Baidu ERNIE 4.5: Advancements in Multimodal Large Language Models
Baidu's ERNIE 4.5 marks a major leap in artificial intelligence, especially in the development of multimodal large language models (LLMs). As part of its latest release, Baidu has open-sourced ten cutting-edge multimodal models, featuring both sparse Mixture-of-Experts (MoE) and dense architectures. These models are engineered to deliver superior performance across tasks involving text, images, and other modalities.
Innovative Heterogeneous Model Architecture
At the core of ERNIE 4.5 is a heterogeneous model structure. This architecture fuses knowledge from different modalities—such as text and images—using a shared parameter mechanism, while also providing each modality with dedicated capacity. This design enhances multimodal understanding and can improve results even on pure text tasks.
Specialized Post-Training and Fine-Tuning
Rather than focusing only on pre-training, ERNIE 4.5 emphasizes the post-training phase, where models are refined for specialized tasks through advanced fine-tuning techniques.
Fine-Tuning for Language and Multimodal Models
- Large Language Models (LLMs): Optimized for general language comprehension and generation.
- Multimodal Large Models (MLMs): Tailored for visual-language understanding.
MLMs support two distinct modes:
- Thinking mode: For step-by-step reasoning (e.g., Chain-of-Thought).
- Non-thinking mode: For direct answers.
Each model undergoes a multi-stage process:
- Supervised Fine-Tuning (SFT)
- Advanced preference optimization (e.g., Direct Preference Optimization (DPO), Unified Preference Optimization (UPO))
Supervised Fine-Tuning (SFT) for Language Models
The SFT process is illustrated below:
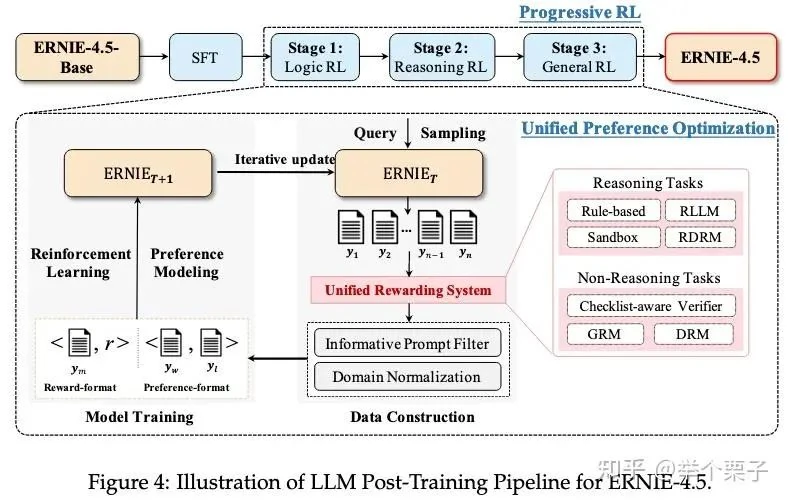
The SFT dataset spans ten domains, including science, mathematics, coding, logic, creative writing, and multilingual tasks. Data is categorized into reasoning (including Chain-of-Thought) and non-reasoning formats.
To boost creative problem-solving, multiple valid responses are provided for some reasoning queries, encouraging exploration during reinforcement learning (RL). Approximately 2.3 million samples were used, with each model trained for two epochs on average.
Reinforcement Learning (RL) for Language Models
For reasoning tasks, rule-based verifiers ensure correctness. To handle cases where rules don't generalize, three supplementary mechanisms are applied.
For non-reasoning tasks, the model undergoes progressive RL using Proximal Policy Optimization (PPO):
- Logic Foundation: Training on logic-heavy corpora for abstract reasoning.
- Abstract Enhancement: Training on mathematics and programming data to improve code generation and abstract skills.
- Generalization: Integrating previous skills for broad task performance.
Beyond standard PPO loss, Unified Preference Optimization (UPO)—a form of DPO—is used. This includes online-UPO and offline-UPO, depending on preference pair generation. This hybrid approach helps prevent reward hacking and stabilizes training.
The RL input dataset is filtered to remove samples with little learning value and those with uniform reward signals, retaining only discriminative data. Data is stratified by subject, and rewards are normalized per subset to prevent domain interference.
