Editor's Note: As the landscape of remote work continues to evolve, a key challenge emerges: maintaining employee engagement and connection in a virtual environment. This shift not only impacts productivity but also team dynamics and company culture. How can organizations foster a sense of belonging and collaboration among remote teams, ensuring that innovation and morale thrive despite physical distances? Embracing creative solutions may be essential for future success in this new normal.
Knowledge Distillation & Model Temperature Explained
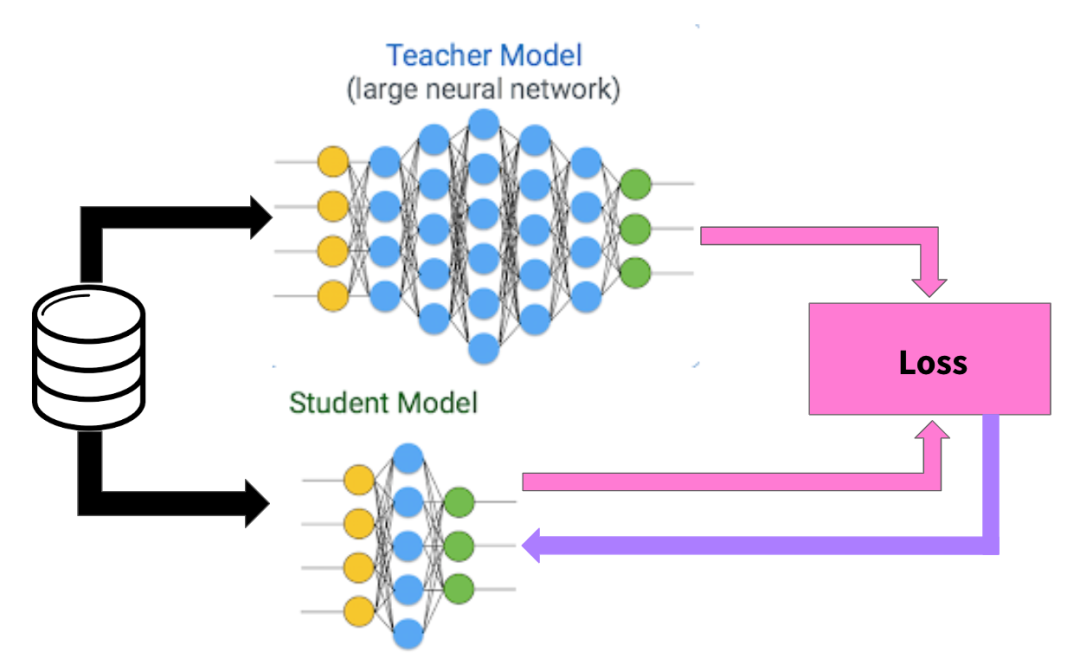
Large Language Models (LLMs) have revolutionized AI, but their size and cost create significant challenges for real-world LLM deployment. How can we capture the power of a massive model in a smaller, more efficient package? The answer is knowledge distillation, a powerful AI model compression technique that starts with a simple but crucial parameter: model temperature.
What is Model Temperature in AI?
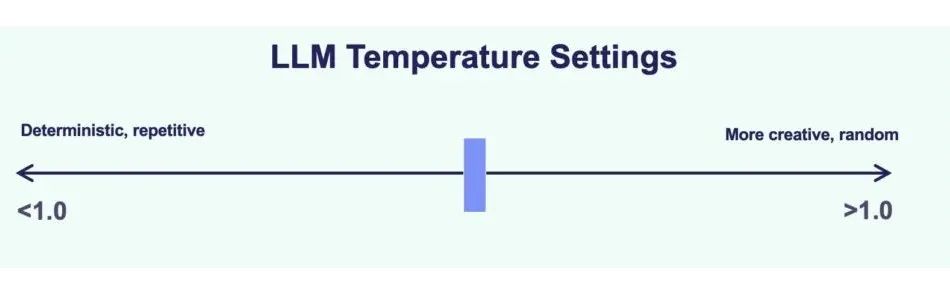
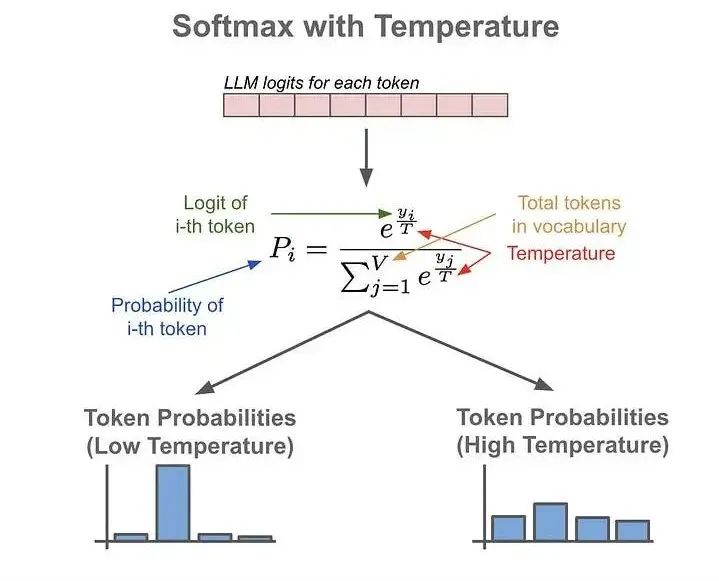
In Large Language Models (LLMs), model temperature is a parameter that controls the randomness and creativity of the output. Think of it as a dial for the model's confidence.
