Of course. Here is the enhanced and anglicized version of the content, following all your guidelines.
I’ve been deep in the trenches with Agentic AI applications lately, and a recurring theme is the sheer demand these systems place on infrastructure. As I was grappling with the challenges in my own development work, AWS conveniently dropped a suite of new products at their 2024 New York City Summit1, including Amazon Bedrock AgentCore and S3 vector buckets. This announcement came just two weeks after they unveiled their custom GB200 instances, and it’s no coincidence.
In fact, the launch of Bedrock AgentCore might just be the missing piece of the puzzle, explaining why AWS is so keen on merging the front-end CPU network with the GPU's scale-out fabric.
But the infrastructure demands of Agentic AI go far beyond networking. We're talking about specialized virtualized environments for agent execution, sophisticated in-memory storage for Context Engineering, secure sandboxes for code-generating models, and the monumental task of coordinating Multi-Agent Systems.
This article will break down these emerging software and hardware requirements and explore the potential evolution of the infrastructure that will power the next generation of AI.
AWS Unveils Its End-to-End Agentic Infra: Bedrock AgentCore
The AWS keynote in New York kicked off by addressing a pain point every developer in this space knows well: deploying AI agents into production is hard. Really hard.

The core challenges aren't just about model performance; they're about the nitty-gritty operational details: security isolation, authentication, access control, observability, reliable code execution, and enabling agents to discover and use tools (often called MCP/A2A, or Model-as-a-Controller-Plane / Agent-to-Agent communication).
To tackle this complex web of problems, AWS introduced Bedrock AgentCore, a platform built on seven core components.
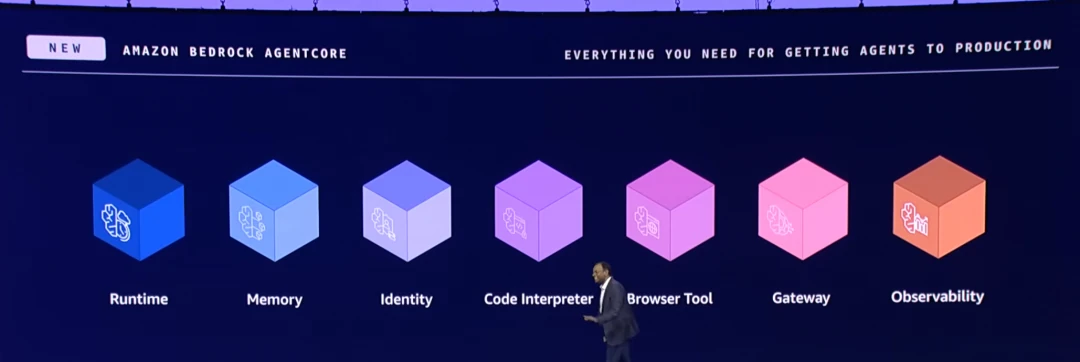
This isn't just a simple extension of traditional cloud services or a copy-paste of old paradigms like FaaS or microservices. Bedrock AgentCore represents a fundamental infrastructure shift, purpose-built for the unique demands of Agentic Software. Let's break it down.
Agent Runtime
At its heart is a secure, serverless runtime environment designed specifically for agents. It uses lightweight MicroVMs to provide robust, session-level security isolation, complete with built-in identity authentication and lightning-fast cold starts. This runtime is framework-agnostic, allowing you to bring your own tools like CrewAI or LangGraph (or use AWS's own Strands), connect to any open-source tool, and use any model to dynamically expand an agent's capabilities.

What's fascinating here is the use of MicroVMs to handle complex, asynchronous workloads that can last up to eight hours. This is a world away from traditional stateless serverless functions. Agent execution is inherently stateful; it needs to maintain a significant amount of context. It might even require execution checkpoints, allowing it to roll back to a previous snapshot and retry a step if something goes wrong.
Furthermore, agents often operate with specific identities and permissions to handle sensitive data, making the security of their execution environment paramount. Traditional containers, even those used in some AWS Lambda services, simply don't offer this level of hardened isolation.
Memory Service
This component manages an agent's short-term and long-term memory, providing the crucial context the model needs to reason and act. It leverages technologies like vector databases and the newly announced Amazon S3 Vectors storage.

AWS has created a powerful abstraction here. Short-term memory is for the here and now, tracking contextual information in real-time during a conversation, like raw interaction events. Long-term memory, on the other hand, stores persistent knowledge across sessions, such as user preferences, conversation summaries, and semantic facts.
Tool Integration
This enables AI agents to seamlessly and securely connect with AWS services and third-party tools like GitHub, Salesforce, and Slack. By leveraging user identity or pre-authorized consent, agents can use secure credentials to safely access external resources.

