The Future of LLM Training: Separated Architectures for RL Post-Training
With the rise of advanced models like OpenAI's o1 and DeepSeek's R1, RL post-training has become a critical stage in developing large language models (LLMs). The AI community is discovering that reinforcement learning (RL) not only aligns models with human values but also significantly boosts their reasoning capabilities. Furthermore, its self-iterating training paradigm offers a potential solution to the data bottleneck limiting pre-training, making it a key area of research.
When implementing reinforcement learning for LLMs, frameworks typically use one of two designs: co-located or separated architectures.
- Co-located Architecture: Different computational tasks (e.g., training and inference) share the same hardware resources, running serially in a time-division multiplexing fashion.
- Separated Architecture: Different tasks are assigned to dedicated hardware, operating in a space-division multiplexing model.
Since early this year, a clear trend has emerged: separated architectures are rapidly becoming the new standard for LLM post-training. This architectural shift is driven by the need to boost efficiency and cut costs.


Why Separated Architectures are the Future of RL Post-Training
A separated architecture for RL post-training assigns different computational tasks to dedicated hardware. This approach offers two key advantages over co-located systems: 1. Increased Efficiency: It separates compute-intensive training from memory-bound inference, preventing performance bottlenecks. 2. Reduced Costs: It allows for the use of specialized clusters and heterogeneous hardware, lowering operational expenses.
The Efficiency Problem with Co-located Architectures
The computational profiles of training and inference are fundamentally different. Training is a classic compute-intensive workload, while the decoding phase of inference is memory-bound. Their scaling dynamics diverge significantly, a performance gap that widens as cluster size or sequence length increases.
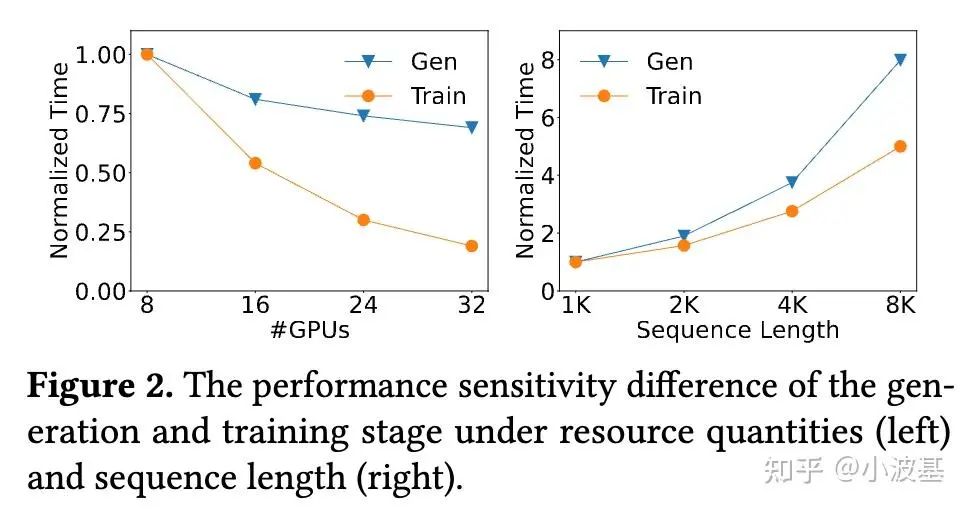
In a typical post-training run, the total token counts for inference and training are nearly identical. A co-located architecture forces these distinct workloads to share the same resources, creating a scaling wall that severely bottlenecks performance. This is especially true in large-scale scenarios. Additionally, co-located systems suffer from significant overhead as models are loaded and offloaded between steps and resharded for different tensor parallelism strategies.