- Low Temperature (e.g., 0.2): This makes the model more deterministic and focused. It will almost always choose the most statistically likely word, resulting in predictable and precise answers. This is like a by-the-book expert giving a single, correct answer.
- High Temperature (e.g., 0.8): This increases randomness, making the model more creative. It raises the probability of sampling less common words, allowing it to explore a wider range of expressions. This is like a creative mentor showing you a landscape of possibilities.
For knowledge distillation, a higher temperature is key. It forces the model to generate a richer, more nuanced probability distribution over its possible outputs. This distribution, often called soft labels, contains the model's "wisdom" about the relationships between different answers, which is exactly what we want to transfer to a smaller model.
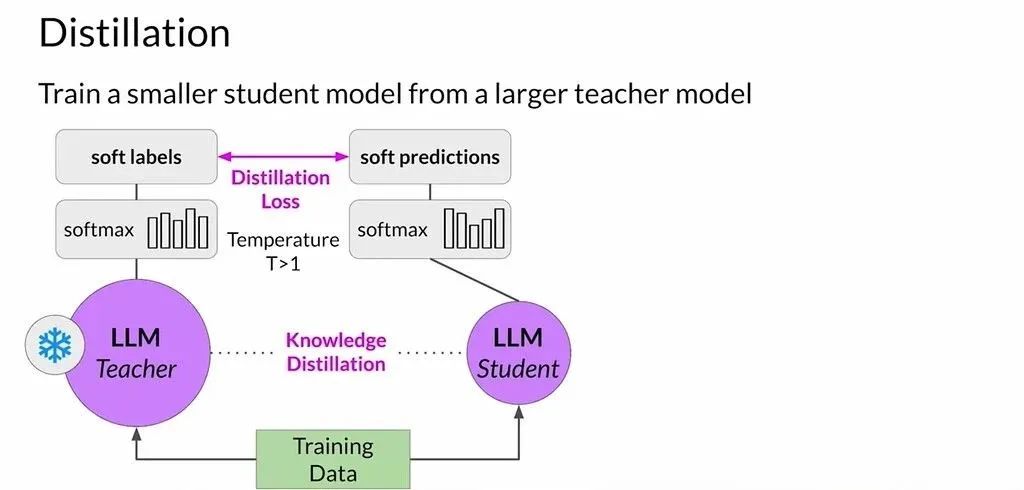
How Knowledge Distillation Works for Model Compression
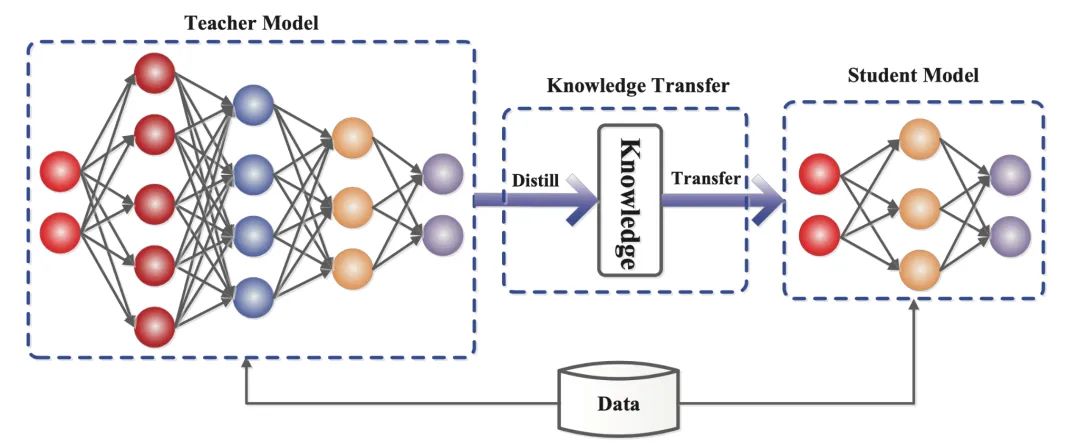
The core idea behind knowledge distillation, a powerful AI model compression technique, is to train a smaller, more efficient "student model" to mimic the nuanced "thought process" of a much larger "teacher model"—not just its final answers.
