MemOS: Persistent Memory for LLMs & Next-Gen AI Agents
Ever asked your AI assistant, "Can you list my meetings for today?" and received a perfect answer, only to find it can't recall past events or summarize previous conferences? This limitation highlights a key challenge in large language models (LLMs): the lack of persistent memory. Each interaction is stateless, with no accumulation of knowledge or continuity. To transform AI from reactive tools into proactive partners, we need systems that enable memory, learning, and evolution. Enter MemOS—the Memory Operating System for LLMs.
Why LLMs Need Persistent Memory
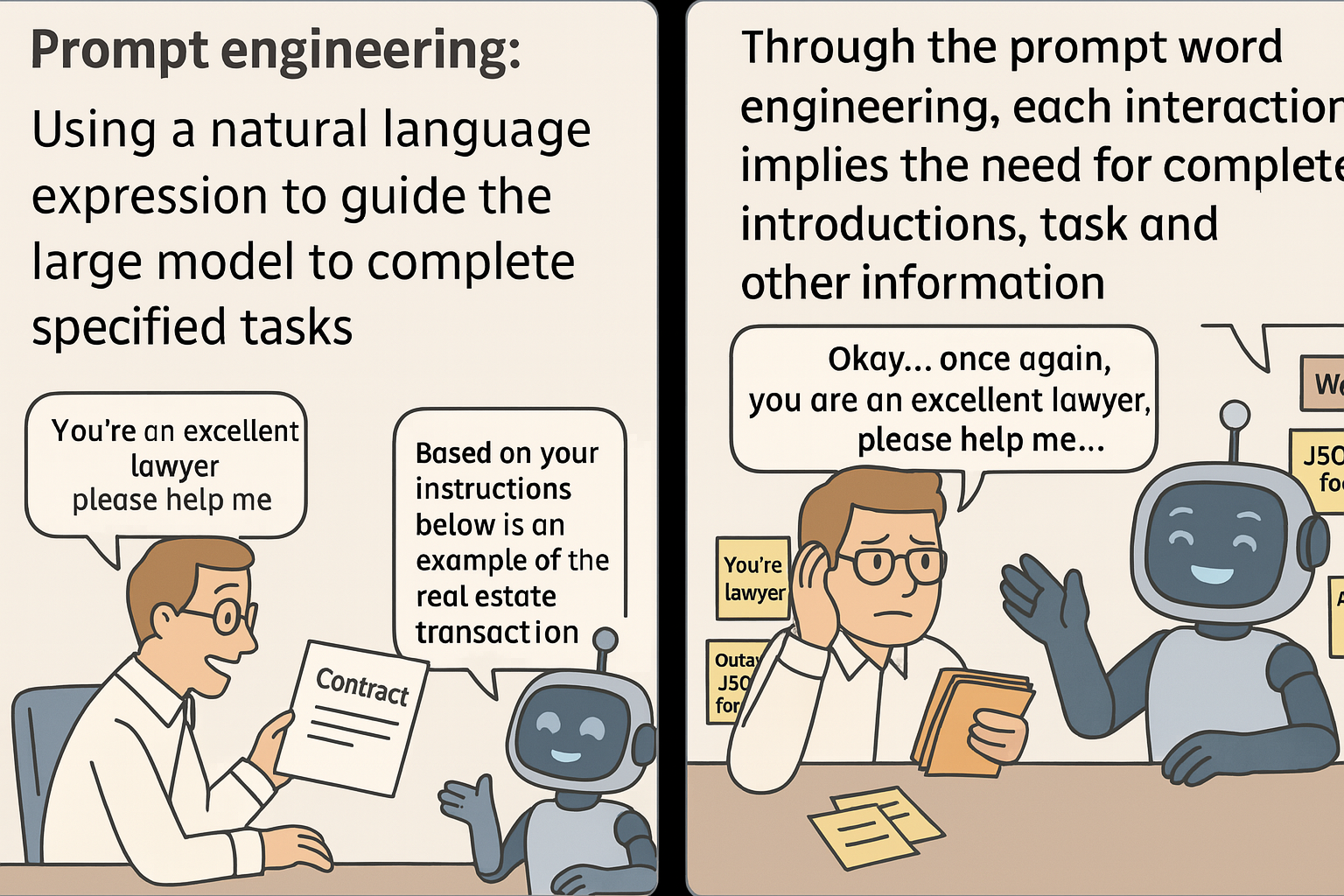
When OpenAI's GPT-3 popularized LLMs, prompt engineering became essential for guiding model behavior. However, without persistent memory, every interaction requires repeating context, leading to inefficiency and fragmented experiences.