The process is visualized here:

Post-Training for Multimodal Models
High-quality, human-annotated image-caption pairs are rare. To address this, the team synthesized descriptions for real STEM images. This process uses a vision-language model (VLM) to generate captions, and a text-only reasoning model to solve the problem using only the caption. Only effective descriptions are retained.
A three-stage progressive training framework is used:
- Text-only Reasoning Fine-Tuning: The model is fine-tuned on math, science, and code datasets, showing emergent reasoning behaviors.
- Vision-Related Reasoning Data: Rejection sampling generates data for chart analysis and creative writing, enriching the SFT dataset.
- Fusion of Reasoning Modes: "Thinking" and "non-thinking" modes are fused by joint training with a special
<think>\n\n</think>tag (masked during backpropagation), and by transferring multimodal expert parameters (inspired by DeepSeek-V2).
Reward Mechanisms for Multimodal Reinforcement Learning
Inspired by verifier-based RL methods like RLVF, custom reward mechanisms are designed for each multimodal task:
Visual STEM
- Uses open-source datasets with ground-truth answers.
- Rewards are based on solution correctness.
- Multiple-choice questions are reformulated as open-ended for deeper reasoning.
Visual Puzzles
- A dataset of 10,000 visual puzzles is used.
- A two-LLM verification system checks for internal consistency and final solution correctness.
- Responses are accepted only if both verifiers approve.
UI2Code
- For HTML generation from UI images, a custom verifier assesses visual fidelity between the reference image and generated code.
