
Fine-tuning Large Language Models (LLMs) is the key to creating powerful, custom AI solutions. However, this process has traditionally been a complex, code-intensive task reserved for machine learning experts. LLaMA Factory is a powerful, user-friendly LLM fine-tuning toolkit that changes the game. It simplifies the entire process, empowering researchers and developers to customize hundreds of pre-trained models on their local machines—often without writing a single line of code.
This guide provides a complete walkthrough of how to use LLaMA Factory, from installation to exporting your first custom LLM.
What is LLaMA Factory?
LLaMA Factory is a comprehensive toolkit that offers:
- Broad Model Support: Fine-tune LLaMA, LLaVA, Mistral, Mixtral-MoE, Qwen, Yi, Gemma, and many more.
- Versatile Training Methods: Supports Pre-training, Instruction Fine-Tuning, Reward Model Training, PPO, DPO, and ORPO.
- Efficient Computation: Full-parameter, frozen, LoRA, and QLoRA (2, 3, 4, 5, 6, 8-bit) fine-tuning.
- Advanced Optimization: Integrates GaLore, BAdam, DoRA, LongLoRA, and other state-of-the-art algorithms.
- Built-in Acceleration: Out-of-the-box support for FlashAttention-2 and Unsloth to speed up LLM training.
- Flexible Inference: Use Transformers or vLLM for model inference.
- Experiment Monitoring: Seamlessly track your training with LlamaBoard, TensorBoard, Wandb, and MLflow.
Step 1: Install CUDA for LLM Training
Before you can fine-tune an LLM with LLaMA Factory, you must install the NVIDIA CUDA Toolkit. This platform gives the toolkit direct access to your GPU's processing power, which is essential for training.
CUDA Installation on Linux
-
Check Compatibility: First, confirm your GPU is CUDA-capable at https://developer.nvidia.com/cuda-gpus. Then, verify your Linux version is supported by running:
uname -m && cat /etc/*release -
Verify GCC: Ensure you have the GCC compiler by running:
gcc --version -
Download CUDA Toolkit: We recommend CUDA 12.1 to align with the project's PyTorch dependency. Download the correct installer for your system from the CUDA Toolkit Archive: https://developer.nvidia.com/cuda-toolkit-archive.


If you have an older CUDA version, uninstall it first. Try the official uninstaller:
sudo /usr/local/cuda-12.0/bin/cuda-uninstaller
If that fails, remove it manually:
sudo rm -rf /usr/local/cuda-12.0
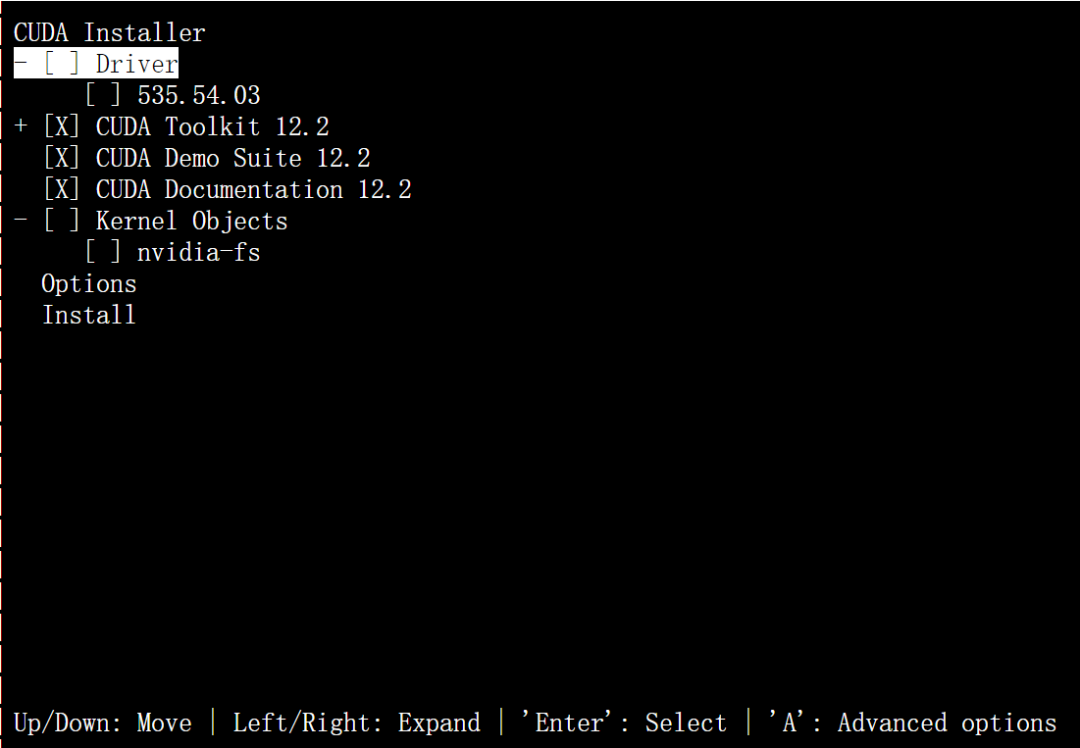
- Run the Installer: Execute the downloaded file and follow the prompts. For CUDA 12.1.1, the commands are:
wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda_12.1.1_530.30.02_linux.run
sudo sh cuda_12.1.1_530.30.02_linux.run
Important: During installation, uncheck the "Driver" option unless you are certain it's compatible with your GPU to avoid common issues.
