Unlocking LLM Potential: The SFT Learning Rate Flaw

Transforming a pre-trained large language model (LLM) into a specialized tool requires a critical LLM fine-tuning process. This post-training stage traditionally involves two distinct methods: Supervised Fine-Tuning (SFT), where models learn from examples, and preference learning techniques like Direct Preference Optimization (DPO), which use human feedback.
A groundbreaking research paper reveals a unified theory connecting these methods, demonstrating that SFT and DPO are two sides of the same coin. This new perspective uncovers a critical flaw in standard SFT and offers a simple yet powerful solution: lowering the learning rate. This single adjustment can unlock massive performance gains, improving model win rates by up to 25% on key benchmarks.
This article explores this unified framework, explains the SFT flaw, and details how a simple learning rate tweak can significantly improve your model's performance.
The Post-Training Puzzle: SFT vs. DPO
The process of preparing a pre-trained LLM for specific tasks is known as post-training. This has long been dominated by two distinct methodologies:
- Supervised Fine-Tuning (SFT): The model learns to imitate high-quality examples from a curated dataset.
- Preference Learning: The model learns from human feedback indicating which of two or more responses is better. Direct Preference Optimization (DPO) is a popular and efficient method in this category, offering a less complex alternative to Reinforcement Learning from Human Feedback (RLHF).
While both methods are effective, the theoretical link between them has been unclear. This ambiguity has practical consequences. For instance, a key issue in standard SFT performance is that the KL divergence term—a mathematical constraint designed to prevent the model from deviating too far from its base knowledge—often becomes a constant. Its gradient vanishes, leaving the model's updates unconstrained and potentially suboptimal.
A Unified Theory Through Implicit Reward Learning
This new research bridges the gap by reframing the problem through the lens of Inverse Reinforcement Learning (IRL). IRL posits that any expert's behavior can be explained by an implicit reward function it seeks to maximize.
The paper proves that SFT is a special case of implicit reward learning, just like DPO. Both SFT and DPO are optimizing towards the same goal within an identical optimal policy-reward subspace. This insight provides the unified theory the field has been missing, connecting an LLM's log-odds (its confidence in a token) directly to the Q-function in both SFT and DPO paradigms.
The Unified Theoretical Framework Explained
The paper's unified theory is built on several core machine learning concepts.
Language Generation as a Markov Decision Process (MDP)
At its core, text generation can be modeled as a Markov Decision Process (MDP). This framework treats text creation as a sequence of decisions:
- State (
s_t): The current text (prompt + generated tokens). - Action (
a_t): The next possible token. - Policy (
π(a_t|s_t)): The model's probability of choosing a specific token.
The model's goal is to choose a sequence of tokens that maximizes a cumulative reward r(s_t, a_t).
Imitation Learning and the Role of KL Divergence
The goal of imitation learning is to make the model's output distribution (p_π) match an expert's data distribution (p_E). To prevent the model from forgetting its pre-trained knowledge (catastrophic forgetting), a KL divergence term is added to the objective function. This term penalizes deviation from the base reference model (π_{ref}).
min_{π} D_f(p_E || p_π) + λ D_{KL}(π || π_{ref})
Here, D_f is the f-divergence (a measure of statistical distance), and λ is the regularization strength.
Proving SFT is Implicit Reward Learning
Through a mathematical reformulation, the paper shows that minimizing this objective is equivalent to learning an optimal policy for an implicit reward function. The optimal policy π_r^* is directly linked to this underlying reward:
π_r^*(a|s) ∝ π_{ref}(a|s) exp(Q_r^*(s, a))
When using total variation divergence, this objective simplifies to the Maximum Likelihood Estimation (MLE) loss used in traditional SFT. This elegantly proves that SFT is a form of implicit reward learning.
Connecting SFT Log-Odds to the Q-Function
This unified view confirms that during SFT, the log-odds of the LLM's policy directly correspond to the Q-function of the implicitly learned reward.
