Editor's Note: As remote work solidifies its place in the modern workforce, companies face the challenge of maintaining employee engagement and company culture from a distance. This shift prompts a reevaluation of traditional management practices. How can organizations foster a sense of belonging and collaboration in a virtual environment, ensuring that remote employees feel as valued and connected as their in-office counterparts? The answers may redefine workplace dynamics for years to come.
TL;DR
Modern LLM applications have diverse latency needs. Interactive chatbots require a low Time to First Token (TTFT), while code completion tools demand minimal end-to-end generation time. Current LLM serving systems, optimized for raw throughput, often fail to meet these real-world latency requirements, or Service Level Objectives (SLOs).
This post introduces goodput, a more accurate metric measuring the number of requests per second that meet their SLOs. To maximize goodput, we propose a new Prefill-Decode separation architecture for LLM inference. Our prototype system, DistServe, implements this architecture by disaggregating the Prefill and Decode stages onto separate GPUs. This approach achieves up to 4.48x higher goodput and supports 10.2x stricter SLOs than state-of-the-art systems like vLLM.
Why Goodput is a Better Metric Than Throughput for LLM Serving
Large Language Models (LLMs) are transforming industries, but the high cost of LLM serving is a significant barrier. The community has largely focused on maximizing system throughput—the total requests completed per second (rps)—to reduce costs. This is the primary benchmark for popular serving engines like vLLM and TensorRT-LLM.
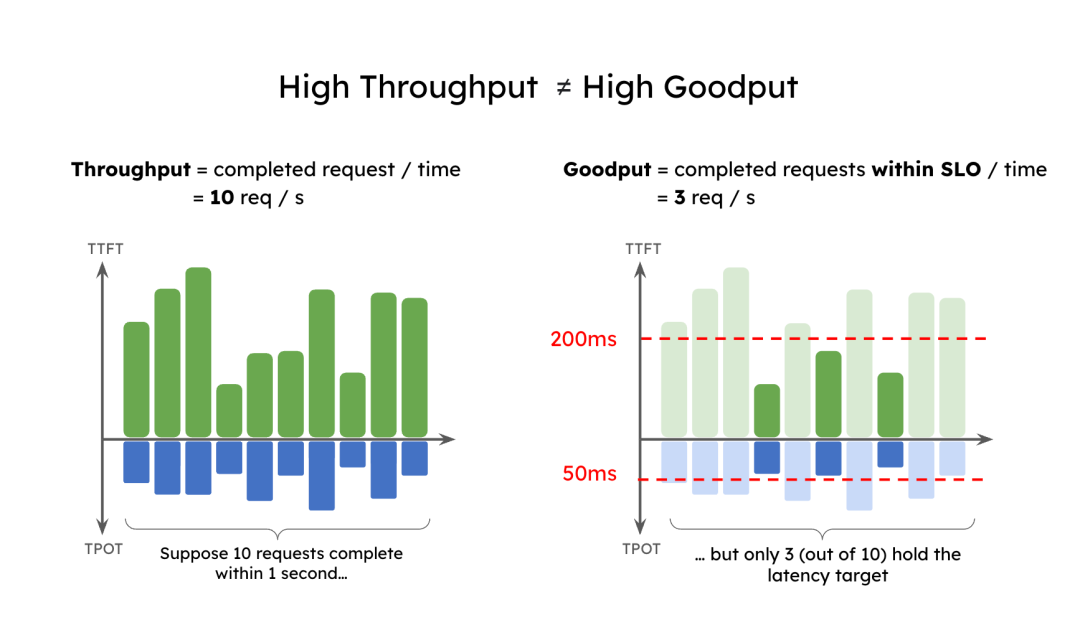
However, raw throughput is a vanity metric. A system's true value is its ability to process requests while meeting latency SLOs. This is where goodput becomes essential. We define goodput as the number of requests completed per second that successfully meet their latency targets. It measures the usable throughput that contributes to a high-quality user experience.
The most common SLOs for LLM serving are Time to First Token (TTFT) and Time Per Output Token (TPOT).
