Editor's Note: As the digital landscape evolves, the challenge of data privacy continues to intensify, forcing companies to rethink their strategies. With consumers increasingly aware of their rights, how can businesses balance innovation with the imperative to protect personal information? This critical juncture not only shapes consumer trust but also defines the future of digital engagement, urging us to consider: in a world driven by data, what does ethical responsibility look like?
The engine of any reinforcement learning (RL) system is its reward signal. An AI model lacks an innate sense of 'right' or 'wrong'; it learns by interpreting AI model feedback. This signal guides the model's policy, gradually steering its outputs toward a desired goal. Designing this reward function is a critical task in LLM training—it's not just about defining a 'good answer,' but about teaching the model how to think.
In our previous analysis of DeepSeek-Coder-V2, we outlined its Group Relative Policy Optimization (GRPO) framework. Now, we turn to the heart of that system: the reward model. Instead of relying on another large language model (LLM) as an opaque judge, the DeepSeek team engineered a multi-faceted, controllable, and extensible reward system from scratch.
In this deep dive, we'll dissect the core reward functions that power DeepSeek-Coder-V2. We'll explore how they work in concert to shape the model's behavior and discuss how this modular approach can be generalized beyond mathematical reasoning to other complex domains.
The 5 Core Reward Functions in DeepSeek-Coder-V2
As we touched on in our GRPO discussion, the model's outputs are scrutinized from five distinct angles. Think of these as five different judges, each with their own specialty, who collaborate to score the model's performance. These are the core components of the DeepSeek-Coder-V2 reward model.
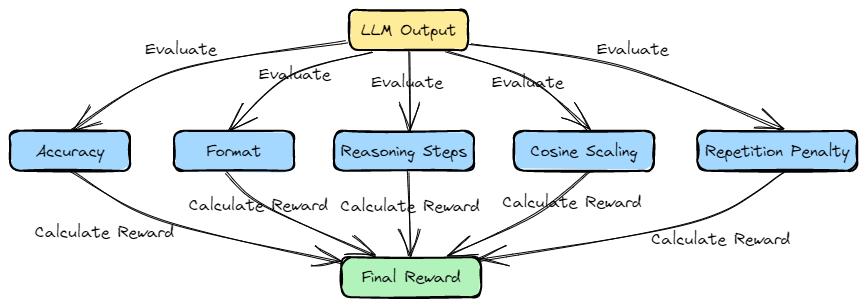
1. Accuracy Reward: Verifying Mathematical Equivalence
The Accuracy Reward is the most fundamental of the five. Its mission is simple: is the model's final answer mathematically correct? This reward function provides a clear, objective signal for the reinforcement learning process.
The scoring is binary: a perfect 1.0 for a correct answer and a 0.0 for an incorrect one. To prevent unfairly penalizing the model for an issue with the reference data, a neutral score of 0.5 is assigned if the ground truth answer itself is malformed.
This evaluation is more than a simple text match. Mathematical expressions like x/2 and 0.5x are equivalent but not identical strings. To account for this, the system uses powerful parsing tools like latex2sympy2 and math_verify. These libraries convert both the model's output and the reference answer into structured mathematical objects, allowing for a check of true mathematical equivalence rather than string identity.
2. Format Reward: Enforcing Structured Outputs
A correct answer is of little use if it's buried in a wall of text. The Format Reward acts as a style guide, ensuring the model presents its response in a clean, predictable structure.
Specifically, the model was instructed to wrap its reasoning process in <think> tags and the final answer in <answer> tags. This reward function's sole job is to verify compliance: if the model follows the rules, it gets a reward; if not, it's penalized. This simple check is crucial for creating parsable, machine-readable outputs for downstream applications.
3. Reasoning Steps Reward: Encouraging Transparency
Getting the right answer is only half the battle; understanding how the model got there is equally important. The Reasoning Steps Reward encourages the model to 'show its work,' fostering transparency and trust. A black-box model that simply provides correct answers is inherently less reliable than one that can articulate its problem-solving journey.
