Generative AI and LLMs: The Engines of Modern AI
Generative AI is a revolutionary field of artificial intelligence that creates novel content, including text, images, and code. Powering many of these transformative systems are Large Language Models (LLMs)—massive deep learning models pre-trained on vast datasets. This foundational knowledge allows them to be fine-tuned for specialized applications, making them the versatile engines for modern AI innovation.
What are Generative AI and Large Language Models?
In essence, a Large Language Model (LLM) is a sophisticated deep learning model that undergoes a two-step process:
- Pre-training: The model is trained on an enormous, general dataset of text and code to build a foundational understanding of language, patterns, and concepts.
- Fine-tuning: The pre-trained model is then adapted for specific tasks using a smaller, specialized dataset. This step hones its capabilities for a particular domain, such as finance, healthcare, or customer service.
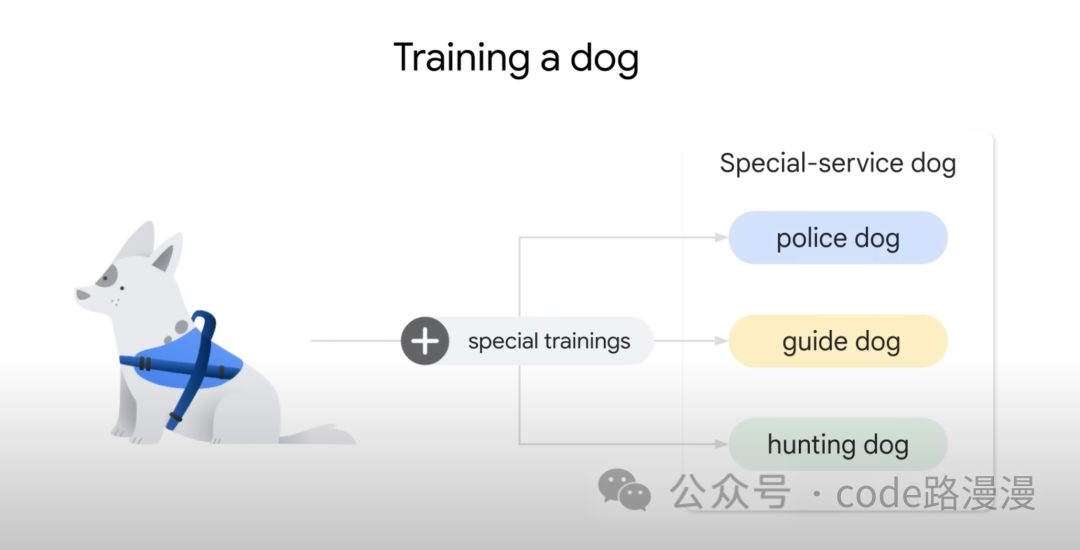
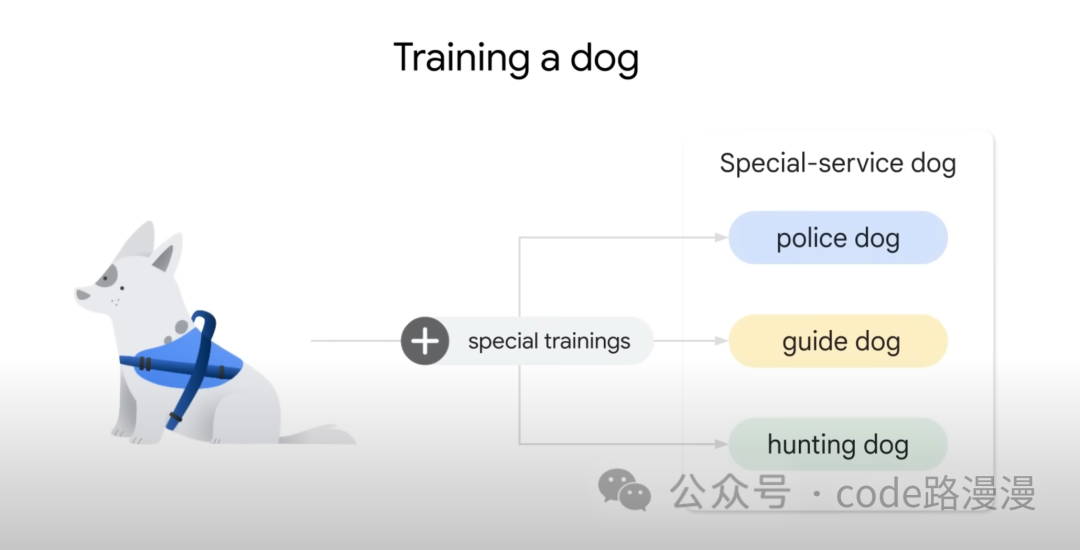
Consider an analogy: pre-training an LLM is like teaching a dog foundational commands such as 'sit' and 'stay.' This builds a solid base of general skills. Fine-tuning is the specialized instruction that follows, akin to training that dog for a specific role like search-and-rescue. This second step adapts the foundational model into an expert for a specific use case.