During RL training, the final reward combines outputs from a pre-trained Bradley-Terry (BT) model and verifier-based rewards. Training uses Generalized Reward-based Policy Optimization (GRPO), enhanced with Direct Advantage Policy Optimization (DAPO) techniques.
Model Specifications
Pre-trained Models
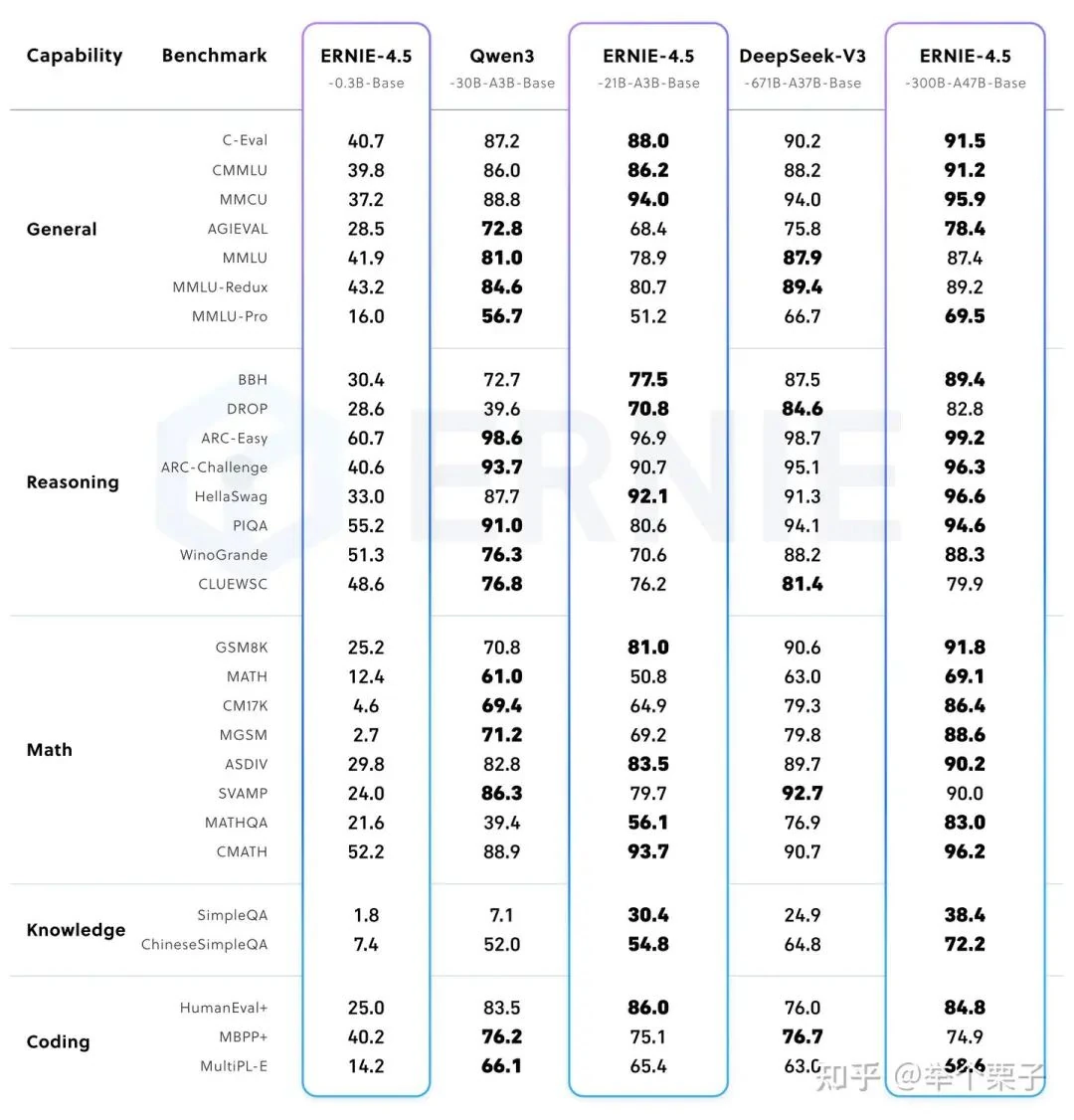
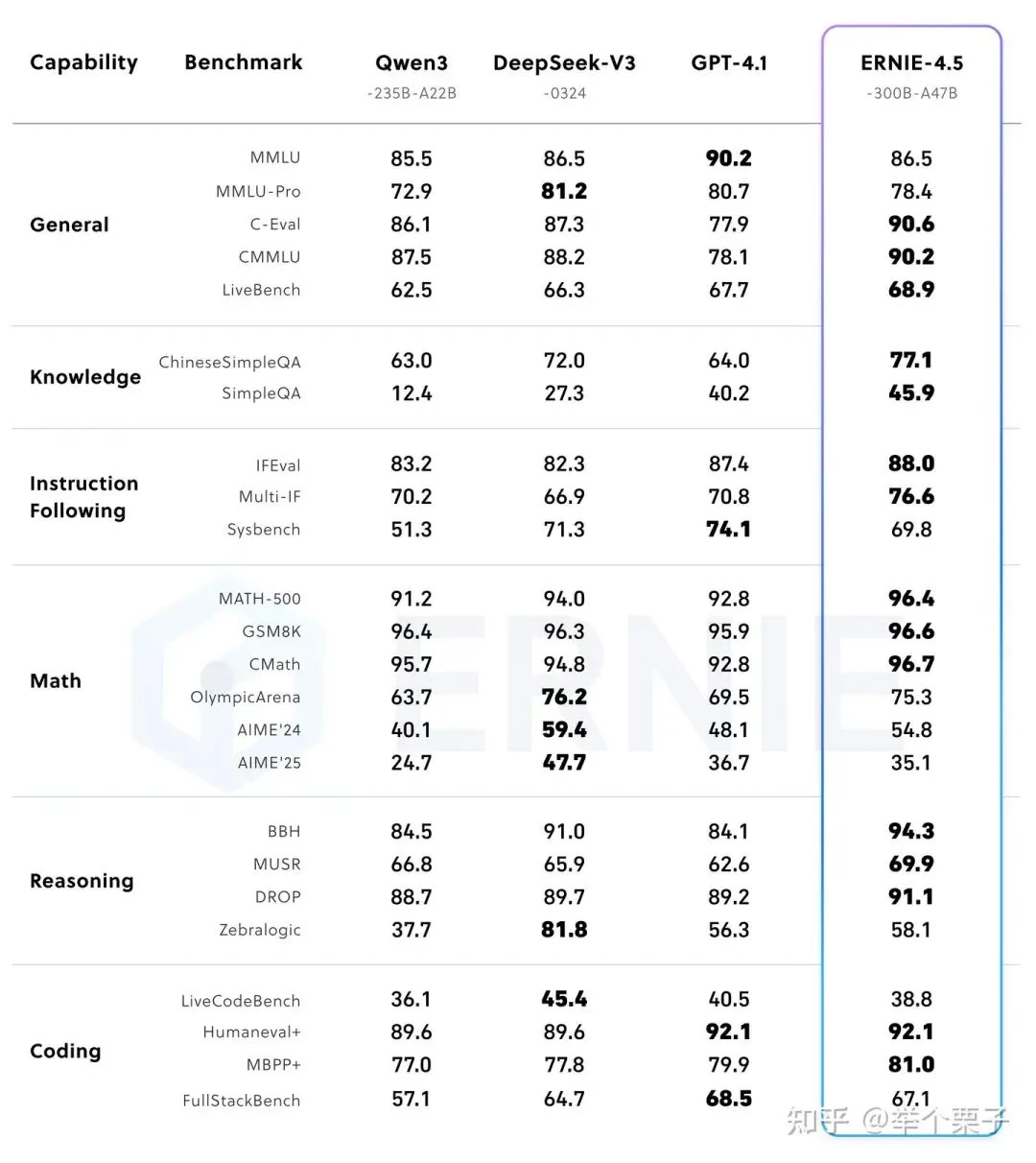
Post-trained 300B-A47B Model
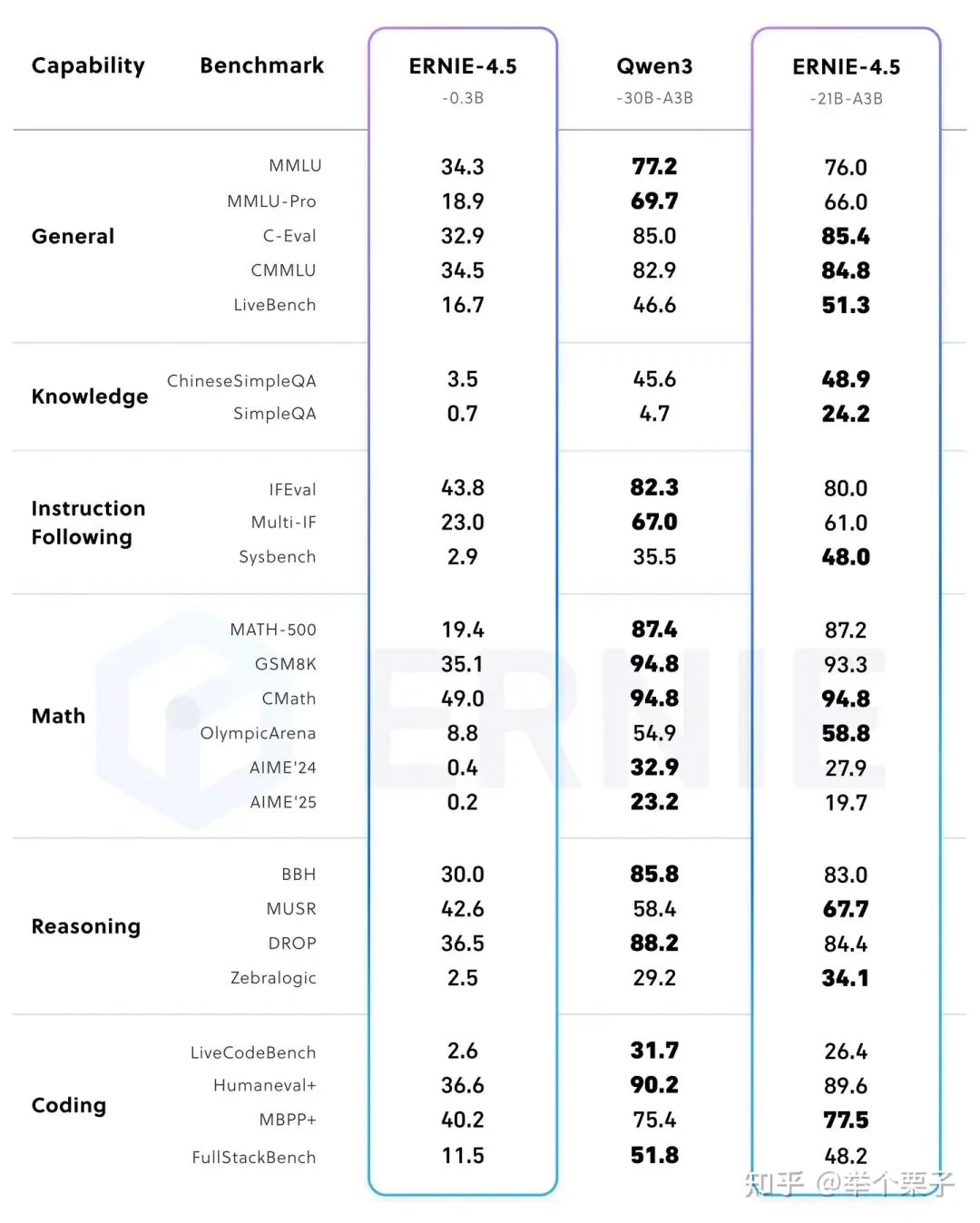
Post-trained 21B-A3B Model