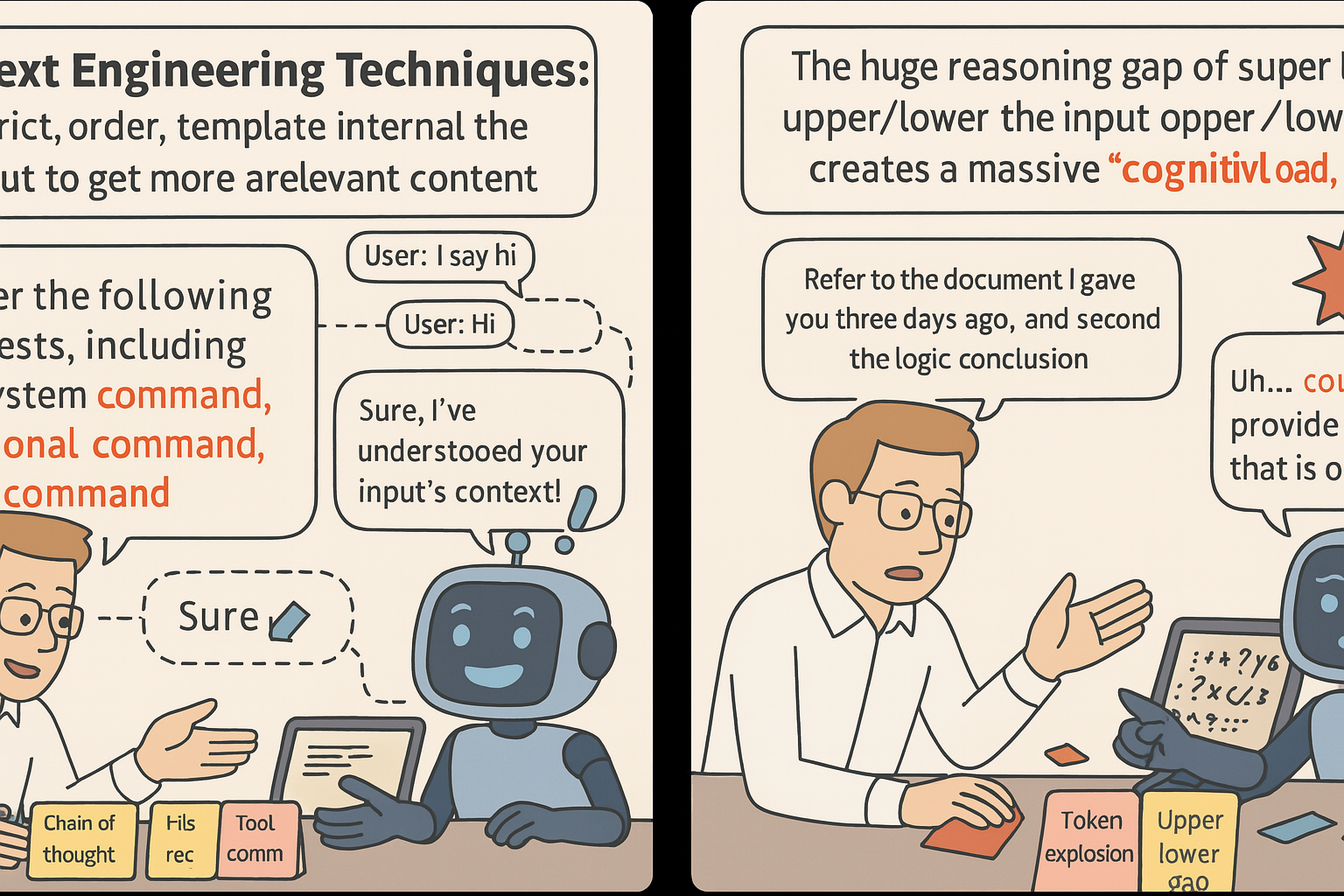
Context engineering emerged to provide models with relevant information for each task. Techniques like retrieval-augmented generation (RAG), expanding context windows, and appending multi-turn dialogue history improve coherence. Yet, these methods are limited by finite context windows, increased computational costs, and session-based memory that disappears after each interaction.
