Single-Controller vs Multi-Controller in veRL: Lessons from Pathways
When exploring a new reinforcement learning framework like veRL, understanding the difference between single-controller and multi-controller architectures is crucial. These concepts, foundational to distributed reinforcement learning, are rooted in Google's influential 2022 "Pathways" paper, which shaped the design of veRL and other distributed AI systems.
What Are Single-Controller and Multi-Controller Architectures?
- Multi-controller: Each process (often one per GPU) runs identical code, communicating via collective operations like
AllReduceorAllGather. ThisSPMD(Single Program, Multiple Data) approach is common in frameworks like PyTorch and is ideal for data-parallel training. - Single-controller: A central master node defines the entire computation graph, orchestrating distributed workloads across hardware. Each node may execute different programs (
MPMD- Multiple Program, Multiple Data), allowing dynamic resource allocation and greater flexibility—key for complex reinforcement learning tasks.
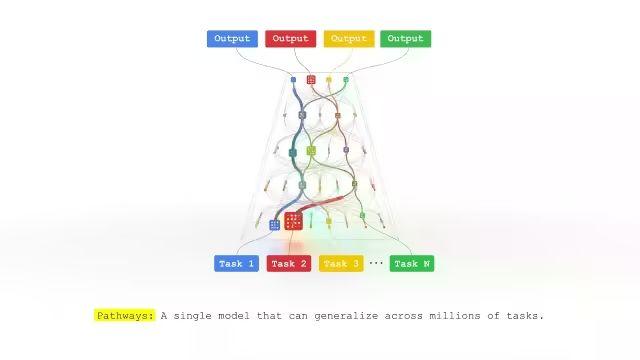
Pathways: The Blueprint for Distributed AI
In 2022, Google's Pathways architecture powered the 540B parameter PaLM model, setting new standards for large language models. Pathways introduced:
- The distinction between single-controller and multi-controller systems
- Solutions for pipeline parallelism and Mixture of Experts (MoE) architectures
- Dynamic resource management for distributed AI workloads
While multi-controller models excel at SPMD tasks, Pathways anticipated the need for more flexible approaches as AI workloads grew in complexity. The single-controller model enables orchestration of dynamic, heterogeneous resources—essential for modern RL frameworks like veRL.
Implementation Challenges in veRL and Modern Solutions
Implementing a single-controller architecture in open-source environments often uses Ray, mapping computation graph nodes to Ray Actors. However, scaling introduces challenges:
- Scheduling Overhead: TPUs require JIT compilation and can incur deadlocks; GPUs are less affected but still face risks, as detailed in OneFlow's analysis of NCCL deadlocks.
- Data Transfer Bottlenecks: Centralized object stores (like Ray's) can limit scalability. Explicit data movement and techniques like scratchpad memory are often preferable for AI accelerators.
- Resource Allocation: Single-controller enables dynamic assignment of hardware resources, unlike the fixed allocation in multi-controller setups.
Beyond Binary Choices: Microservices in Distributed RL
Not all distributed AI programs fit neatly into single- or multi-controller categories. A third pattern—microservices architecture—is often optimal for certain MPMD workloads, such as LLM inference engines or diffusion model pipelines. Here, independent services communicate via event loops, balancing flexibility and scheduling efficiency.
Key Takeaways for Reinforcement Learning Architects
- Single-controller: Best for complex, dynamic RL workloads needing flexible orchestration and resource management.
- Multi-controller: Optimal for SPMD tasks with homogeneous resources and robust parallelism.
- Microservices: Suitable for MPMD tasks with low compute-to-communication ratios and high scheduling sensitivity.
Understanding these distributed architectures is essential for building scalable, efficient reinforcement learning frameworks like veRL.