, only proper RL methods led to significant improvements in reasoning performance.
Future Directions for RL-Based Reasoning in LLMs
In summary, the evolution of reinforcement learning for reasoning in large language models has shifted from external feedback to pseudo-labels, and now to self-consistency and entropy-based methods. While recent findings suggest that many improvements reinforce existing model inclinations, robust feedback-driven learning remains essential as research expands to more complex reasoning tasks. This ongoing reality check refines and strengthens the discipline, ensuring continued progress in RL-based reasoning for LLMs.