Code Interpreter
This provides a sandboxed, isolated code execution environment for agents to perform computations, data analysis, or run generated scripts safely.

Browser
This is a model-agnostic browser tool that gives agents the ability to interact with the web. It operates in a secure, sandboxed environment with full VM-level isolation, comprehensive auditing, and session-level privacy.

Tool Gateway
The Gateway offers a simple and secure way for developers to build, deploy, discover, and connect to external tools at scale. One of its most powerful features is the ability to automatically convert existing APIs (like RESTful or GraphQL), Lambda functions, and other services into agent-compatible tools (MCP).

Observability
You can't fix what you can't see. This component provides deep observability into agent execution, allowing developers to trace, debug, and monitor agent performance in production. It supports standard formats like OpenTelemetry and integrates tightly with AWS's own CloudWatch service.

Drilling Down: The Runtime Environment
Two aspects of the Agent Runtime deserve a closer look.
First is session-level isolation. Traditional runc-based containers have known security vulnerabilities, which is why AWS is wisely adopting MicroVM technology like Firecracker for this scenario. But it's not just about isolating one session from another; multi-tenant isolation is also critical. When sensitive applications and data are deployed within a VPC, the runtime's MicroVMs must also reside inside that VPC. Secure data access might even necessitate a zero-trust framework.
Second, for "Computer-Use" agents that need to interact with desktop applications, the runtime must support virtual desktops and common GUI functions. Similarly, to break down data silos within mobile apps, "Mobile-Use" scenarios are becoming increasingly important.
All operations and calls made to these VMs via the agent's control plane (MCP) need corresponding observability logs. A relatively mature solution in this space is Alibaba Cloud's Wuying AgentBay. It uses MCP to fully support a range of use cases, including Windows/Linux Computer-Use, Browser-Use, Code Interpreter, and Mobile-Use. It can spin up VMs on a per-session basis, and their GUIs can be observed in real-time through a browser. By leveraging cloud virtualization and massive compute pools, it can even run multiple VMs simultaneously to tackle complex tasks.

AgentBay also allows for custom images to support a wider variety of applications and can be deployed within a specified VPC. In essence, the AgentBay platform provides a superset of the Browser and Code Interpreter components in Bedrock AgentCore. For example, we can pair the Kimi K2 model with the AgentBay Code MCP to execute a task for retrieving and analyzing stock market data.

Platforms like AgentBay are also incredibly valuable for training large model-based agents. Particularly during Reinforcement Learning (RL), the ability to use VM snapshots makes it trivial to perform an "Environment Rollback"—reverting to a previous state to explore a different action path. This is exactly the kind of simulation-based training Elon Musk is focused on.

The Memory Service: The Hardest Problem to Solve
The memory layer is arguably the most challenging piece of the Agentic AI infrastructure puzzle. On one hand, the application itself demands extensive Context Engineering. On the other, you have the staggering complexity of managing context across multi-turn conversations, especially in Multi-Agent scenarios. AWS's abstraction of Short-Term and Long-Term Memory is definitely the right way to think about it.