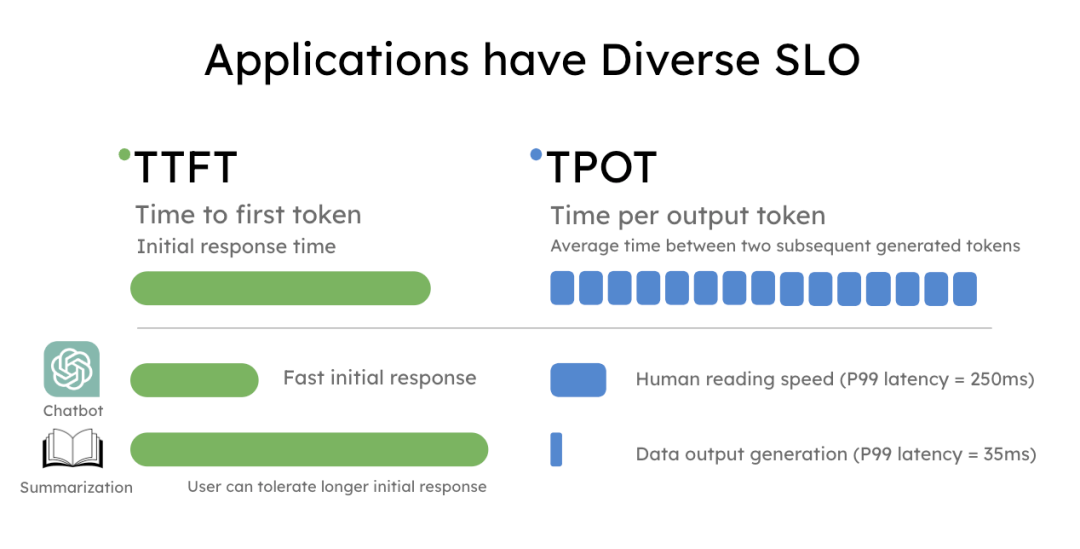
For example, if an application requires a P90 TTFT < 200ms and a P90 TPOT < 50ms, its goodput is the maximum request rate where 90% of requests meet both targets. As Figure 1 shows, a system reporting 10 rps throughput might only have a goodput of 3 rps if just three requests meet the SLO. Optimizing for throughput alone can lead to a poor user experience.
Key LLM Serving Terminology
Here is a quick glossary of key terms for understanding LLM inference performance:
| Term | Definition |
|---|---|
| TTFT | Time To First Token: The delay from when a request arrives to when the first output token is generated. |
| TPOT | Time Per Output Token: The time it takes to generate each subsequent output token. |
| SLO | Service Level Objective: A performance target, such as P90 TTFT < 200ms. |
| Throughput | The total number of requests completed per second, regardless of SLOs. |
| Goodput | The number of requests completed per second that successfully meet their SLOs. |
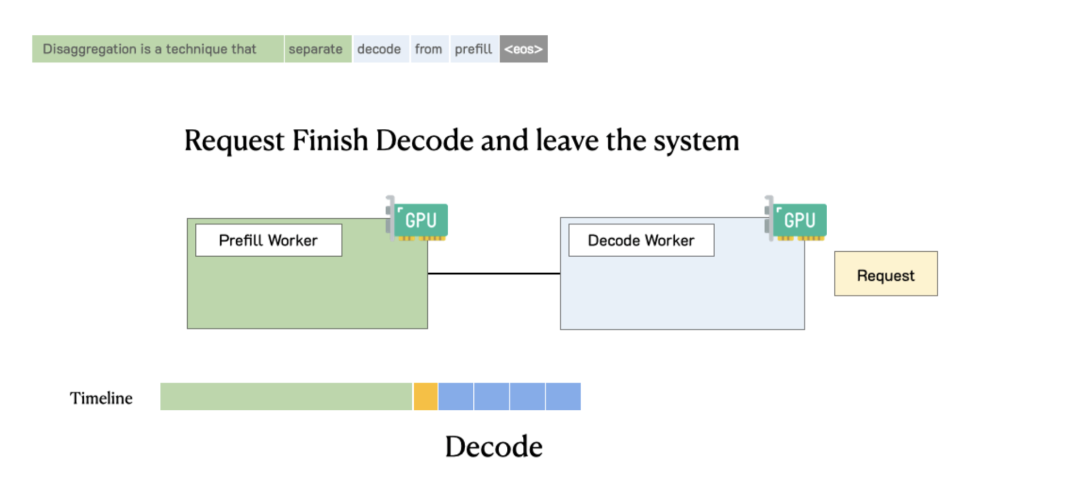
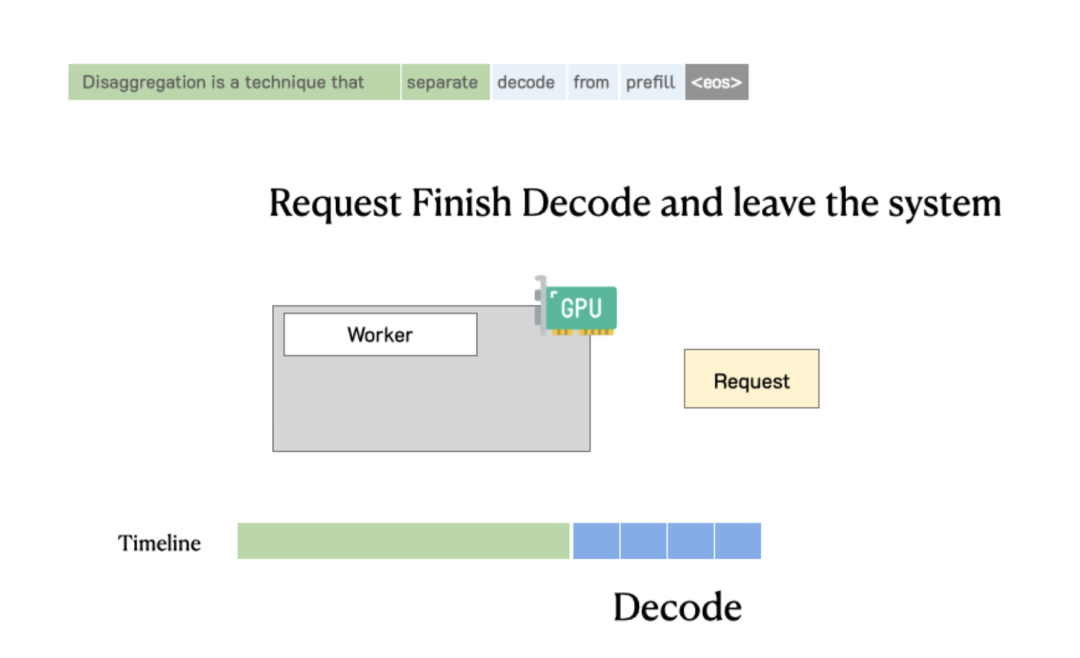
To understand the performance challenges, let's review the two main stages of LLM inference. The Prefill stage processes the input prompt to generate the first token. The Decode stage then generates subsequent tokens autoregressively. To improve GPU utilization, modern systems use continuous batching to group Prefill and Decode operations from many requests into a single batch.
The Prefill-Decode Bottleneck in LLM Inference
While continuous batching boosts raw throughput, it creates a performance bottleneck by colocating two computationally distinct stages on the same GPU resources.
- The Prefill stage is compute-intensive, processing long prompts.
- The Decode stage is memory-bandwidth-bound, processing one token at a time per request.
This colocation is inefficient and harms goodput in two primary ways:
H3: Resource Contention and Latency Jitter
Heavyweight Prefill tasks and lightweight Decode tasks compete for the same GPU resources. As shown in Figure 3, when a new Prefill request is batched with an ongoing Decode request, the fast Decode step is forced to wait for the slow Prefill to complete. This head-of-line blocking causes significant latency jitter, making it difficult to guarantee a low TPOT under heavy load.