To overcome these barriers, a persistent, schedulable, and learnable memory system is required—the core mission of MemOS.
What Is MemOS? The Memory Operating System for LLMs
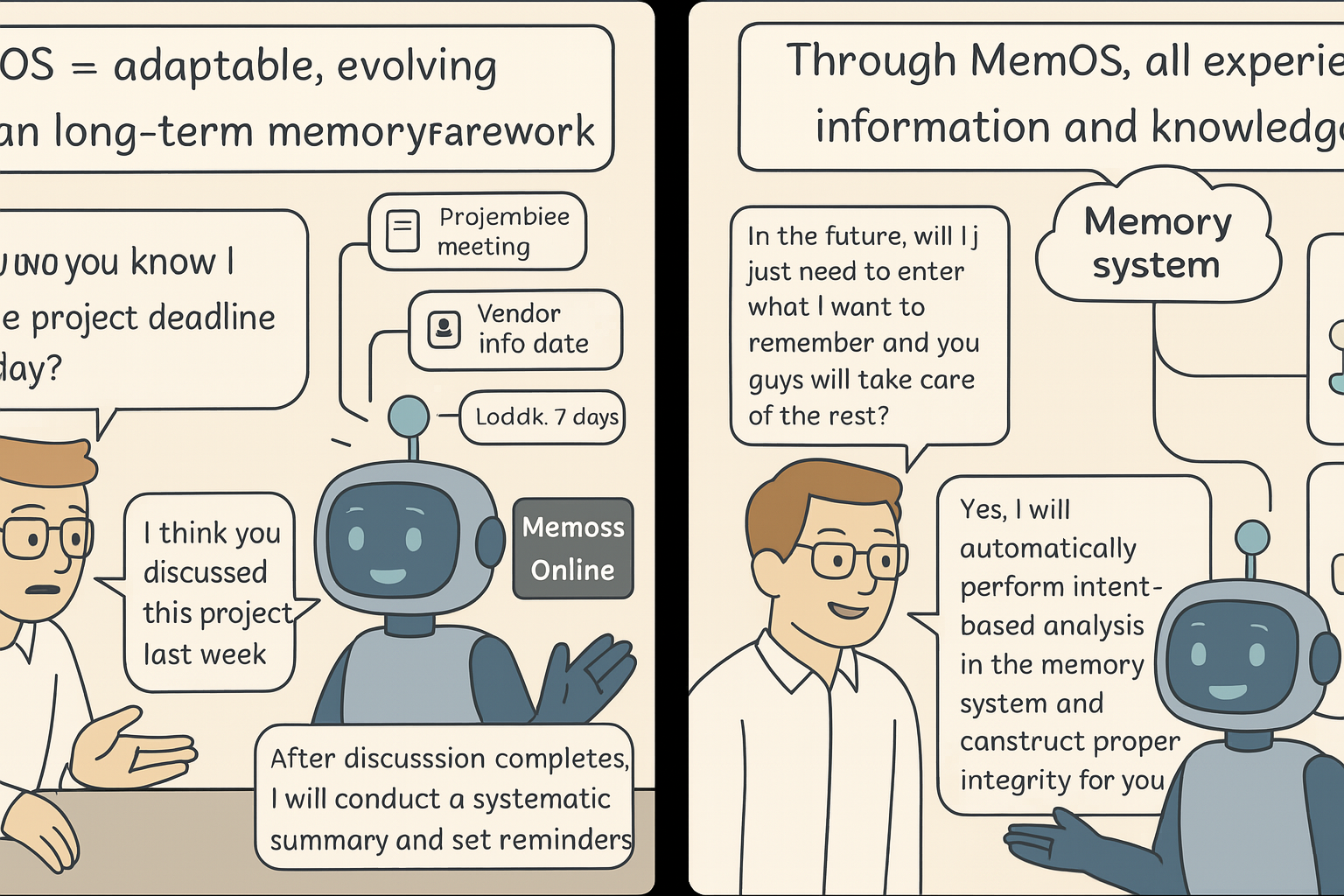
If prompts are an LLM's raw commands and context is its temporary RAM, then MemOS is its persistent hard drive. MemOS provides the cognitive foundation that enables AI to develop continuity and long-term learning.