Automating the evaluation of a 'clear reasoning process' is a complex challenge. The system relies on a set of heuristics and pattern-matching techniques to approximate this. It scans for key indicators such as:
- Transitional Keywords: The presence of words like 'Step,' 'First,' 'Next,' 'Therefore,' or 'In conclusion' that signal a logical progression.
- Structural Cues: Organization of the reasoning with numbered lists (1., 2., 3.), bullet points, or other clear formatting.
- Logical Cohesion Proxies: While true 'logical flow' is difficult to quantify algorithmically, the system checks for coherent sentence structures that build upon one another.
- Formula and Theorem Mentions: Proper citation of the mathematical formulas or theorems used in the solution.
The more of these elements a response contains, the higher its reasoning score. This multi-faceted approach doesn't just push the model toward correctness; it cultivates the kind of interpretability that is essential for human validation and end-user trust.
4. Cosine Scaled Reward: Balancing Accuracy and Brevity
The Cosine Scaled Reward introduces a sophisticated trade-off between correctness and conciseness, governed by a simple principle: the value of verbosity depends on whether the answer is right or wrong.
- When the Answer is Correct: Brevity is a virtue. A short, direct, and correct answer is ideal and receives the highest reward. A correct but rambling response is still valuable, but its score is scaled down based on its length.
- When the Answer is Incorrect: The logic is inverted. A short, wrong answer suggests a lack of effort and is heavily penalized. A longer, incorrect answer, however, might contain a partially correct line of reasoning. It's still wrong, but it represents a more 'thoughtful' failure, so the penalty is less severe.
By using a cosine scaling function, this reward mechanism elegantly balances accuracy with efficiency, incentivizing the model to be both correct and concise while showing leniency toward well-intentioned but flawed attempts.
5. Repetition Penalty Reward: Promoting Originality
AI models can sometimes get stuck in repetitive loops during generation. The Repetition Penalty Reward is a reward function designed to prevent this behavior by discouraging redundant content.
This function works by penalizing repeated n-grams (sequences of words). By doing so, it pushes the model to explore more diverse phrasing and reasoning paths, dramatically improving the quality and readability of its output.
Modular Reward System: A Flexible and Extensible Design
A powerful system requires flexibility. Instead of hardcoding these reward functions, the DeepSeek team implemented a modular, configuration-driven architecture. This approach decouples the reward logic from the core training loop, enabling rapid experimentation and adaptation.
This modular reward system is built on a few key components:
- Centralized Configuration: A primary configuration class,
GRPOScriptArguments, acts as a control panel. From here, developers can enable or disable specific reward functions, adjust their weights, and fine-tune parameters without modifying the underlying training code. - Dynamic Assembly: A utility function,
get_reward_functions, reads this configuration at runtime and dynamically assembles the list of active reward functions for a given training session.
This modularity means that introducing a new reward function is as simple as defining its logic and adding an option to the configuration file. This keeps the codebase clean, maintainable, and highly extensible—a crucial feature for a rapidly evolving field like LLM development.
How a Multi-Faceted Reward Model Shapes AI
In this article, we've unpacked the five core reward functions that form the backbone of DeepSeek-Coder-V2's reinforcement learning process. By combining rewards for accuracy, format, reasoning, conciseness, and originality, this system defines a 'good answer' in a holistic way, providing a stable and multi-faceted evaluation standard to guide the model's learning.
This modular approach to reward engineering represents a critical strategic layer in modern LLM development. By moving beyond a single, monolithic judge, systems like DeepSeek-Coder-V2 can cultivate more nuanced, reliable, and transparent AI behavior.
In our next installment, we will explore how the GRPO training loop consumes these signals to optimize the model's policy, translating this carefully designed feedback into higher-quality code and reasoning.
Key Takeaways
• DeepSeek-Coder-V2 utilizes five core reward functions to enhance AI learning.
• The modular reward model focuses on accuracy, reasoning, and output format.
• Effective reward function design is crucial for guiding AI behavior and decision-making.