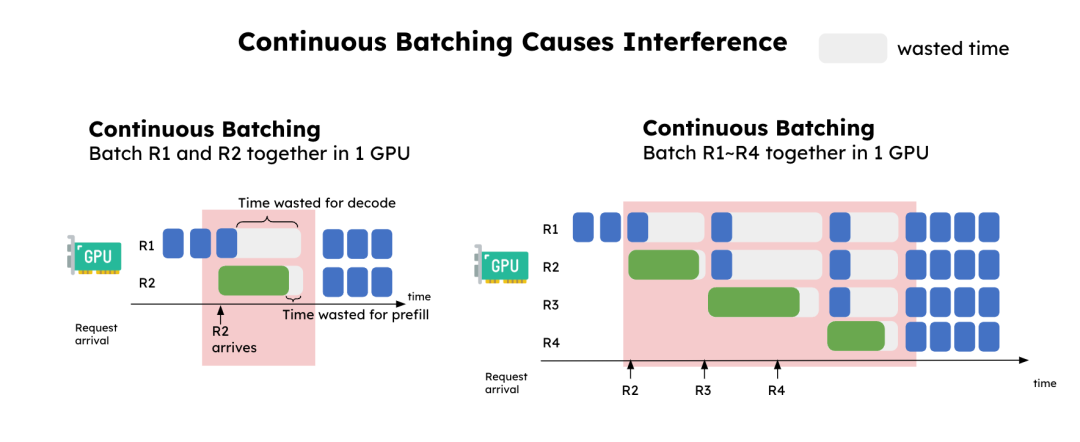
This interference forces systems to be heavily over-provisioned to meet strict TTFT and TPOT SLOs, wasting expensive GPU cycles.
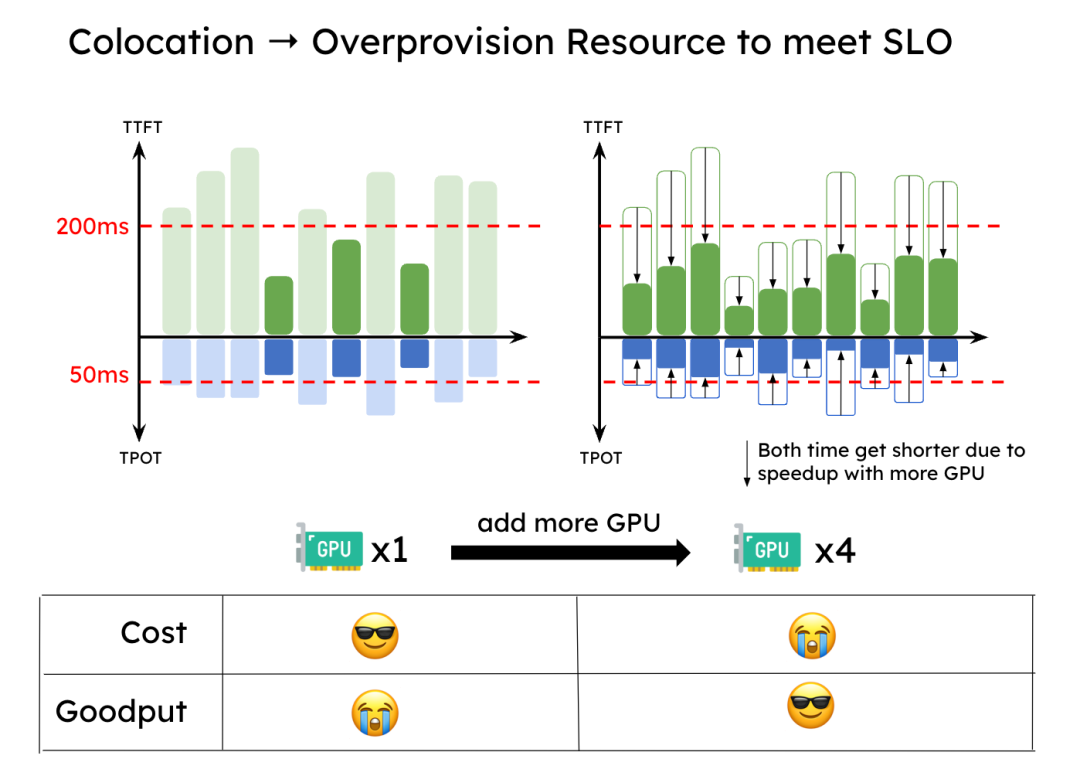
H3: Suboptimal Parallelism Strategies
Colocation forces both stages to use the same parallelism strategy (e.g., tensor, pipeline). However, the optimal strategy often differs. Prefill may benefit from tensor parallelism to reduce TTFT, while Decode might need pipeline parallelism to maximize concurrent requests for a relaxed TPOT. Colocation prevents this independent optimization.