Post-trained Multimodal Models (with "Thinking" Support)
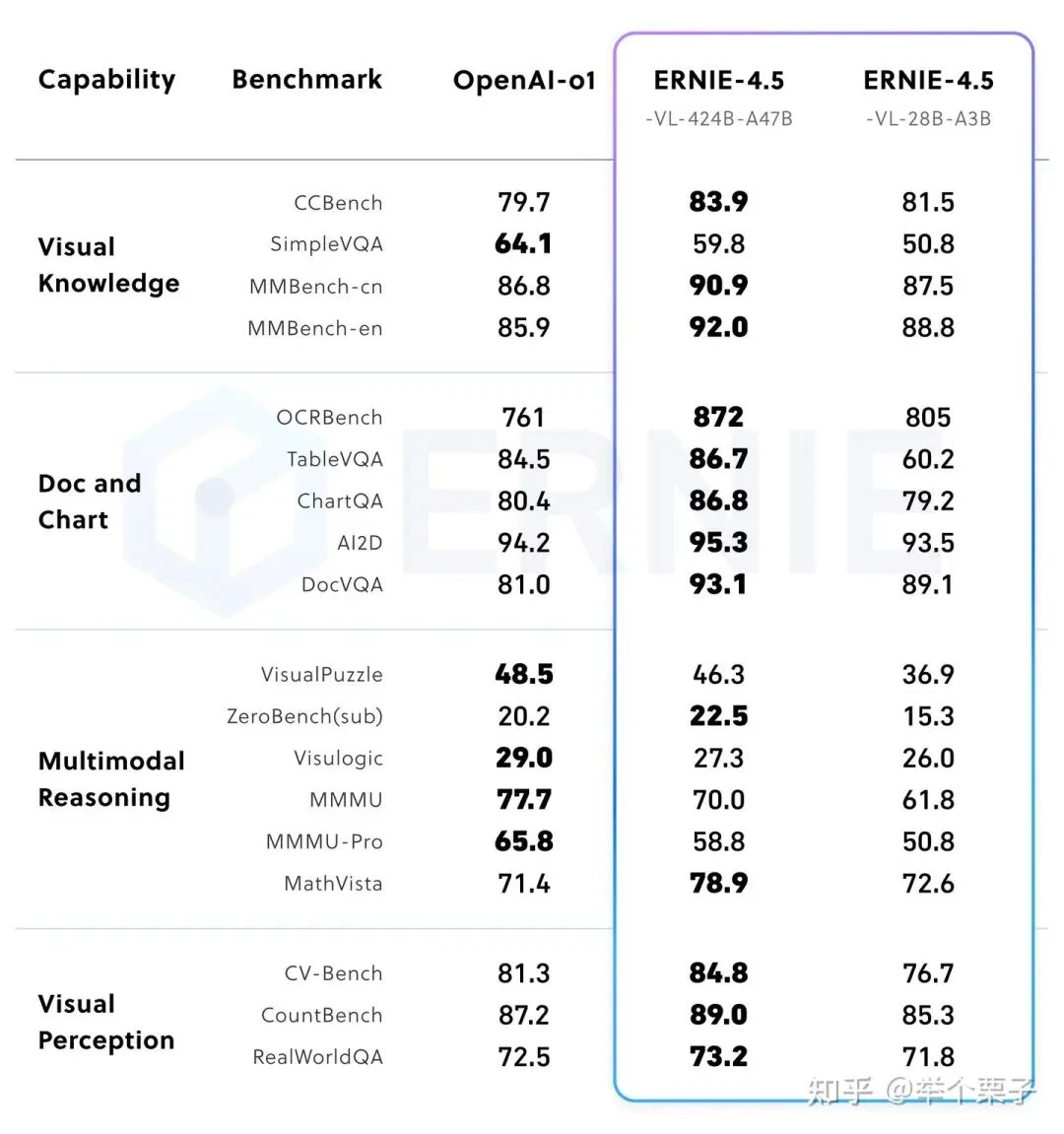
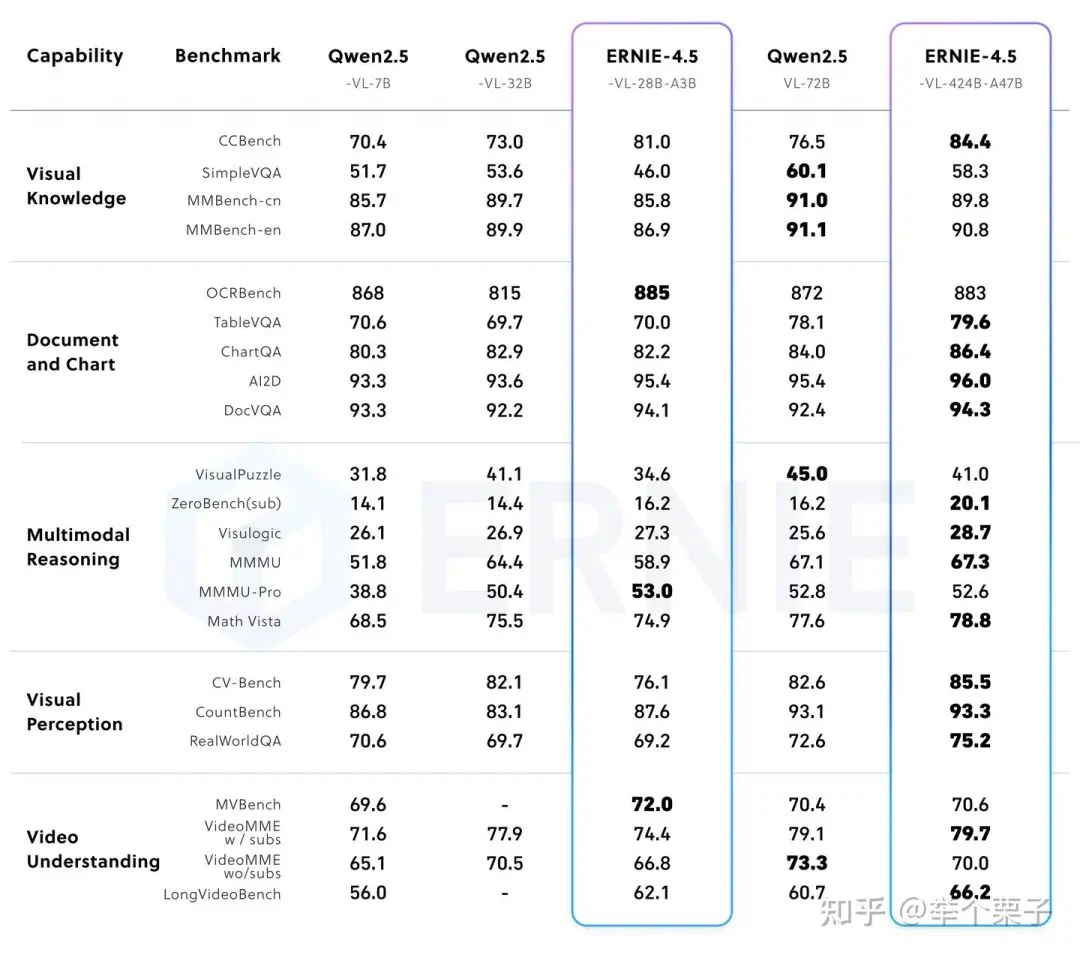
Conclusion
Baidu ERNIE 4.5 showcases rapid progress in multimodal large language models, blending innovative architectures, advanced fine-tuning, and robust reinforcement learning. By open-sourcing these models and sharing detailed methodologies, Baidu is advancing the AI research community. As multimodal AI evolves, ERNIE 4.5's approaches are set to influence the next generation of intelligent systems.