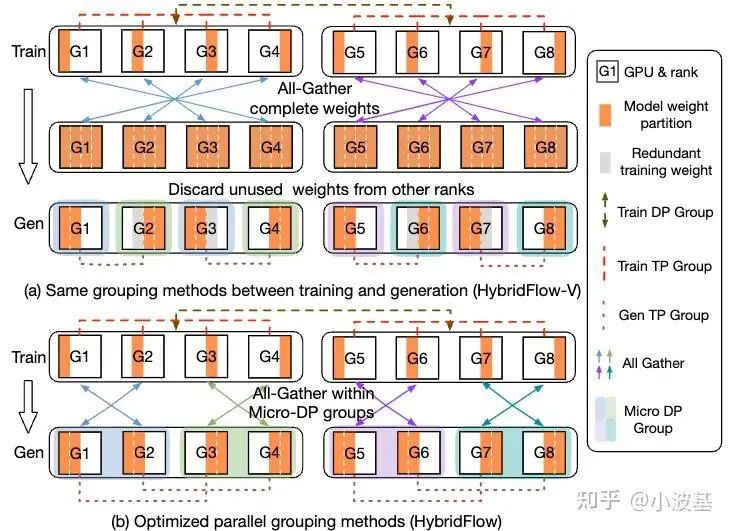
The Cost Advantage of Separated Systems
From a cost perspective, a separated architecture is highly advantageous. The RL framework can act as a high-level scheduler, enabling the reuse of existing, specialized training and inference clusters. This design also supports heterogeneous hardware for post-training, which can dramatically lower operational expenses. As post-training evolves to include more complex components like multi-agent systems and tool use, a serial computation flow becomes a major bottleneck. This is why the evidence points to separated architectures as the future of RL post-training.
The Core Challenges of Separated RL Architectures
If separated architectures are superior, why weren't they always the standard? The answer lies in their inherent complexity, particularly around data orchestration and pipeline efficiency.
Complex Data Orchestration
RL algorithms involve multiple computational tasks with complex, interwoven data dependencies. In a co-located framework, data is managed within a single process. In a separated world, multiple tasks run in parallel, turning data orchestration into a significant challenge. Data must be managed at a finer granularity—down to the micro-batch or even the sample level.
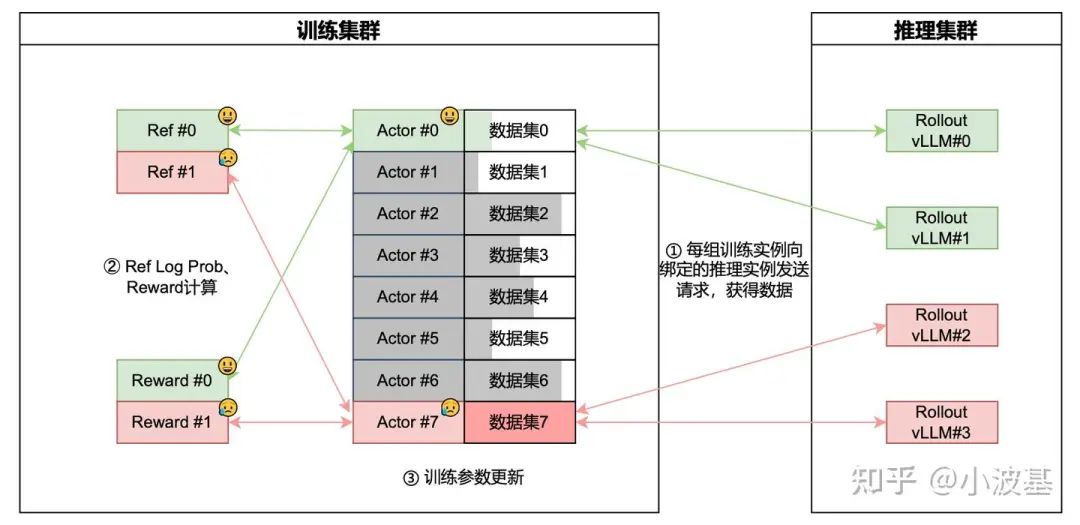
Furthermore, data dependencies are fluid. In RL, response lengths are generated on the fly, making it impossible to pre-calculate token counts. This leads to load-balancing issues that hurt training efficiency. A dynamic, flexible, "pull-based" data routing system is needed, where tasks can grab new work as soon as they have capacity.