MemOS builds on the Memory³ layered memory model, introducing layered management and scheduling of memory for LLMs.
Key Benefits of MemOS
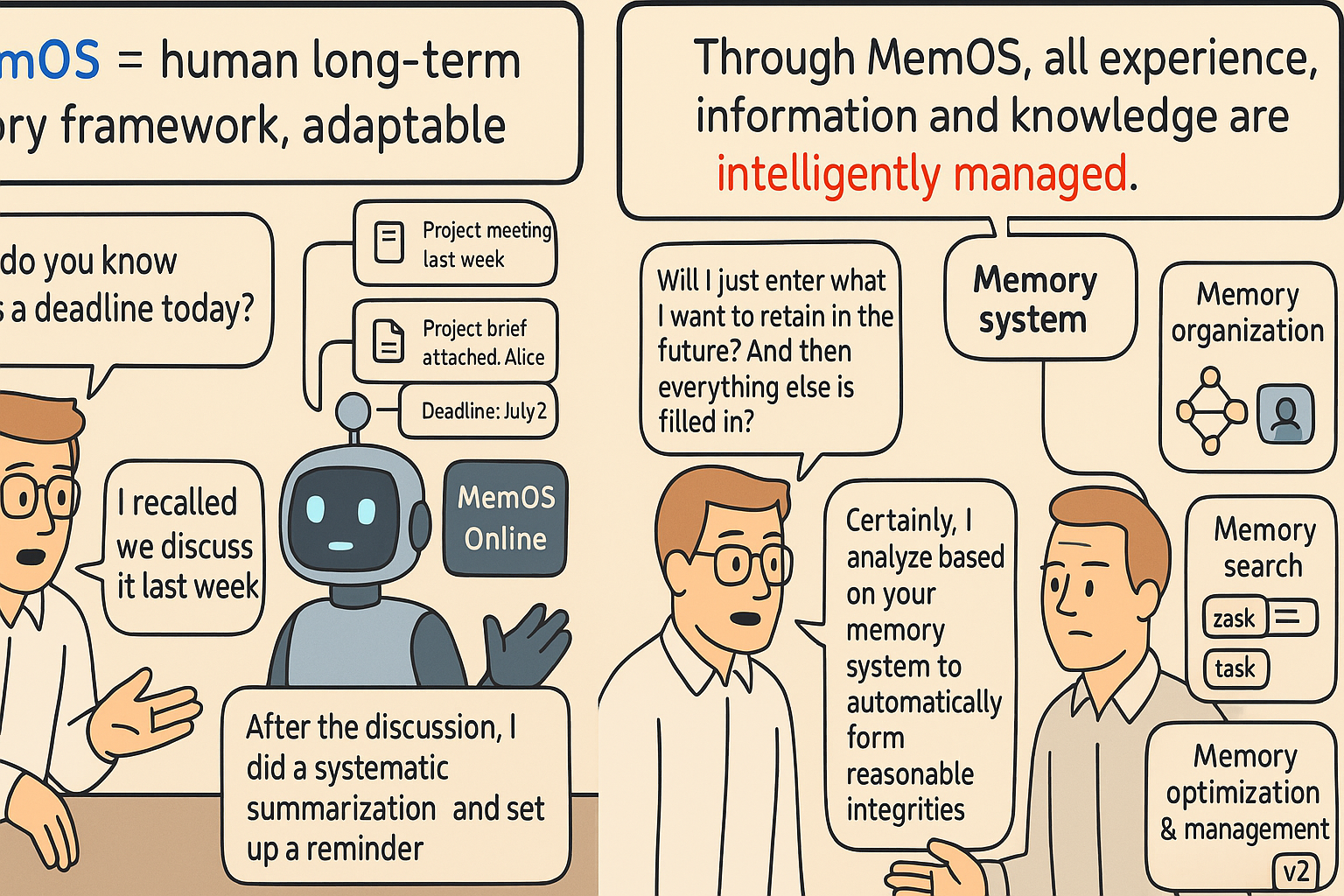
With MemOS, AI assistants can:
- Remember long-term goals and user preferences
- Track task progress and execution feedback
- Understand roles and contexts across different scenarios
- Anticipate user needs proactively
This persistent memory transforms LLMs from static generators into adaptive digital colleagues.