For example, while building a stock market quantitative trading agent, real-time market data, company announcements, and forum comments constituted the Short-Term Memory. The insights derived from this data—like K-line chart analysis and sentiment analysis—became Long-Term Memory. In the future, user preferences and behaviors will also be stored in Long-Term Memory, functioning much like an embedding table in a modern recommendation system.
This Short-Term/Long-Term structure effectively creates a hot/cold tiering for storage. This means object storage like S3 needs a hot cache layer and powerful search capabilities, like those offered by the new S3 Vectors. But more importantly, when multiple agents are executing in parallel, you run headfirst into massive data consistency challenges. I've touched on this before, and it's a problem that has deep roots in distributed systems.
See: "Large Model Inference Systems (Part 1) -- Starting with the DEC VAXcluster Distributed System"
This is the very problem that led to technologies like Oracle RAC CacheFusion and IBM pureScale. In the cloud era, we see it addressed in three-tiered disaggregated architectures like Alibaba Cloud's PolarDB Serverless.
However, a critical question remains: how do you implement multi-tenant isolation and compute-storage disaggregation for the Memory Service? This applies not only to user-facing text data but also to the enormous amount of KV Cache generated during model inference. This inevitably leads to the problem of building a shared memory pool. Do you use an independent, multi-tenant memory pool built on something like a CXL Switch? Unfortunately, no matter how capable CXL becomes, it's not on the GPU Scale-Up roadmap.
This dilemma points to two potential paths forward:
-
The GPU-Centric Path: From the GPU's perspective, the ideal is direct Load/Store (LD/ST) semantics to eliminate the latency and unpredictability of KV Cache transfers, which waste precious GPU cycles. AWS's current approach with the GB200 seems to be a VPC-supported Scale-Out solution. Data can be transferred first to the Grace CPU, and then to the Blackwell GPU via the high-speed NVLink C2C interconnect.
 However, this data transfer process requires robust congestion control and priority scheduling to avoid interfering with other critical network traffic.
However, this data transfer process requires robust congestion control and priority scheduling to avoid interfering with other critical network traffic. -
The CPU-Centric Path: On the flip side, the Grace CPU also needs multi-tenant isolation capabilities. A more secure approach would be to store the KV Cache in a user-controlled Runtime (like the Agent Runtime's MicroVM). This way, the cloud provider's inference platform caches as little user data as possible, creating a trade-off between performance and isolation.
Following this logic, a new hardware requirement emerges: x86 processors from AMD and Intel need to support UALink. For a chiplet-based architecture like AMD's, could they re-tapeout an I/O Die to swap some PCIe lanes for UALink, leaving the core compute dies unchanged? The upcoming Turin generation, with its high core counts and large memory capacity, is already well-suited for creating numerous session-based VMs for tenants. UALink is particularly well-designed for this, featuring a built-in MMU for multi-tenant isolation—a more complete solution than Broadcom's SUE.
If AMD and Intel were to pioneer UALink support on CPUs, it would be a massive win for the entire ecosystem. Nearly all non-NVIDIA GPU vendors would have a standard to rally around, much like AGP and PCIe did for graphics cards in the past. Debugging UALink interconnects on CPU nodes would be simpler, and third-party memory vendors like Samsung would have a clear roadmap beyond CXL. It could even enable the creation of pure memory nodes within the Scale-Up domain.
Security: A Zero Trust Approach
When you peel back the layers, the security model required for Agentic AI is effectively a Zero Trust Architecture (ZTNA). The principles of the Software-Defined Perimeter (SDP) provide an excellent blueprint that can be applied to the Agent Runtime and the backend inference platform. In a traditional SDP deployment, clients connect securely to protected resources. For Agentic AI, the Agent Runtimes act as the SDP clients, while the large model inference platform and an enterprise's internal applications are the resources, interconnected via secure application gateways.

This part of the puzzle can be solved by directly adopting the battle-tested ZTNA SDP model.
Context Engineering & The Demands on Models
I plan to dive deeper into the specifics of Context Engineering in my 'Agent101' series, but for now, the work from Manus2 perfectly illustrates the core challenge:

Manus has done extensive work to improve the KV Cache hit rate, but it's incredibly difficult to escape the fundamental problem of a sequential context stack that just keeps growing. Eventually, it blows past the model's context length limit. For instance, when I was building the stock trading agent, I hit a wall: how do you analyze hundreds of stocks in the S&P 500 simultaneously while maintaining a high cache hit rate and not overwhelming the context window?
The fundamental problem is analogous to how early processors and operating systems evolved to use virtual memory and paging. We're seeing the first hints of a solution in techniques like DeepSeek's Native Sequence Attention (NSA).

This idea of "paging" context based on 'sections' could be a powerful solution, especially since in many tasks, the data at the boundaries of these sections has no direct attention correlation.
This also makes you wonder: what kind of advanced context and caching mechanisms are being used by the models from OpenAI and DeepMind that are winning IMO gold medals and can "think" for hours on a single problem?
These, I believe, are the next frontiers for the models themselves.
Conclusion
From MicroVMs to UALink, the rise of Agentic AI is forcing a fundamental rethink of our entire infrastructure stack. In this article, I've outlined the key demands as I see them, exploring potential shifts in model architecture (Block/Section-based Attention), hardware (x86 support for UALink), agent runtimes (MicroVMs), security (Zero Trust), and the critical memory layer. I offer these thoughts as a starting point for a broader conversation and hope they are a useful reference for my peers across the industry.
Footnotes
-
AWS Summit New York City 2024: https://www.youtube.com/watch?v=2890bEb61qQ ↩
-
Manus Context Engineering: https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus ↩