DistServe's Solution: Prefill-Decode Separation Architecture
Our solution is to disaggregate the Prefill and Decode stages onto dedicated GPUs. This Prefill-Decode separation resolves the core issues of colocation:
- Eliminates Interference: With dedicated hardware, Prefill and Decode operations no longer compete for resources, eliminating head-of-line blocking and reducing latency jitter.
- Enables Customized Parallelism: Each stage can use its optimal parallelism strategy, allowing fine-grained tuning to meet specific SLOs for both TTFT and TPOT.
In this disaggregated system, a request is first handled by a Prefill worker. After the first token is generated, the request's state (the KV Cache) is migrated to a Decode worker for subsequent token generation.
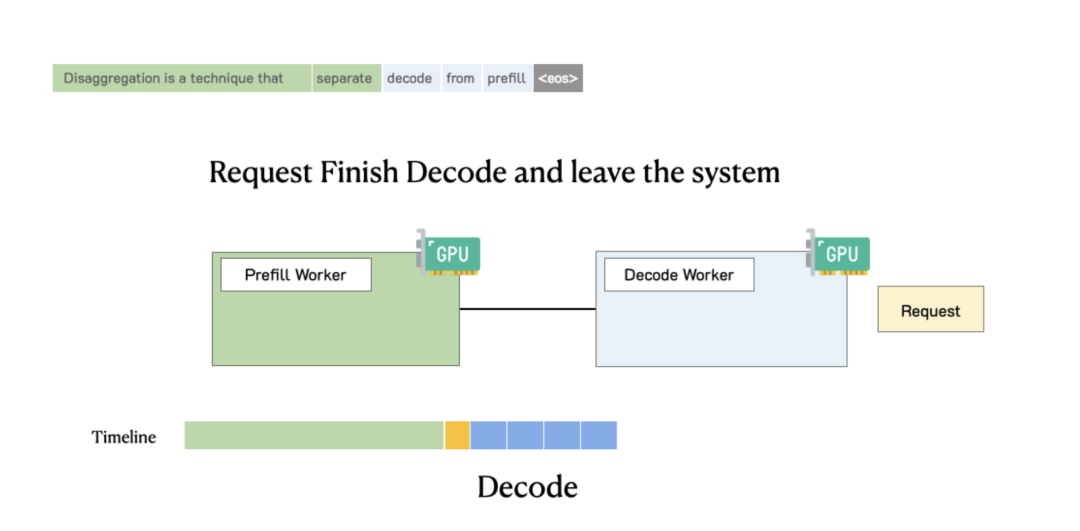
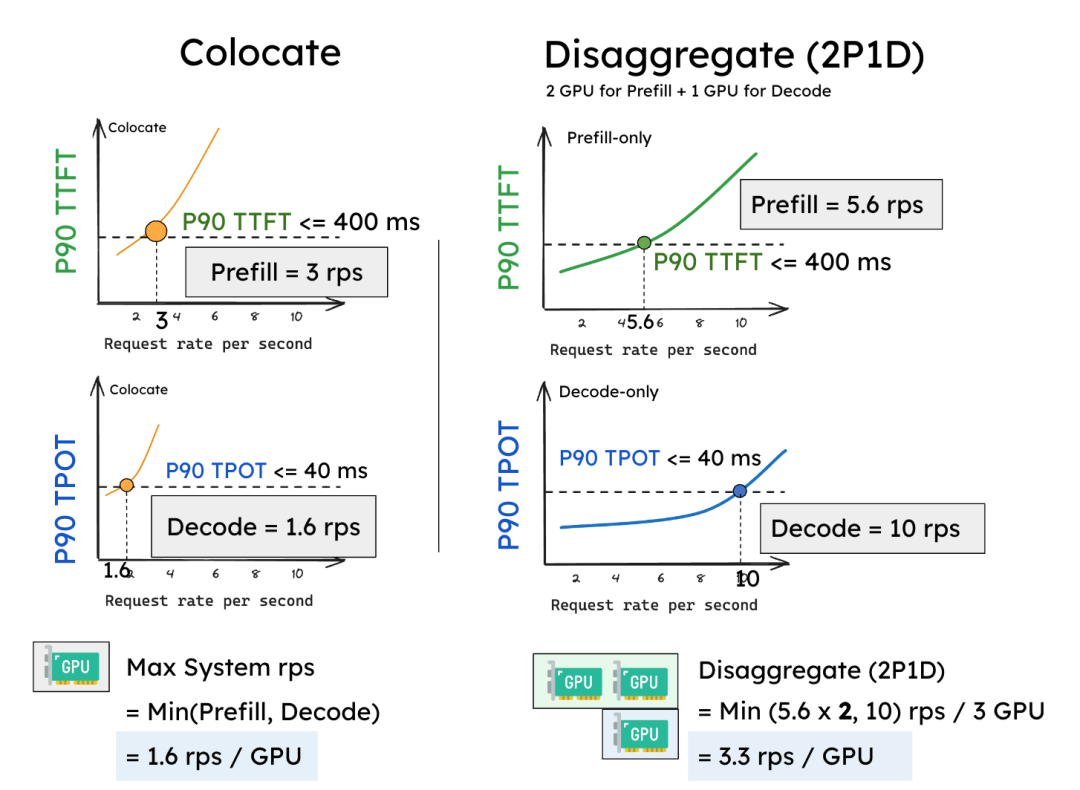
This separation dramatically improves goodput. In an experiment with a 13B model, a standard collocated system achieved a goodput of 1.6 rps per GPU. With Prefill-Decode separation, we can provision a 2-Prefill-worker, 1-Decode-worker (2P1D) configuration that achieves a total goodput of 10 rps, or 3.3 rps per GPU—a 2x improvement before even applying customized parallelism.
Managing KV Cache Transfer Overhead
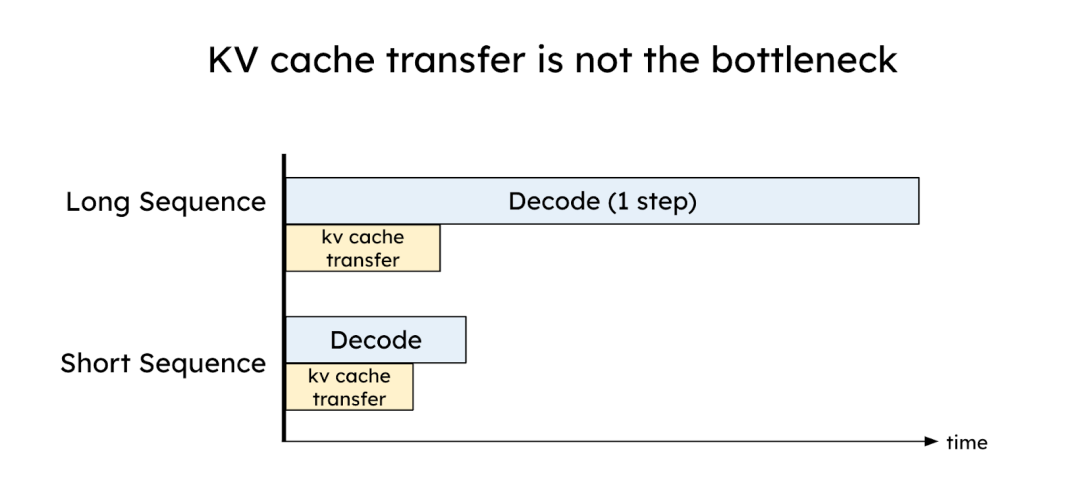
The primary trade-off of Prefill-Decode separation is the overhead of transferring the KV Cache between GPUs. However, with modern high-speed interconnects like NVLink and PCIe 5.0, this transfer time is often negligible and can be hidden.