MemOS Features and Architecture
As LLMs evolve from single-turn tasks to complex, multi-turn workflows, MemOS advances a core proposition:
Large language models should not only possess language abilities but also have schedulable and evolvable memory.
MemOS is an open-source framework for LLM memory management. The preview version includes:
- Memory API: Standardized interface for reading from and writing to memory.
- Memory Scheduler: Predictive scheduler that anticipates future memory needs.
- MemCube: Unified memory unit for managing plaintext, activations, and parameters.
By standardizing memory units, MemOS unifies disparate memory types under a single framework for scheduling, fusion, and access control. This allows models to retain and evolve knowledge, supporting advanced AI agents.

Technical Architecture of MemOS
MemOS architecture is inspired by traditional operating systems and the Memory³ layered memory model. It consists of three layers:
- Interface & Application Layer: Unified Memory API for developers to create, modify, delete, and retrieve memory. Enables multi-turn conversational memory, cross-task state tracking, and persistent user profiles.
- Memory Scheduling & Management Layer: Predictive Memory Scheduling preloads memory content anticipated for future use, reducing latency and optimizing efficiency.
- Memory Storage & Infrastructure Layer: Uses standardized MemCube encapsulation to integrate plaintext, activations, and parameters. Supports various persistent storage backends and enables memory migration across models.
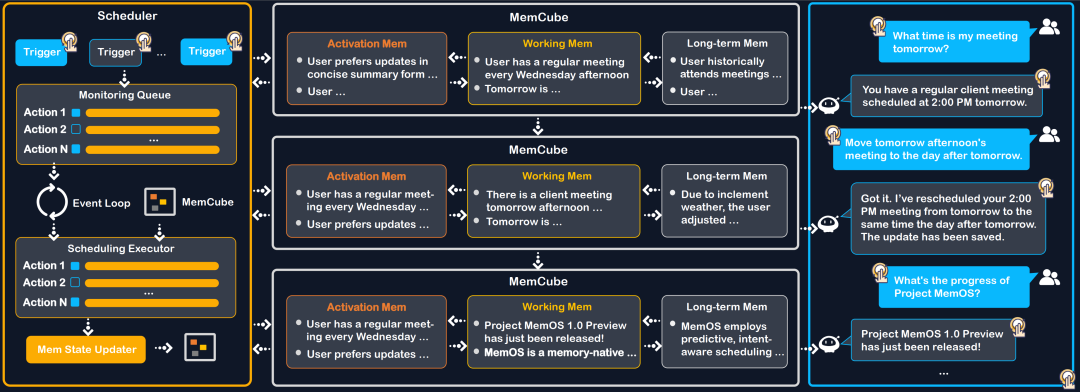
As shown in Figure 1, MemOS can asynchronously predict and prepare memory fragments for future turns, sessions, or collaborative multi-agent workflows. Application flow triggers collect memory cues, which are sent to a unified monitoring queue and processed by the scheduling executor. The scheduler prioritizes preloading high-value memory fragments into the MemCube, ensuring critical memory is always available for the model.
MemOS enables structured, systematic AI memory management, laying the foundation for a future ecosystem of shareable and transferable AI memory.