What Makes an LLM "Large"?
The term "large" in Large Language Model refers to two key aspects:
- Massive Datasets: LLMs are trained on an astronomical amount of high-quality data, often scraped from huge swathes of the internet. The quality and diversity of this data are critical to the model's performance and ability to understand context.
- Enormous Number of Parameters: LLMs have a staggering number of parameters—the internal variables the model learns during training. Models can have billions (e.g., 7B) of parameters, which function as the model's memory and knowledge. More parameters often translate to a more capable and nuanced model.
Training an LLM from scratch is a monumental undertaking, which is why the two-step process of pre-training and fine-tuning is the industry standard. The goal is to create a single, universal "foundation model" that can tackle a wide array of problems, such as text classification, question answering, and content generation, which can then be easily adapted.
The Transformer: The Architecture Behind LLMs
The magic behind modern LLMs lies in a groundbreaking neural network architecture called the Transformer. Its key innovation is the attention mechanism, which allows the model to weigh the importance of different words in the input text. This enables it to handle long-range dependencies and context far more effectively than previous architectures.
The power of LLMs comes from scaling this architecture up with more data, more parameters, and more stacked layers. The Transformer was first introduced to solve sequence-to-sequence problems, like machine translation or summarization.
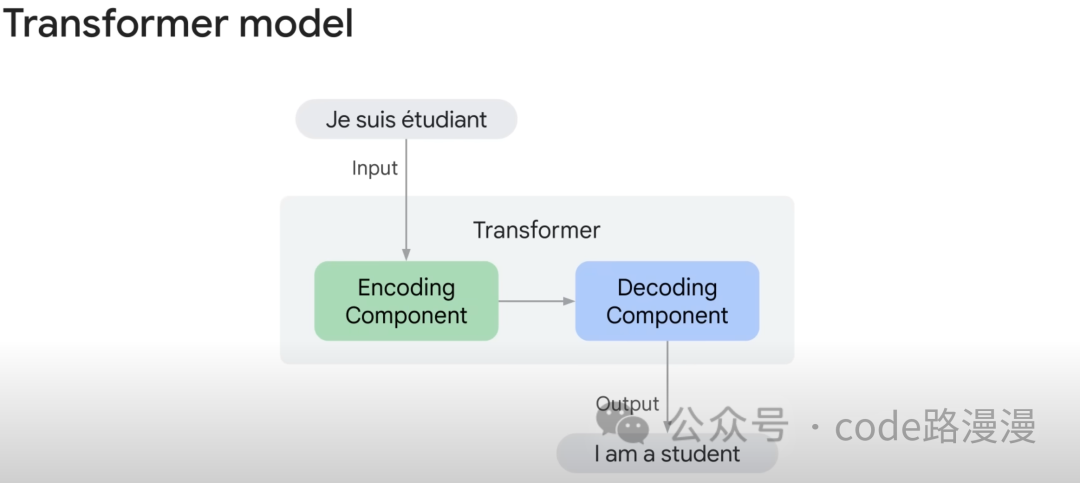
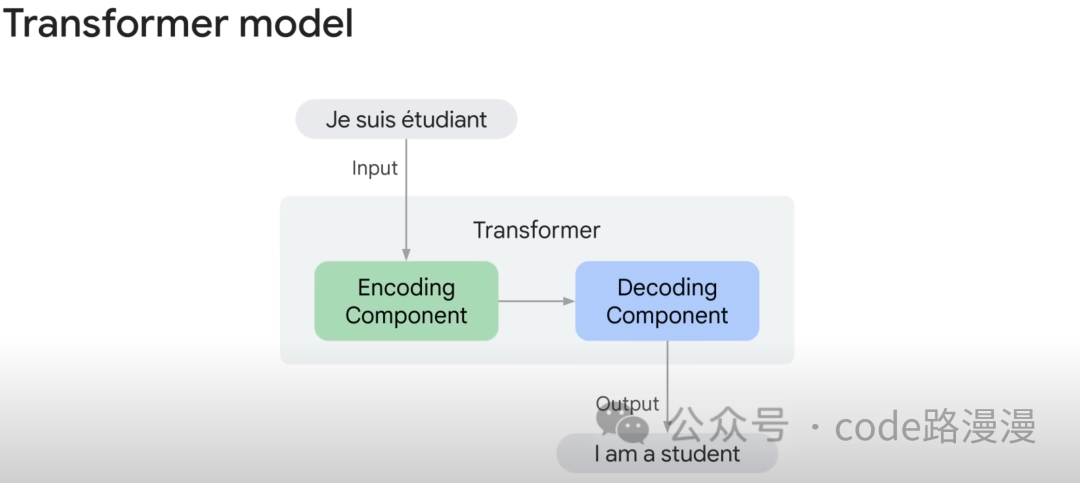
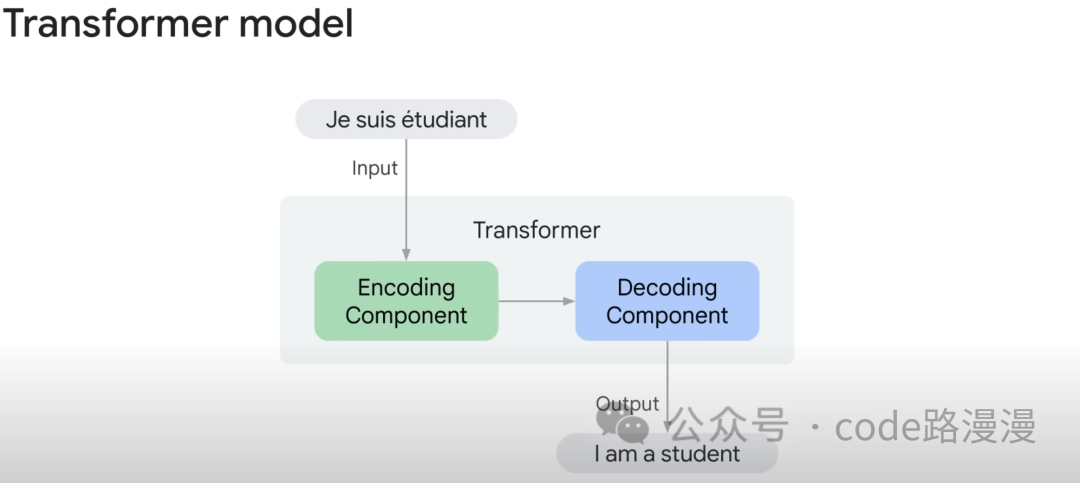
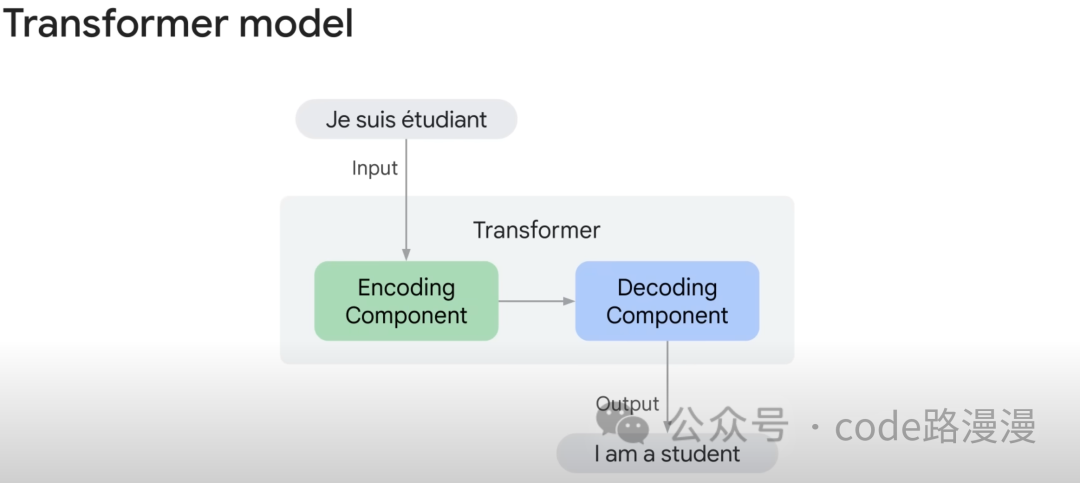
At its core, the Transformer consists of two main components: an Encoder and a Decoder.