Pipeline Bubbles and GPU Inefficiency
Another challenge stems from the RL algorithm itself. On-policy algorithms require the same model for inference and training. In a separated setup, this creates a stop-and-wait problem: inference workers generate data and then sit idle, waiting for training workers to update and broadcast new model weights. This idle time creates massive "pipeline bubbles," wasting valuable GPU cycles.
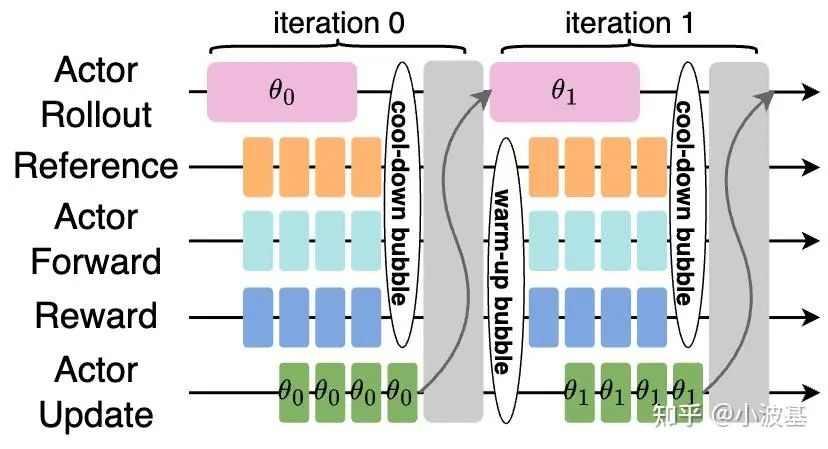
As models and clusters grew, the drawbacks of co-located architectures became too significant to ignore, forcing the community to solve the hard problems of separated systems.
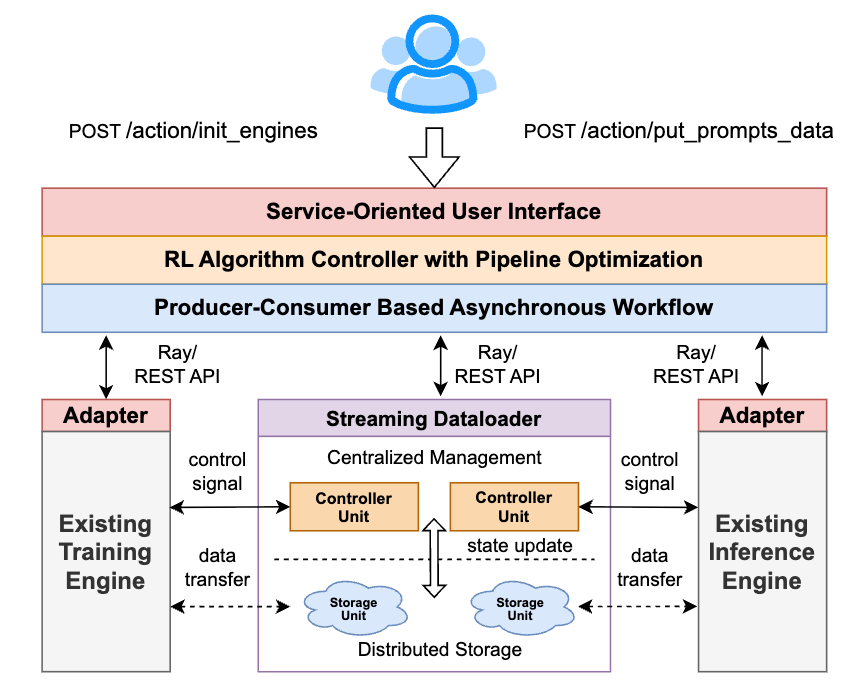
TransferQueue: A Streaming Dataflow Solution for LLMs
To overcome the challenges of data orchestration and pipeline inefficiency, a robust data system is essential. We propose TransferQueue: a data system with a global view and streaming data capabilities designed to orchestrate efficient data flow in complex LLM post-training pipelines.
