Multi-head attention is a core mechanism in the Transformer architecture, driving state-of-the-art models in natural language processing and other domains. By enabling the model to attend to different parts of an input sequence in parallel, multi-head attention creates richer, more nuanced representations. But how does multi-head attention work, and what is the specific role of linear layers in this process?
What Is Multi-Head Attention in Transformers?
Multi-head attention allows the Transformer to focus on various aspects of the input sequence simultaneously. The input is split into Query, Key, and Value vectors, which are projected into multiple lower-dimensional subspaces—these are the 'heads.' Each head processes the input independently, learning to attend to different relationships within the data.
After these parallel attention calculations, the outputs from each head are concatenated and passed through a final linear layer. This step integrates the diverse information from all heads, producing a unified output suitable for the next layer in the model.
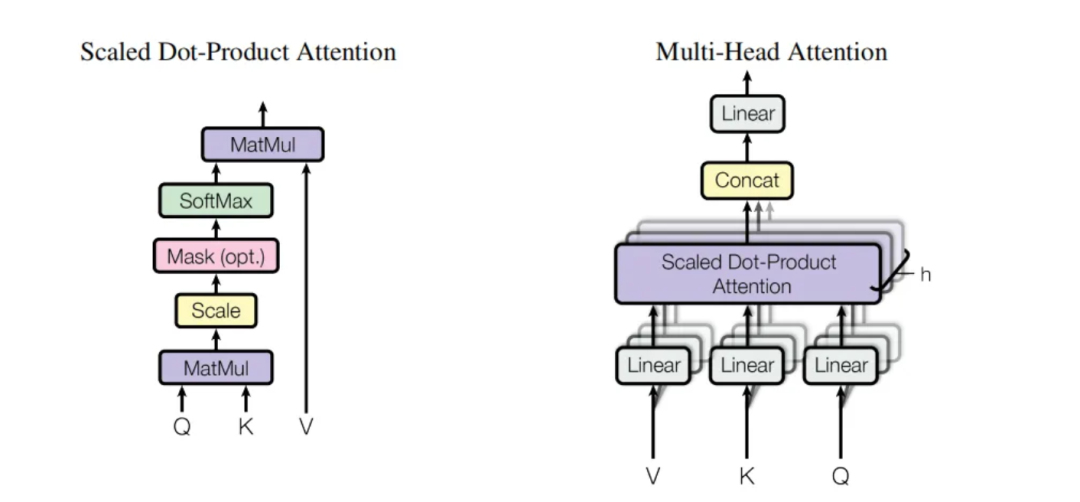
How Linear Layers Enable Multi-Head Attention
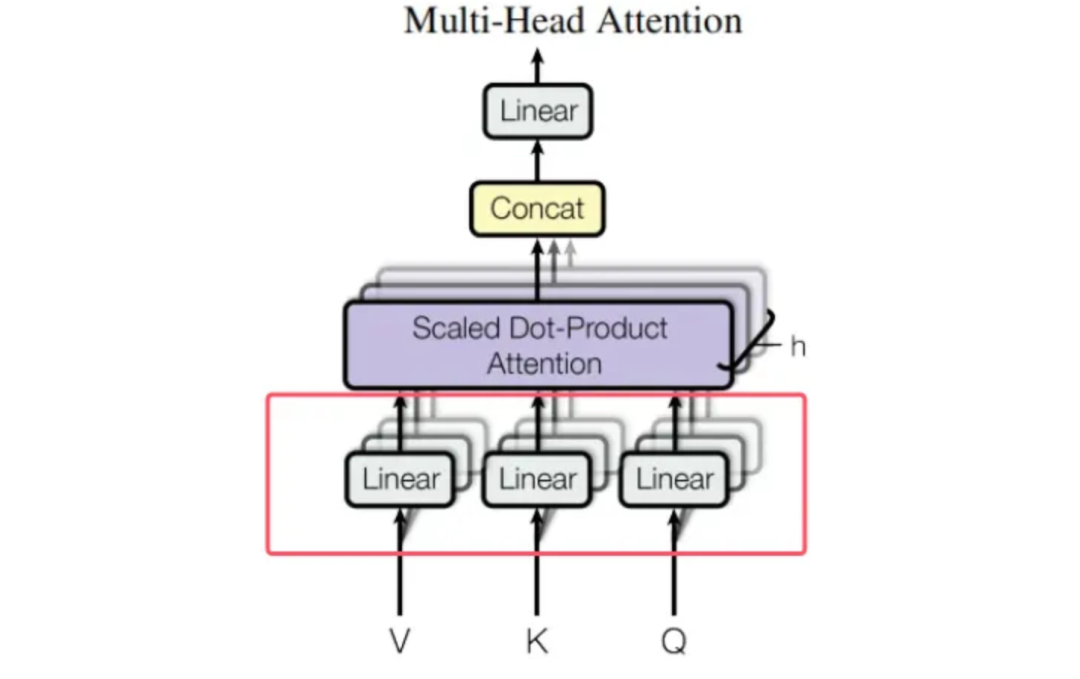
1. Creating Query, Key, and Value with Linear Layers
In PyTorch, linear transformations are implemented using the nn.Linear class. Each nn.Linear layer contains a learnable weight matrix and bias vector. In a typical Transformer implementation, such as the MultiHeadedAttention class, four linear layers are used, with the last reserved for output integration.