For instance, transferring a 2048-token KV Cache for an OPT-175B model over PCIe 5.0 takes about 17.6 ms, which is faster than a single Decode step (30-50ms) for that model. As Figure 7 illustrates, for larger models or faster networks, the relative cost of the KV Cache transfer becomes even smaller, making the separation highly efficient.
Performance Evaluation: DistServe vs. vLLM
We implemented our architecture in a prototype system called DistServe and benchmarked it against vLLM, a leading LLM serving system. We used three workloads with different latency requirements to simulate real-world applications.
Table 1. Workloads and latency requirements in our evaluation
| Workload | Dataset | TTFT SLO | TPOT SLO |
|---|---|---|---|
| Chatbot | ShareGPT | 500ms | 50ms |
| Code Completion | HumanEval | 200ms | 20ms |
| Summarization | XSum | 1000ms | 100ms |
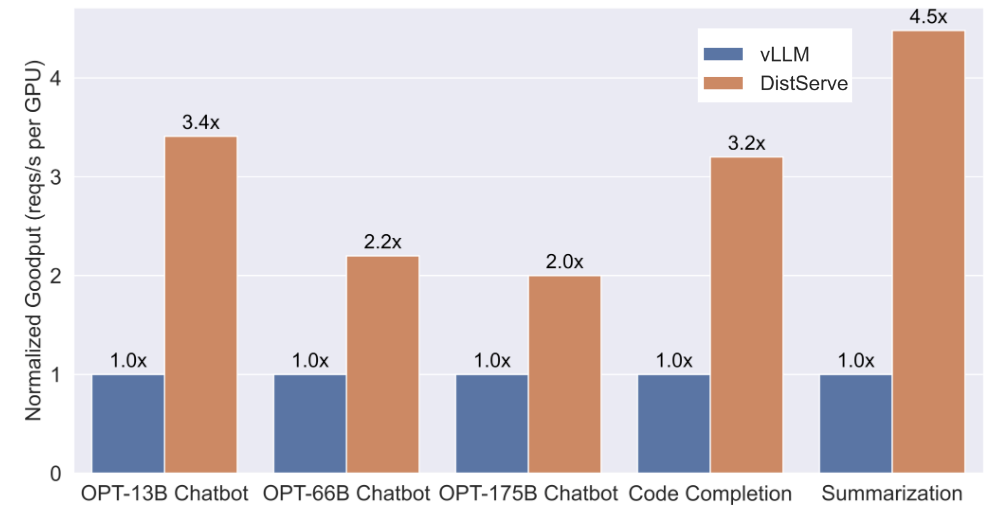
Results in Figure 8 show that DistServe consistently outperforms vLLM on goodput. For the demanding code completion workload, DistServe achieves 4.48x higher goodput, proving the effectiveness of the Prefill-Decode separation architecture for delivering high-quality LLM inference under strict SLOs.
Related Work: Prefill-Decode Separation vs. Chunked Prefill
Another recent technique for LLM serving is dynamic splitfuse, or Chunked Prefill. This method breaks long Prefill tasks into smaller chunks, allowing Decode operations to be interleaved into batches. While this can improve overall GPU utilization and raw throughput, it can negatively impact goodput.
Chunked Prefill can increase TTFT due to less efficient execution of smaller chunks. Furthermore, mixing any Prefill computation into a batch inevitably slows down co-located Decode operations, increasing TPOT. For applications with strict SLOs on both metrics, Prefill-Decode separation is a superior approach.
Concurrent research like Splitwise and TetriInfer has also explored disaggregating Prefill and Decode, suggesting a growing consensus that this architecture is foundational for the next generation of high-performance LLM serving systems.
Key Takeaways
• Implement Prefill-Decode separation to enhance LLM goodput by 4.48 times.
• Utilize the DistServe architecture to optimize latency and meet strict SLOs.
• Focus on goodput as a key metric for evaluating LLM serving performance.