TransferQueue acts as a central "data hub." Upstream producers (like Actor Rollout) send data to the hub, where it's stored at a granular level. Downstream consumers (like Actor Update) request data when ready, and TransferQueue repackages and sends what's needed. This enables dynamic data routing between any two computational tasks.
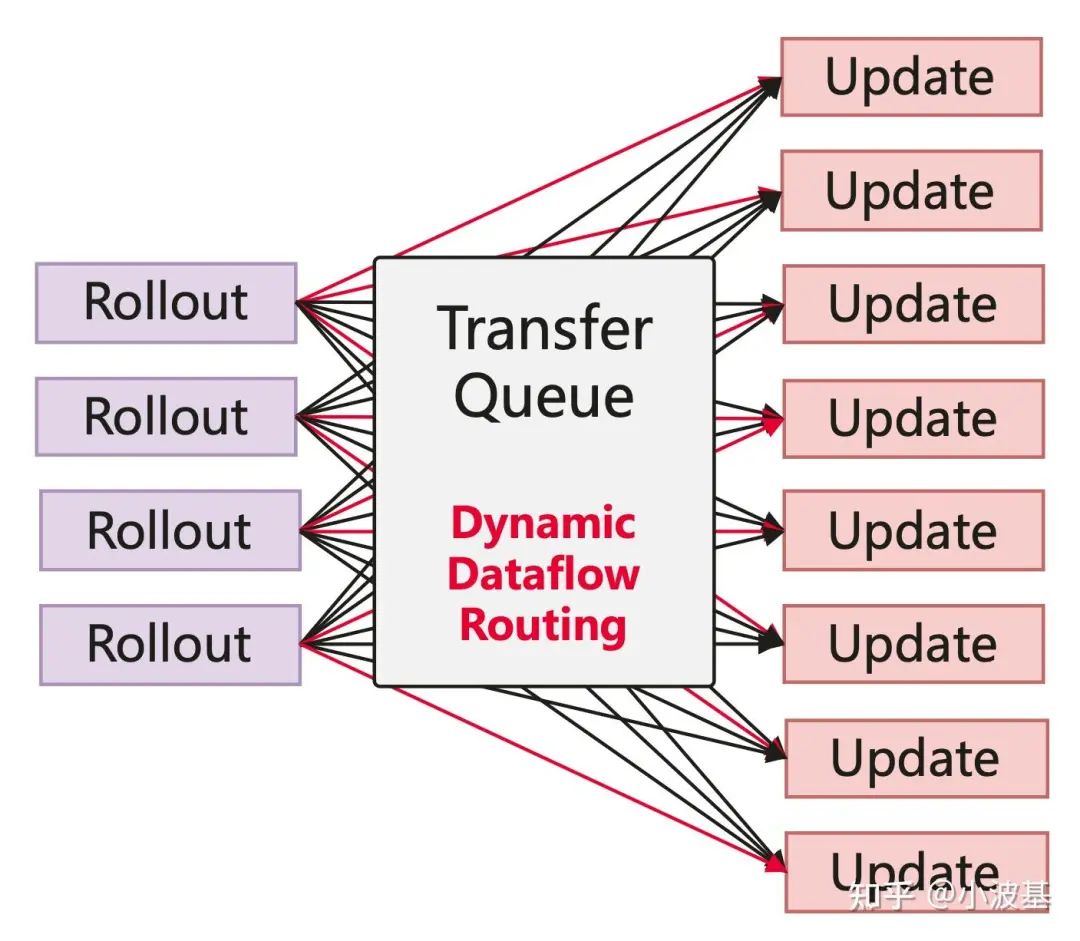
How TransferQueue Decouples Computational Tasks
This design unlocks three powerful benefits for pipeline efficiency:
- Task Decoupling: As a central intermediary, TransferQueue decouples computational tasks. This allows for automatic pipeline orchestration and makes it easy to add new stages (like a critique model or safety filter).
