Training a 671B Parameter LLM with Reinforcement Learning: Technical Challenges and Solutions
Over the past two months, I have been deeply involved in training a 671-billion-parameter large language model (LLM) using Reinforcement Learning (RL) as part of the verl team. This article summarizes the key technical challenges encountered during large language model training at this scale and the solutions developed, providing actionable insights for practitioners working on large-scale model training and deployment. The achievements described are the result of collaborative efforts by the verl team and the broader open-source community.
Getting Started: The Scale of 671B Parameter LLM Training
When I began my internship with the verl team, my lead tasked me with supporting the training of a colossal 671B parameter LLM using Reinforcement Learning. Despite my limited prior experience with RL, I was excited to contribute to such a large-scale project. From the outset, the community asked, "When will verl support 671B model training?" The answer: we've been working intensively, facing challenges unique to training LLMs at this scale with RL.
Heterogeneous Frameworks in Large Language Model Training
Training a 671B parameter LLM with RL requires seamless integration between inference and training frameworks. The inference framework generates rollouts from prompts, while the training framework manages log probability calculations and gradient updates. This dual requirement increases engineering complexity and system design challenges.
Leading training frameworks include Fully Sharded Data Parallel (FSDP) and Megatron, while inference is typically handled by vLLM and SGLang. For 671B scale models, framework selection is critical, considering communication efficiency, memory management, and parallelism strategies.
- FSDP: Offers sharded data parallelism but can face communication bottlenecks and memory limitations at extreme scales.
- Megatron: Provides mature model parallelism and integrates with NVIDIA's TransformerEngine, making it optimal for 671B LLM training.
- vLLM and SGLang: Robust, scalable inference solutions, with verl's unified parameter interface enabling flexible switching.
Resource Constraints and Memory Optimization for 671B LLMs
Training a 671B parameter LLM is resource-intensive. Most developers lack access to thousands of GPUs, so creative memory optimization is essential across both training and inference.
Training-Side Memory Optimization
verl's development began with Megatron 0.4, using custom patches. Upgrading to Megatron 0.11, we rebuilt support for offloading parameters, gradients, and optimizer states. Since Megatron lacked native offloading, we engineered our own solution. Memory fragmentation from the absence of parameter flattening was mitigated by capping fragment size via environment variables. Disabling the cache pool could have helped, but vLLM 0.8.2 did not support this, highlighting the need for synergy between RL training and inference frameworks.
Inference-Side Memory Management
The main memory consumers during inference are model parameters and the KV cache. Early vLLM versions used "wake/sleep" operations, but improper timing could cause Out-of-Memory (OOM) errors. For example, the wakeup operation in vLLM 0.8.2 loaded both model parameters and the KV cache at once, even when the cache was not needed, leading to inefficient memory use.
vLLM addressed this with a staged wakeup strategy in version 0.8.3, which we quickly integrated into verl.
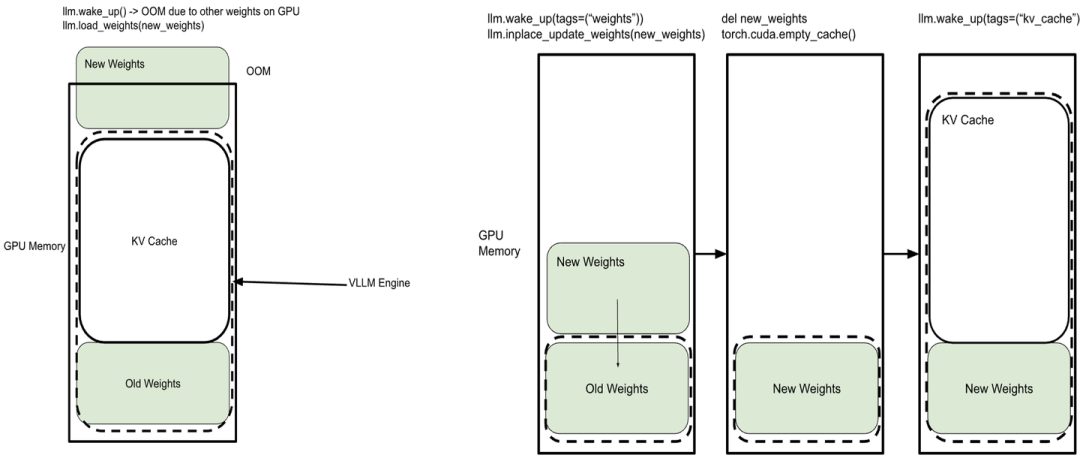
Ultimately, verl's development challenges extend beyond its own codebase, requiring upstream (training) and downstream (inference) frameworks to provide APIs and hooks for effective resource management.
Model Weight Conversion Between Frameworks
Checkpoint Loading and Storage
Model weight conversion is a critical aspect of large language model training. verl initiates model loading from the training framework. FSDP-based frameworks can load Hugging Face models directly, but Megatron requires models in its specific structure. For the 671B model, this means converting the public Hugging Face checkpoint into a Megatron-compatible format.
Megatron offers two checkpoint formats:
- Legacy format: Hard-codes the model's structure to a specific parallelism strategy.
- dist-ckpt format: Decouples save-time and load-time parallelism strategies, offering greater flexibility.
The workflow involves converting the Hugging Face model to the legacy format, then to dist-ckpt, a process requiring significant GPU resources but enabling flexible model saving.
Inter-Framework Weight Conversion
Weight conversion between Megatron and vLLM/SGLang is essential for the RL training pipeline. These frameworks use different naming conventions and tensor structures. For example, Megatron may fuse Q, K, and V tensors for efficiency, while inference frameworks expect them as separate tensors. We reconstruct the full, unsharded tensor on each GPU in the training cluster and pass it to the inference framework for partitioning. This minimizes the complexity of aligning parallelism strategies.
To reduce memory overhead, we use a generator-based, lazy-loading approach for tensor transfer, ensuring peak memory usage never exceeds the size of a single tensor.
Model Accuracy Alignment Across Frameworks
Ensuring model accuracy requires careful alignment between training and inference frameworks. Even with a theoretically correct RL algorithm, subtle misalignments or human error can cause discrepancies. Accuracy alignment checks involve running the same algorithm on a reference framework and comparing outputs—a time-consuming process, especially for Mixture-of-Experts (MoE) models lacking suitable reference implementations.
Optimizing Model Efficiency for 671B LLMs
Robust operation is only the first step; optimizing training efficiency is essential for practical deployment. For MoE models like DeepSeek, this means supporting expert parallelism and various parallelism strategies across both training and inference. The optimal configuration depends on hardware and workload, requiring ongoing experimentation and tuning.
Dependencies and Coordination with Upstream and Downstream Frameworks
verl acts as the integration layer between training and inference frameworks. When issues arise due to upstream or downstream dependencies, coordination with external development teams is often necessary. For example:
- SGLang's GPU memory balance check sometimes failed due to interactions with verl, RL, and Ray, requiring direct collaboration with the SGLang team for a workaround.
- vLLM's MoE model weight loading had a bug related to frequent weight switching, which we addressed by patching and working with the vLLM team for a permanent fix.
Conclusion: Advancing Large Language Model Training
My internship with the verl team provided invaluable experience in large-scale model training and system integration. The collaborative environment and open-source community support were instrumental in overcoming the technical challenges described above. Training a 671B parameter LLM is a technical milestone and a testament to the importance of robust, open-source solutions for the AI community. The verl team's ongoing mission is to advance large language model training, ensuring scalability, efficiency, and accessibility for future developments.