- Project Website: https://memos.openmem.net/
- GitHub: https://github.com/MemTensor/MemOS
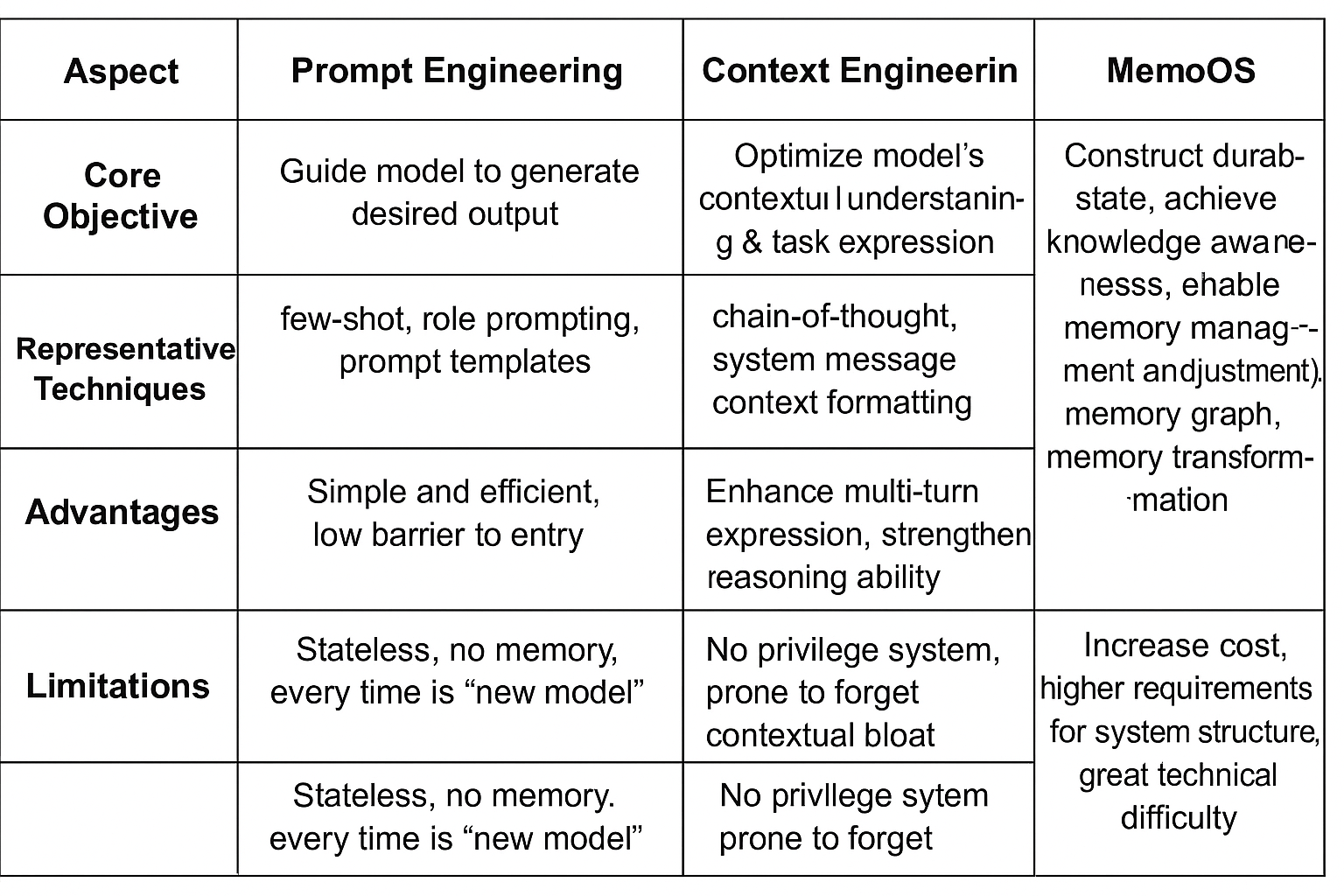
The Evolution: From Prompt and Context Engineering to MemOS
Prompt and context engineering have advanced LLMs, but both lack true state and personalization:
- Prompt Engineering: One-off commands; the model responds and the interaction ends.
- Context Engineering: Provides short-term memory for current conversations but lacks recall of past interactions.
MemOS marks a pivotal shift from static dialogue to dynamic cognition. By enabling persistent memory extraction, structured organization, and cross-session recall, models can proactively understand users and anticipate their needs.
Human intelligence is built on the ability to remember and act accordingly. MemOS provides the technical foundation for AI to achieve similar growth and adaptability.
How MemOS Complements Prompt and Context Engineering
- Use Prompt Engineering to specify tasks.
- Use Context Engineering to enhance short-term performance.
- Use MemOS to enable long-term learning and personalization.
This is the essential next step for AI applications to evolve into intelligent agents.
Intelligence starts with memory.
MemOS: Helping AI not just respond, but truly understand.
Large language models should not only possess language abilities but also have schedulable and evolvable memory.
Just as human intelligence stems not only from perception and reaction but from the ability to remember and act accordingly, MemOS is the technical foundation that gives large models the capacity for growth and adaptability.