- Fine-Grained Scheduling: Data is managed at the sample level. The moment enough samples are ready to form a micro-batch, they can be scheduled. This "first-ready, first-served" approach reduces idle time and mitigates the impact of stragglers.
- Global Load Balancing: TransferQueue has a global view of all data, allowing it to implement sophisticated load balancing algorithms to maximize system throughput.
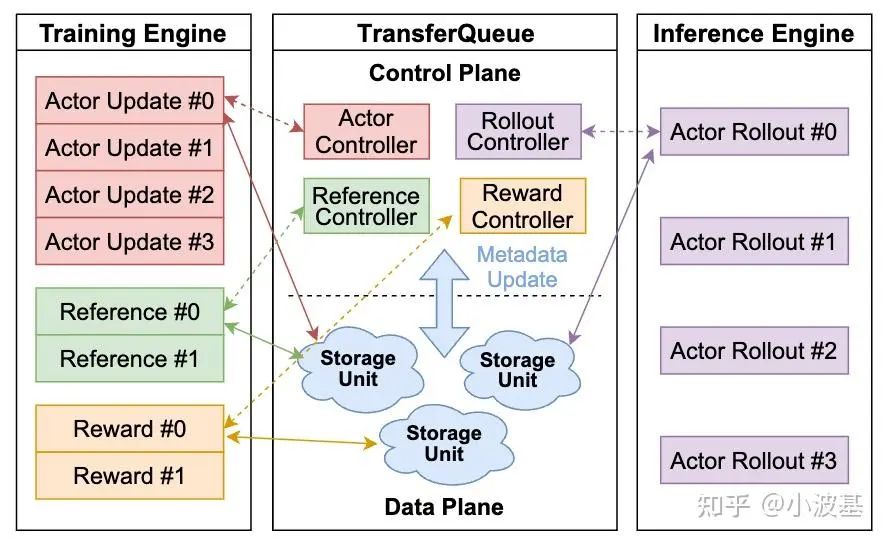
The Architecture of TransferQueue: Control and Data Planes
The diagram below illustrates the overall architecture of TransferQueue, which is divided into a control plane and a data plane. The control plane manages global data scheduling, while the distributed data plane stores and transmits the actual training data.
To enable streaming, fine-grained data management, TransferQueue organizes data in a two-dimensional structure. This design allows us to pinpoint any piece of data with a simple (index, column_name) key, enabling highly concurrent reads/writes and a true dataflow paradigm.
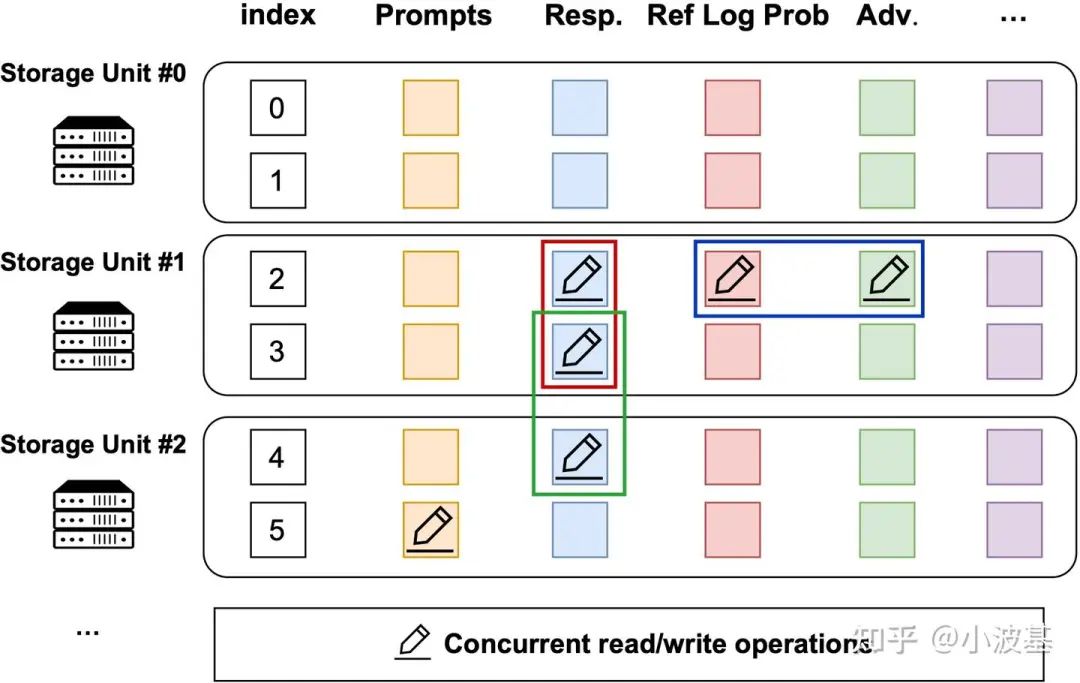
In the control plane, metadata tables track the production and consumption status of each data sample. When an upstream task writes data, the controller updates its metadata. Once all required data columns for a sample are complete, it becomes available for the next stage.