The Teacher Model: Generating Soft Labels
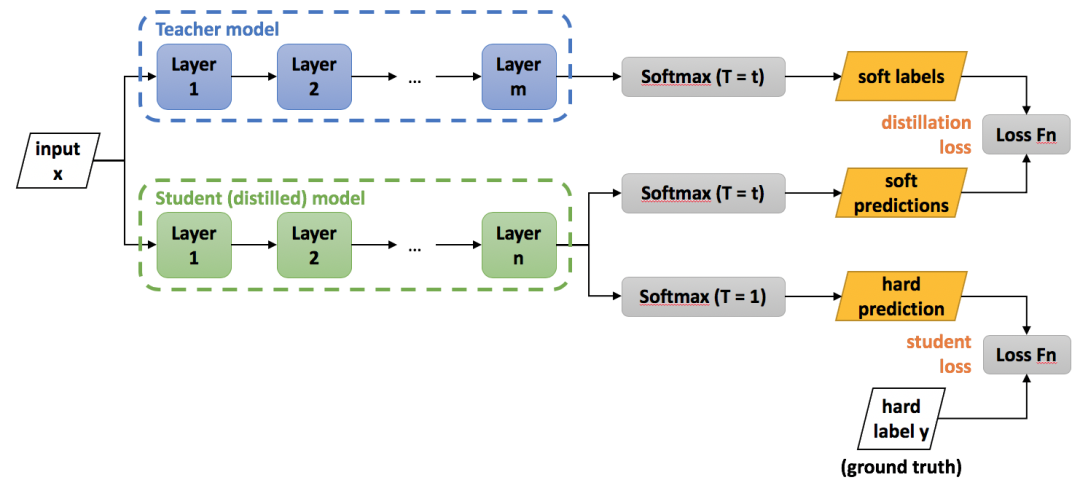
The large teacher model is first prompted with an input. By using a high model temperature, we get a rich probability distribution (the soft labels) across all possible outputs.
For example, when translating "我很饿" (I am very hungry), the teacher's high-temperature output might look like this:
"I am hungry": 60% probability"I'm hungry": 25% probability"I'm starving": 10% probability"I feel hungry": 5% probability
The Student Model: Learning from Nuanced Probabilities
The compact student model is then trained to replicate this entire probability distribution from the teacher. Instead of just learning that "I am hungry" is the top answer, it learns the relative likelihood of all the alternatives.
This method is powerful because the student gains a more generalized understanding. It learns not only the correct answer but also why it's correct in relation to other plausible options. This deeper intuition allows it to perform better on new, unseen data, retaining much of the teacher's power in a smaller package.
The Two Stages of the Knowledge Distillation Process
How does knowledge distillation work? The process typically unfolds in two key stages, making it an effective strategy for training smaller AI models.
Step 1: Train the Teacher Model First, a massive, state-of-the-art teacher model is trained on a huge dataset. The primary goal at this stage is to achieve the highest possible accuracy and nuance, without concern for size, speed, or computational cost.
Step 2: Transfer Knowledge to the Student Model Next, the wisdom from the teacher is "distilled" into the smaller student model. The student is trained using the teacher's high-temperature probability outputs (soft labels) as its guide. This transfers the deep knowledge into a model that is smaller, faster, and optimized for real-world deployment.
Why Knowledge Distillation is Crucial for LLM Deployment
Knowledge distillation is a powerful form of AI model compression that does more than just shrink an AI. By using a higher model temperature to generate soft labels, we can train smaller, faster student models that retain a remarkable degree of their larger counterparts' wisdom. This technique is crucial for deploying advanced AI on devices with limited resources, from smartphones to edge computing systems. It makes state-of-the-art LLM technology more accessible, efficient, and practical for everyday applications.
Key Takeaways
• Knowledge distillation enables training smaller, efficient AI models from larger ones.
• Model temperature plays a crucial role in the distillation process.
• This technique is essential for effective large language model deployment.