Editor's Note: As businesses increasingly embrace remote work, a significant challenge emerges: maintaining team cohesion and culture in a virtual environment. This shift not only redefines workplace dynamics but also raises questions about employee engagement and productivity. How can organizations foster a sense of belonging and collaboration among dispersed teams, ensuring that innovation and morale thrive despite physical distance? The answers may reshape the future of work as we know it.
In the rapidly evolving landscape of large language models (LLMs), performance is no longer a simple function of size. The key differentiator has shifted from parameter count to a model's capacity for sophisticated LLM fine-tuning, particularly for 'higher-order intelligence' tasks like complex reasoning and decision-making.
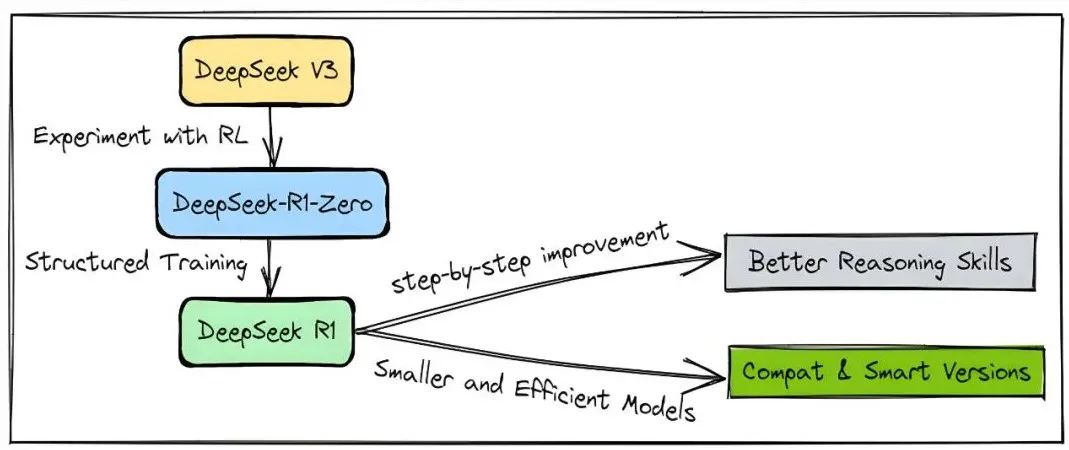
DeepSeek R1 exemplifies this shift. Rather than being built from the ground up, it was meticulously honed from the DeepSeek V3 base model using a suite of reinforcement learning techniques to sharpen its reasoning and cognitive abilities. The key innovation was an algorithm introduced during its 'R1 Zero' phase: Group Relative Policy Optimization (GRPO). This efficient, lightweight training approach is ideal for study and replication.
In this series, we will construct a complete reinforcement learning (RL) training pipeline from scratch. We will use the nimble Qwen2.5–0.5B model as our foundation to replicate the core technical journey behind DeepSeek R1.
This first installment lays the groundwork for our LLM training project. We will cover the development environment, dataset preparation, and the overall training architecture. By the end, you will have a solid launchpad for our deep dive into the mechanics of reinforcement learning.
Setting Up Your RL Development Environment
Our implementation relies on a standard AI development stack. We will use PyTorch for tensor computation and leverage Hugging Face's Transformers and Datasets libraries for model and data handling. These tools form the foundation of our reinforcement learning pipeline.
With our environment defined, we can proceed to preparing the data that will teach our model to reason.
Preparing Reasoning Datasets for LLM Fine-Tuning
At its core, this project aims to sharpen an LLM's reasoning skills. To align with the original research, we have selected two powerful, open-source reasoning datasets suitable for this task:
- NuminaMath-TIR dataset: A collection of approximately 70,000 math problems. Each sample features a
messagesfield that showcases the Chain-of-Thought (COT) reasoning process. - Bespoke-Stratos-17k: A high-quality reasoning dataset derived from the SFT distillation data released by the DeepSeek-R1 team, containing around 17,000 questions.
We can inspect the structure of a sample from the dataset with the following code:
While these are our chosen datasets, the framework is adaptable. Any dataset that provides problems with detailed, step-by-step solutions is suitable for this type of LLM fine-tuning for reasoning.
Understanding the DeepSeek R1 Reinforcement Learning Framework
To understand our approach, we must first examine the strategy behind DeepSeek R1. The model is an evolution of its predecessor, DeepSeek V3, specifically enhanced for expert-level reasoning. The development team employed Reinforcement Learning (RL) to teach the model how to 'think'—to analyze logic, construct coherent arguments, and deliver trustworthy answers.
This was not a simple tune-up but a fundamental reshaping of the model's cognitive architecture through an iterative, multi-stage training process.