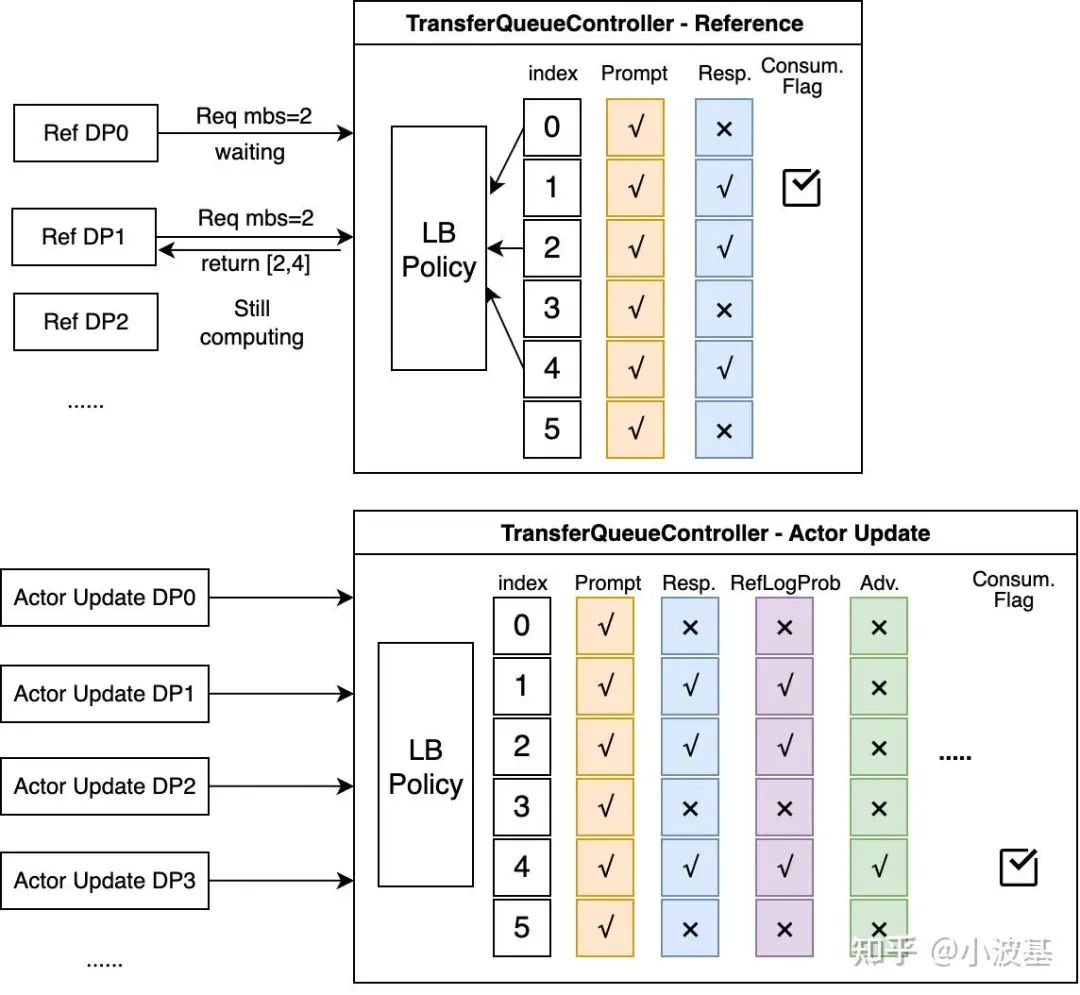
With a centralized hub like TransferQueue, the entire RL algorithm can be reframed using a simple dataflow model.