-
Verify Installation: Once finished, run:
nvcc -VA successful installation will display the CUDA version.
CUDA Installation on Windows
-
Check OS Version: Go to Settings > About and check your Windows version against the supported list (e.g., Windows 11 23H2, Windows 10 22H2).
-
Download and Install: Select the corresponding CUDA 12.1 version from the NVIDIA developer website, download it, and run the installer.
-
Verify Installation: Open Command Prompt (cmd) and run:
nvcc -VIf the command returns the version number, your CUDA installation is complete. If not, you may need to add the CUDA path to your system's environment variables.
Step 2: Install LLaMA Factory
With CUDA ready, you can now install the LLaMA Factory toolkit. Ensure you have the following prerequisites:
- Python 3.10
- PyTorch 2.1.2
- CUDA 12.1
Run these commands to clone the repository and install dependencies:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .[torch,deepspeed]
To verify the installation, run:
llamafactory-cli version


Enabling QLoRA for Efficient Training
To use Quantized LoRA (QLoRA) on Windows for memory-efficient fine-tuning, install a compatible bitsandbytes wheel:
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
Activating FlashAttention-2 for Speed
To accelerate training with FlashAttention-2 on Windows, install the appropriate flash-attention wheel for your CUDA version.
Installing Optional Dependencies
LLaMA Factory is modular. Install only what you need for your specific LLM fine-tuning task:
# For Intel Arc GPUs
pip install -e .[intel]
# For Ascend NPU devices
pip install -e .[ascend]
# For exporting to GGUF format
pip install -e .[gguf]
# For exporting to AWQ format
pip install -e .[awq]
# For all dependencies
pip install -e .[all]
Step 3: Fine-Tune Your First LLM with the WebUI
Now for the exciting part: using the LLaMA Factory WebUI for code-free fine-tuning. Launch it with this command:
llamafactory-cli webui
The WebUI is organized into four tabs: Train, Evaluate & Predict, Chat, and Export.
How to Start Training a Model
To start a fine-tuning job, follow these steps in the Train tab:
- Select Model: Choose a base model name and path.
- Choose Method: Select the training stage (e.g., SFT) and fine-tuning method (e.g., LoRA).
- Load Dataset: Pick one or more training datasets.
- Set Hyperparameters: Configure the learning rate, number of epochs, etc.
- Configure Parameters: Adjust fine-tuning settings as needed.
- Define Output: Specify the output directory.
- Begin Training: Click Start to launch the process.
Note on Custom Datasets: To use your own data for a custom LLM, add its description to the
data/data_info.jsonfile and ensure your dataset file follows the expected format.
How to Evaluate and Predict with Your Model
Once your model is trained, go to the Evaluate & Predict tab. Here, you can benchmark its performance on a dataset by providing the base Model and your trained Adapter.
How to Chat with Your Fine-Tuned LLM
The Chat tab lets you interact with your custom LLM directly. Load your Model and Adapter, choose an Inference engine, and start a conversation to test its capabilities.
How to Export Your Custom LLM for Deployment
When you are satisfied with your model, use the Export tab to package it for deployment. Set the base Model, your Adapter, Max shard size, and any quantization settings, then click Export.
Why Use LLaMA Factory for LLM Fine-Tuning?
LLaMA Factory demystifies the art of fine-tuning, packaging a suite of sophisticated tools into an accessible web interface. By handling the complexities of training, evaluation, and deployment, it allows you to focus on what truly matters: experimenting with and building powerful, customized AI models. Whether you're a seasoned researcher or just starting your journey, LLaMA Factory provides a robust and efficient platform to fine-tune any LLM and bring your ideas to life.