How the Core Reinforcement Learning Loop Works for LLMs
At the heart of this process is a feedback loop. Let's visualize how the components in an LLM training context interact:
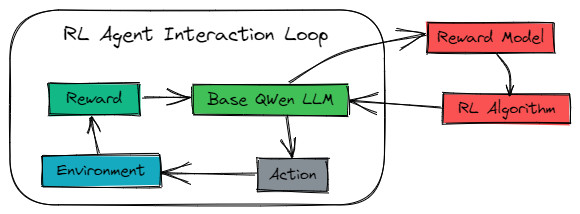
In this paradigm, our LLM acts as the agent (or 'policy model'). It receives a prompt (the state) and takes an action by generating a response. This response typically includes both a reasoning chain (e.g., within <think> tags) and a final answer (within <answer> tags).
The generated response is passed to the environment, which in our case is a computational reward mechanism. This environment evaluates the quality of the model's output against ground truth and returns a numerical reward.
The policy model uses this reward signal to update its internal parameters, reinforcing strategies that lead to higher rewards. This cycle of 'generate → evaluate → reward → update' is the engine that drives the model toward improved reasoning.
What is Group Relative Policy Optimization (GRPO)?
Traditional RL pipelines often employ a separate 'Critic' model to evaluate the agent's actions. However, this Critic can be as large as the policy model itself, effectively doubling computational costs.
DeepSeek's team bypassed this bottleneck with a more efficient solution: Group Relative Policy Optimization (GRPO).
Instead of using a dedicated Critic, GRPO instructs the policy model to generate multiple candidate responses for a single prompt. These responses are then scored and ranked against each other by the reward function. The model is updated based on this internal comparison, learning to favor the characteristics of the higher-scoring outputs. This ranking-based optimization is computationally efficient and highly effective for large-scale LLM training.
Our GRPO Implementation Plan for LLM Training
We will replicate this process using Qwen/Qwen2.5-0.5B-Instruct as our policy model. While the original DeepSeek-V3 is a heavyweight model, our choice of a ~0.9GB model makes this project accessible. If your hardware permits, a larger version can be substituted.
Here is a flowchart of our GRPO training loop:
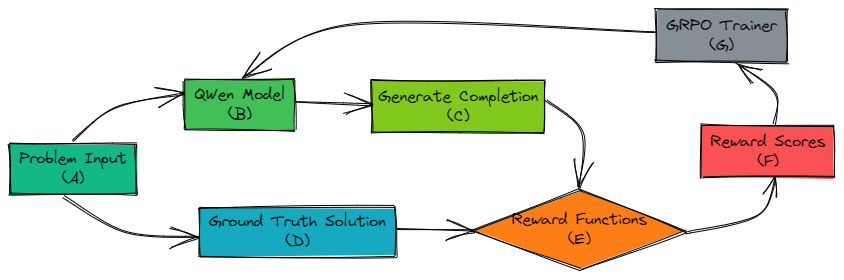
Let's trace a single training iteration:
- Generate Multiple Responses: A single prompt (A) is fed into our Qwen policy model (B), which generates several candidate responses (C).
- Score and Rank: Each response is evaluated by our reward functions (E) by comparing it to the ground truth data (D). This produces a reward score (F) for each candidate.
- Optimize with GRPO: The set of responses and their scores are passed to the GRPO trainer (G), which calculates policy gradients and updates the Qwen model's (B) parameters.
- Repeat: The updated model proceeds to the next batch of data, continuously refining its ability to produce high-quality, logical responses.
Preprocessing Data for the GRPO Training Loop
Before we can kick off the GRPO training loop, there's one critical prep step: data formatting. We need to transform our raw math problems into a structured, conversational format that the model can easily parse. This is essential for our reward mechanism to accurately evaluate the model's output later.
1. Define a "Thinking" Prompt Template
We will adopt the prompt template used for R1 Zero, which assigns the model the role of an "intelligent assistant that thinks before answering." The key is to structurally separate the reasoning process from the final answer by wrapping them in <think> and <answer> tags. This structure is critical as it allows our reward function to evaluate and score each component independently.
2. Convert to Dialogue Format
The original dataset contains only a problem statement. We will wrap it in a standard conversational structure, using a system prompt for the first turn and the problem statement as the user's query.
3. Load and Preprocess the Dataset
Finally, we use the datasets library to load our math dataset and apply the format conversion. With that, our training data is converted from its raw form into a structured, conversational format, setting a solid foundation for reinforcement learning.
And there you have it! In this first article, we've laid the complete groundwork for replicating DeepSeek R1's reinforcement learning success. We've mapped out the technical architecture, chosen our base model, prepared the reasoning datasets, and outlined the GRPO training framework. You now have the blueprint for the entire pipeline.
In the next post, we'll dive into the most critical component of this process: designing and implementing the reward function. This is where we define what 'good' reasoning looks like and steer the model toward our goal. We will deconstruct DeepSeek's multi-faceted scoring system and show you how to implement it from scratch. Stay tuned.
Key Takeaways
• Understand the importance of fine-tuning for advanced reasoning in LLMs.
• Utilize reinforcement learning techniques to enhance model cognitive abilities effectively.
• Follow the guide to build a GRPO-based reinforcement learning pipeline from scratch.