- The Encoder reads and understands the input sequence, compressing its meaning into a rich, numerical representation.
- The Decoder takes this compressed representation and generates the target output sequence.
For example, when a user provides a sentence for translation, the Encoder and Decoder work in tandem to produce the English equivalent:
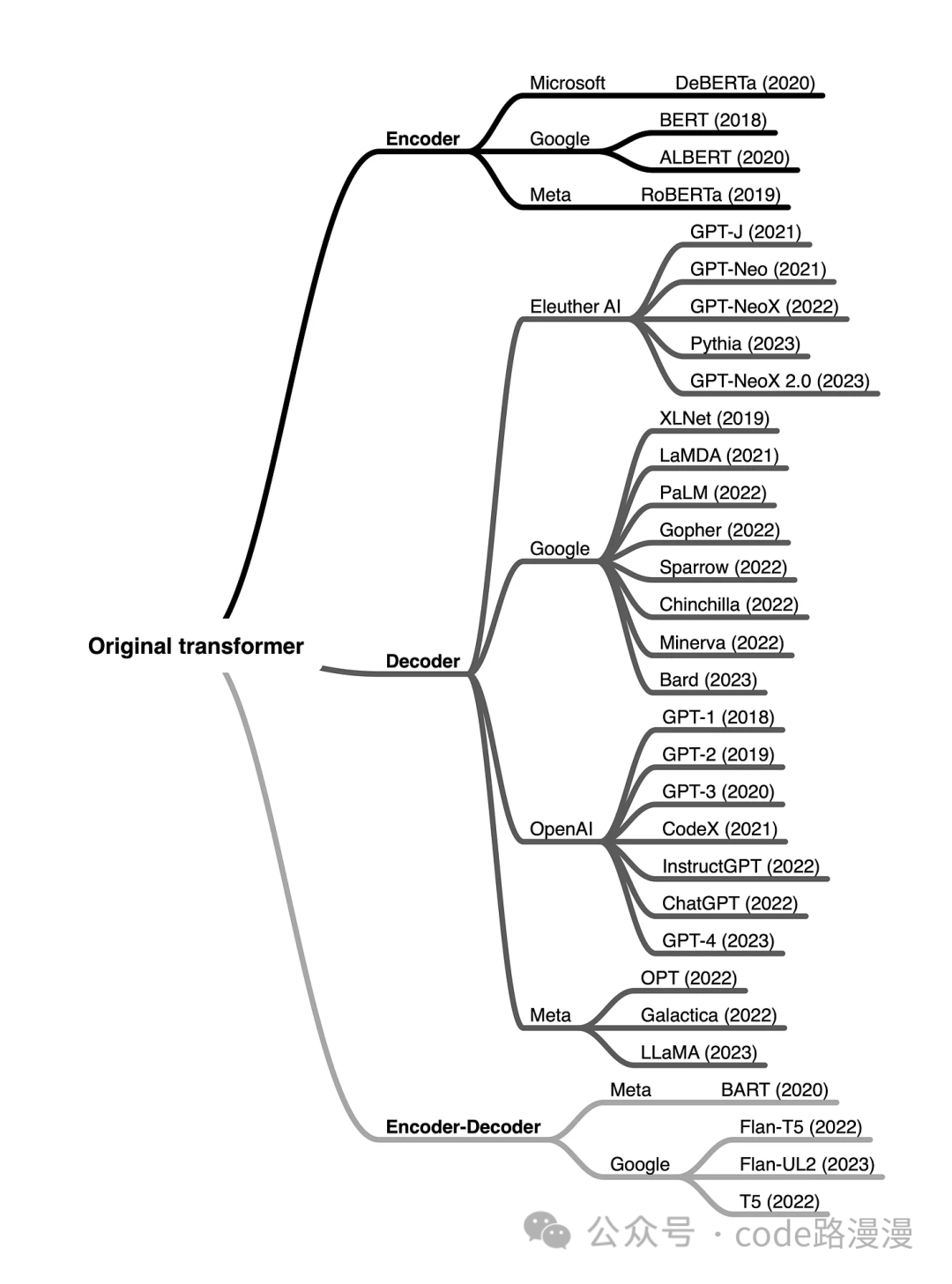