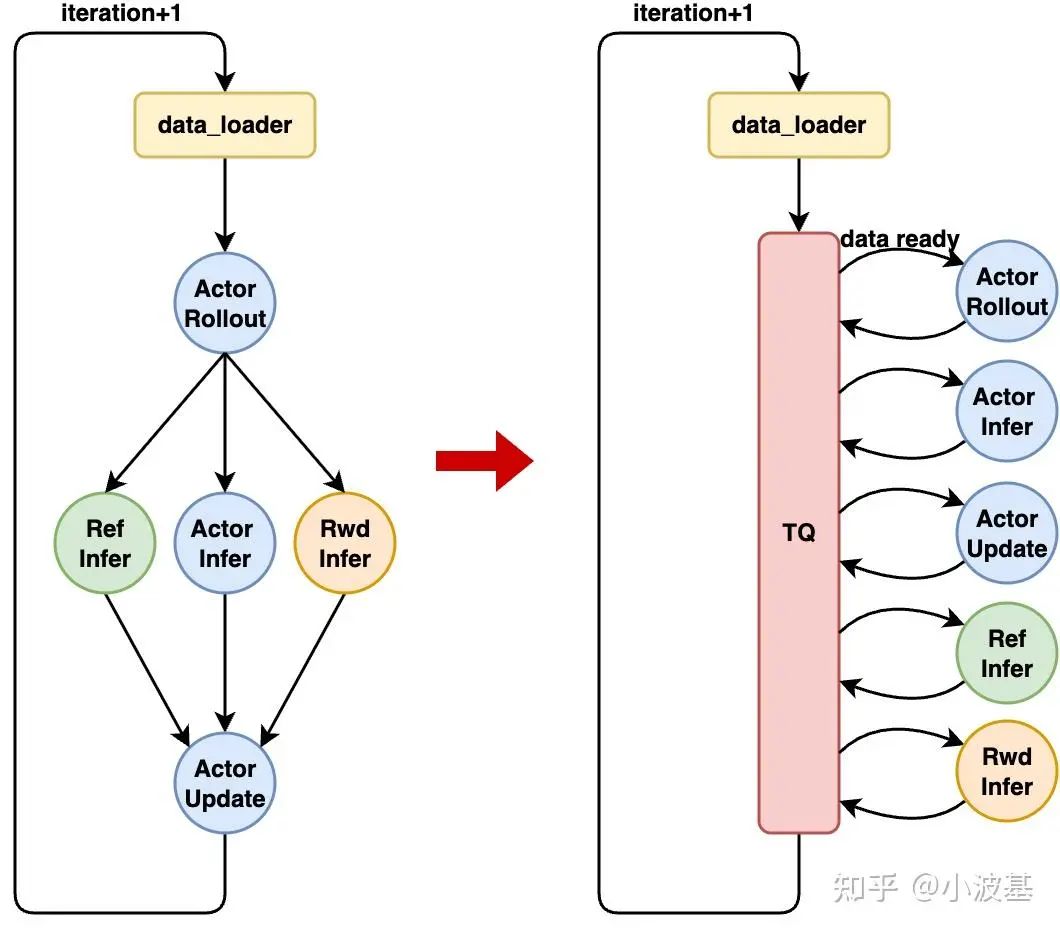
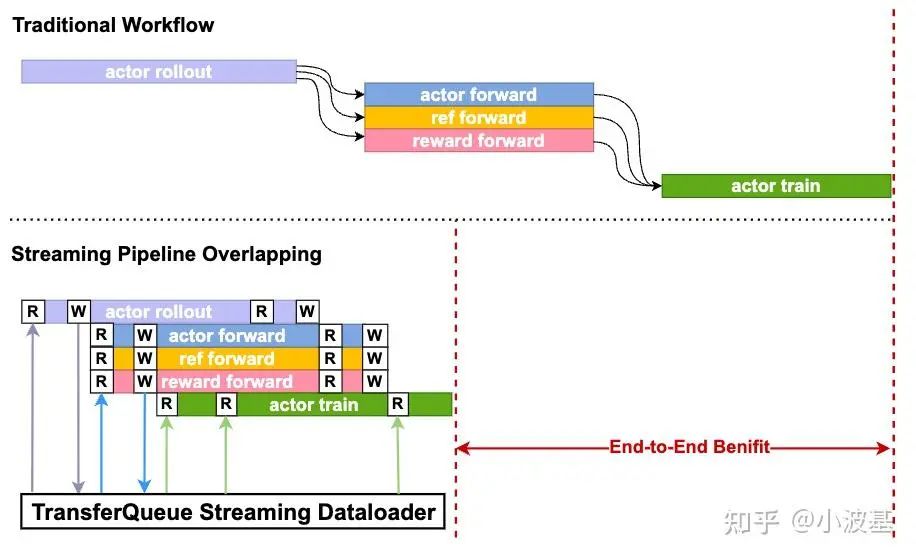
While systems like StreamRL and AReal use similar streaming concepts, they typically only stream data from the inference to the training cluster. TransferQueue provides a true end-to-end dataflow solution by extending the streaming concept within the training cluster to orchestrate all sub-tasks. We've wrapped TransferQueue into a familiar PyTorch DataLoader interface, abstracting away the complexity.
By leveraging TransferQueue, we can shrink the pipeline bubbles between global batches down to just a few micro-batches.
Implementation and Future of AsyncFlow
Our proof-of-concept for TransferQueue is built on Ray. While Ray simplifies development, we are refactoring for optimal performance at scale. The following details are illustrative.
A Look at the Code: put_experience and get_batch
The put_experience function encapsulates writing data to the store, updating metadata, and notifying downstream tasks:
def put_experience(self, data: Dict[str, Any]) -> None:
# 1. Write data to the DataStore
data_ref = self.data_store.put.remote(data)
# 2. Update metadata in the Controller
self.controller.update_metadata.remote(data_ref)
# 3. Wake up downstream waiting tasks
self.controller.broadcast.remote()
The Controller's get_batch interface applies a load balancing strategy to ensure workers remain active.
def get_batch(self, batch_size: int, worker_rank: int) -> List[DataRef]:
while True:
# 1. Get readable data
ready_indices = self.get_ready_indices()
if len(ready_indices) >= batch_size:
# 2. Select data based on worker_rank and load-balancing strategy
selected_indices = self.balance_and_select(ready_indices, worker_rank)
# 3. Update data consumption status
self.update_read_status(selected_indices)
return self.get_data_by_indices(selected_indices)
# 4. If data is insufficient, wait
self.wait()
The Path Forward: Contributing to Open Source
Looking ahead, TransferQueue will be composed of three core abstractions: DataStore, Controller, and Schema. The shift towards separated architectures marks a pivotal moment in large-scale AI. Solutions like TransferQueue show that a streaming, dataflow-centric approach can overcome the hurdles, boosting efficiency, cutting costs, and paving the way for more sophisticated AI systems.
The ideas discussed here are detailed in our recent arXiv paper, "AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training." We plan to contribute this work to the verl open-source community (see RFC #26623) and invite you to join the discussion.