log(π_{SFT}(a|s) / π_{ref}(a|s)) = Q_r^*(s, a) − V_r^*(s)
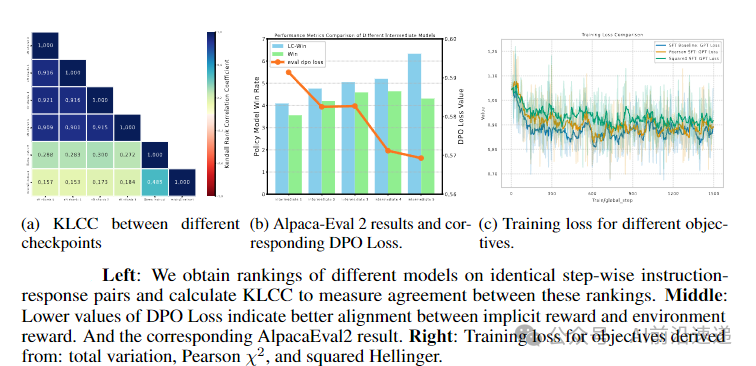
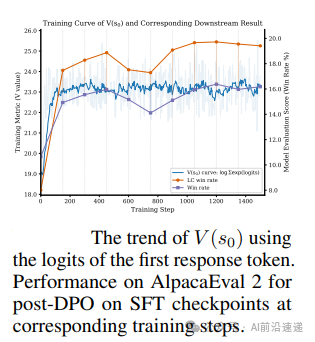
This extends the known log-odds-to-Q-function relationship from DPO to SFT, providing a solid theoretical foundation for the post-training process. Experiments confirm that this formulation provides a consistent ranking of state quality, validating its role as a value function.
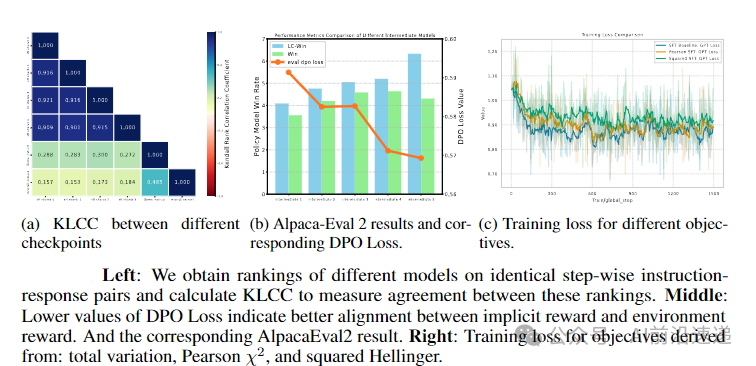
How to Improve SFT Performance: Key Findings
The research provides a unified theory of LLM post-training and offers actionable insights for improving model performance.
- The SFT Flaw Identified: The primary issue with traditional SFT is that the KL divergence term becomes ineffective during optimization. Its gradient vanishes, meaning it fails to constrain the model as intended.
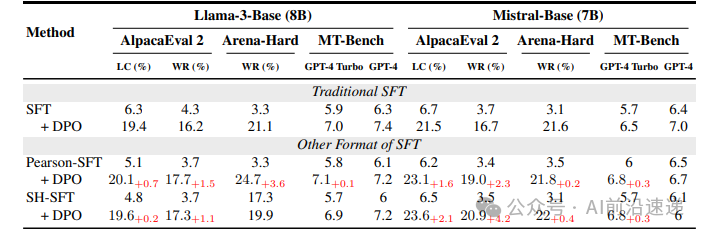
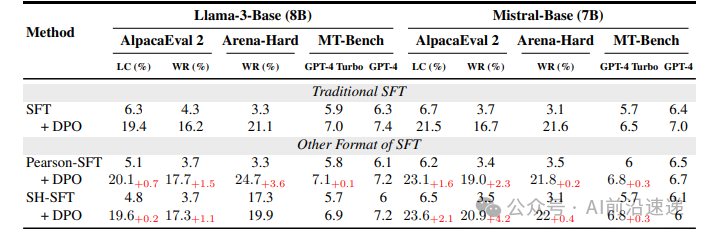
- The Simple Solution: Lower the Learning Rate: The most impactful finding is that lowering the SFT learning rate (e.g., to 5e-6 for Llama3-8B) solves this problem. This simple tweak keeps the KL term active, leading to significant performance improvements in subsequent DPO, with relative gains up to 25%.
- Advanced SFT Objectives: Building on this, the paper introduces alternative SFT objectives derived from f-divergences (like Pearson χ² and Squared Hellinger). These methods are even more effective at preserving the KL term's influence and further boost model performance.
- Unified Theory: The core contribution is proving that SFT is a form of implicit reward learning, just like DPO. This provides a stronger theoretical foundation for designing future post-training methods.
Future Directions in LLM Fine-Tuning
This research opens up several exciting avenues for future work in LLM fine-tuning.
- Jointly Optimizing SFT and DPO: Current sequential pipelines can create objective conflicts. Future frameworks could optimize SFT and DPO simultaneously for more stable and capable models.
- Exploring New f-divergences: The success with Pearson χ² and Squared Hellinger invites exploration of other f-divergences (like reverse KL and JS divergence) to create specialized and robust training operators.
- The Philosophy of Implicit Rewards: The discovery that models learn an implicit reward function raises profound questions about goal-seeking behavior and machine intelligence, stimulating new discussions in AI ethics.