Step-by-Step Process:
-
Generating Input Vectors
- The input sentence (e.g., "I love AI") is tokenized and converted to vectors using word embeddings and positional encodings. Each token becomes a vector of dimension
d_model(commonly 512).
- The input sentence (e.g., "I love AI") is tokenized and converted to vectors using word embeddings and positional encodings. Each token becomes a vector of dimension
-
Projecting Inputs into Q, K, and V
- Three separate
nn.Linearlayers project the input vectors into Query (Q), Key (K), and Value (V) matrices using unique weight matrices (W^Q,W^K,W^V). - This projection creates distinct views of the input, allowing the model to analyze relationships from multiple perspectives.
- Three separate
-
Splitting into Multiple Heads
- The resulting Q, K, and V matrices are split along their feature dimension to form multiple heads. Each head processes a different subspace of the input in parallel, enhancing the model's expressive power.
2. Integrating Outputs: The Final Linear Transformation
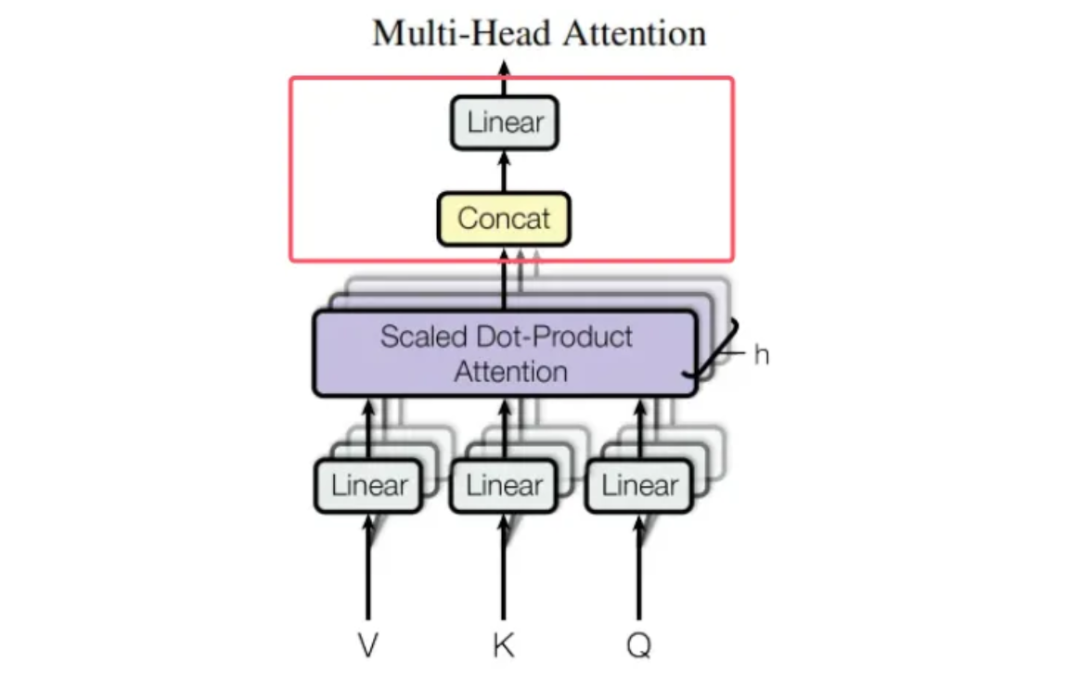
After attention is computed in each head, their outputs are concatenated. However, simple concatenation does not integrate the information meaningfully. The final linear layer addresses this by:
- Synthesizing Diverse Perspectives: The linear layer learns the optimal way to combine outputs from all heads, weighing their contributions based on the task.
- Restoring Dimensionality: Concatenation increases the vector size to
num_heads * head_dim, typically matchingd_model. The final linear layer projects this back tod_model, ensuring compatibility with subsequent layers, such as the feed-forward network. - Adding Expressiveness: This transformation introduces additional learnable parameters, further enhancing the model's representational capacity.
Summary: Why Linear Layers Matter in Multi-Head Attention
Linear layers are essential in multi-head attention for:
- Projecting input vectors into Q, K, and V spaces
- Enabling parallel attention computations across multiple heads
- Integrating and refining outputs into a unified representation
This design allows Transformers to capture complex relationships in data and ensures seamless integration with other model components, making it a foundational element of modern deep learning systems.