Editor's Note: As organizations increasingly embrace remote work, a significant challenge emerges: maintaining a cohesive company culture. This shift not only affects collaboration but also employee engagement and retention. How can leaders foster a sense of belonging and connection in a digital-first environment? As we navigate this evolving landscape, it’s crucial to explore innovative strategies that bridge the gap between virtual interactions and authentic relationships within teams.
What is Context Engineering for LLMs?
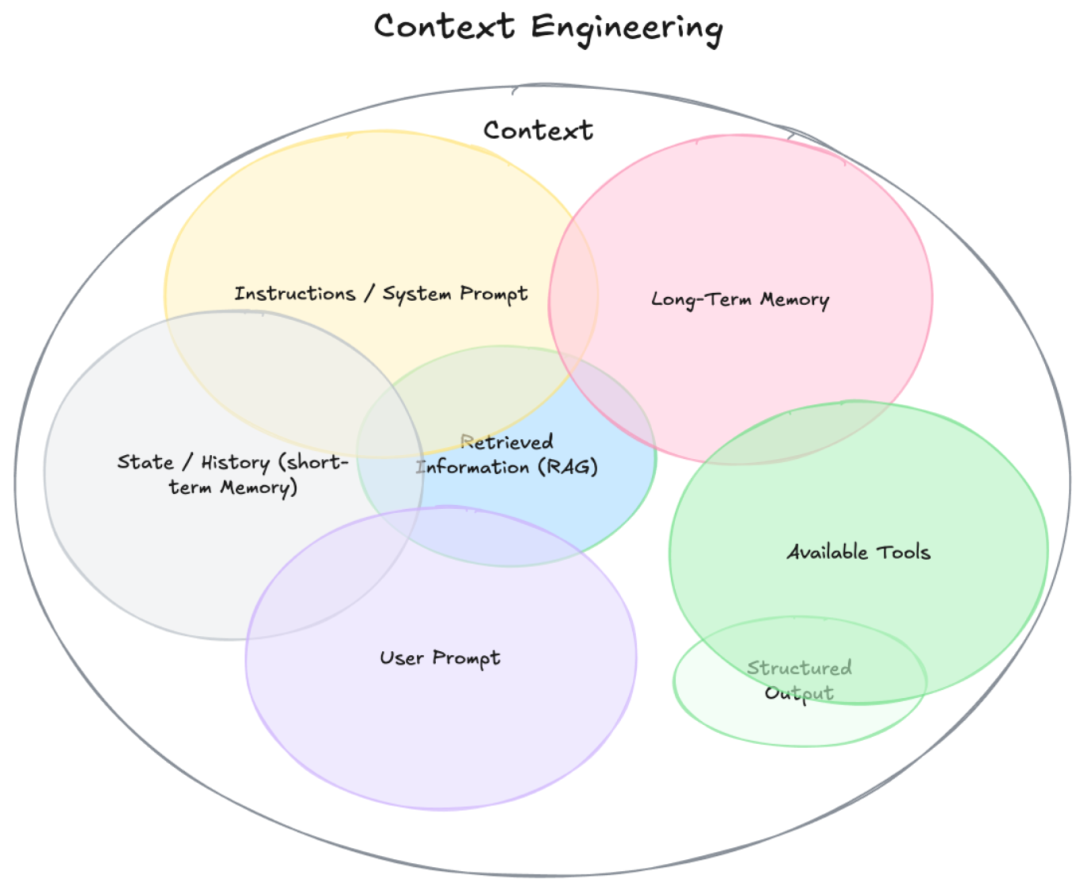
Context Engineering is the science of strategically designing and optimizing the information, or context, provided to a Large Language Model (LLM) to improve its performance. It bridges the gap between an LLM's raw potential and the demand for high-quality, reliable outputs.
Think of it as preparing a comprehensive briefing for a brilliant but literal-minded expert. By carefully curating the input, Context Engineering for LLMs aims to unlock the model's reasoning capabilities, dramatically improving the quality and relevance of its generated responses and overall accuracy.
The 3 Core Stages of Context Engineering in RAG
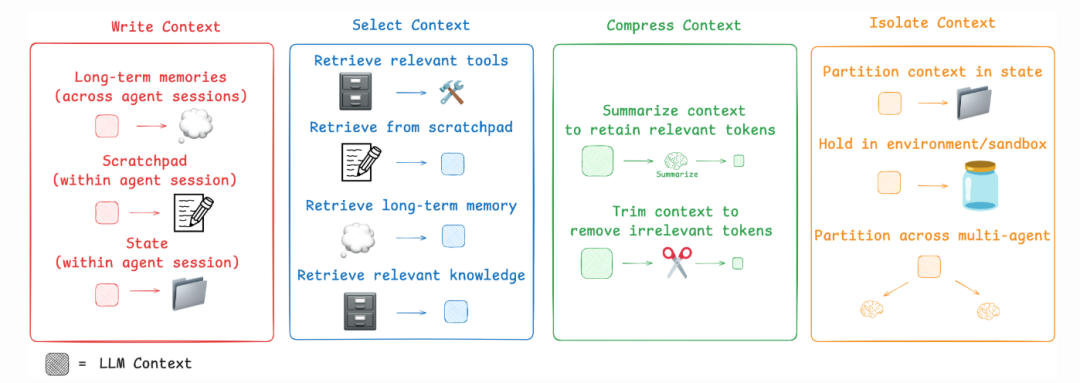
At its core, the process is structured around three key stages, which are fundamental to how Retrieval-Augmented Generation (RAG) systems operate. Mastering these stages is crucial for improving LLM outputs.
1. Pre-retrieval Data Preparation
This foundational stage focuses on the knowledge base. The primary goal is to ensure all source data is clean, accurate, and structured for optimal machine comprehension. Proper data preparation prevents the "garbage in, garbage out" problem and is the first step toward reliable LLM outputs.
2. In-retrieval Optimization
Operating at the query and search layer, this stage refines the mechanisms for identifying and retrieving the most relevant information chunks from the knowledge base in response to a user's query. Effective in-retrieval optimization ensures the right data is found quickly and efficiently.
3. Pre-generation Context Construction
This final stage occurs at the prompt level and is a key part of prompt engineering. It involves assembling the retrieved information into a coherent, optimized context that is then passed to the LLM. This step is critical for guiding the model's final output and ensuring it has everything it needs to generate a precise answer.
Why Context Engineering Matters for LLM Outputs
By meticulously managing each of these stages, Context Engineering ensures the information an LLM receives is not merely relevant, but also concise, coherent, and structured for effective processing. This disciplined approach empowers the model to generate answers that are significantly more accurate, dependable, and aligned with user intent, making it a vital practice for any serious AI application.
Key Takeaways
• Context Engineering optimizes input to enhance Large Language Model (LLM) performance.
• It bridges the gap between LLM potential and the need for reliable outputs.
• Implementing RAG systems involves three key stages for improved AI-generated results.