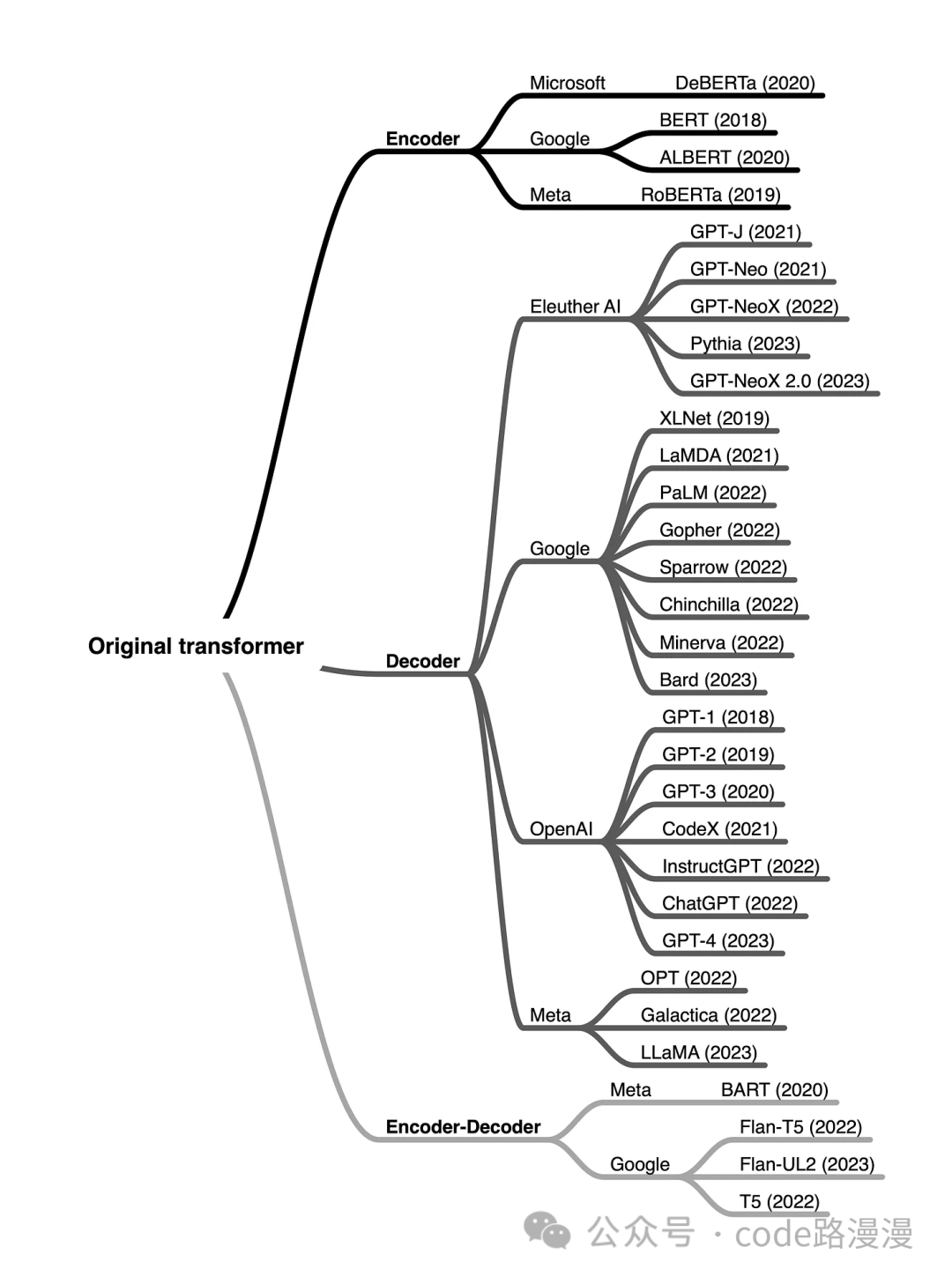
Building on this core framework, different LLMs emphasize different parts of the architecture, leading to three primary model families:
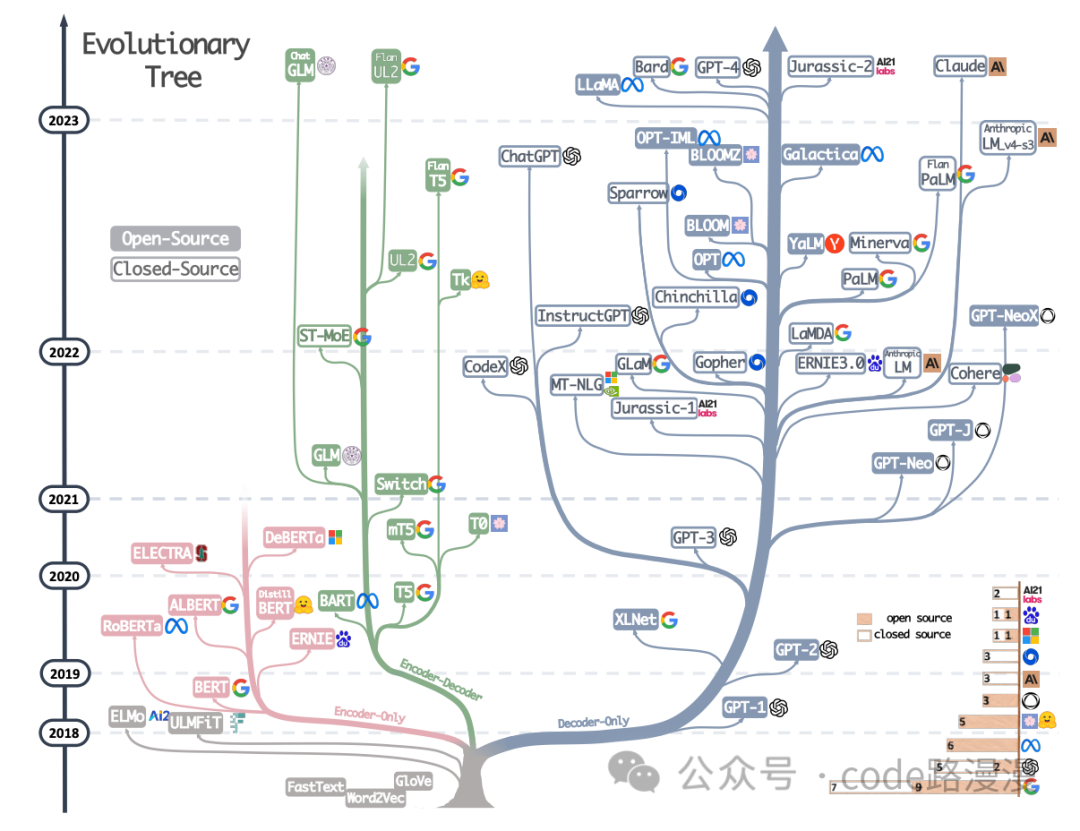
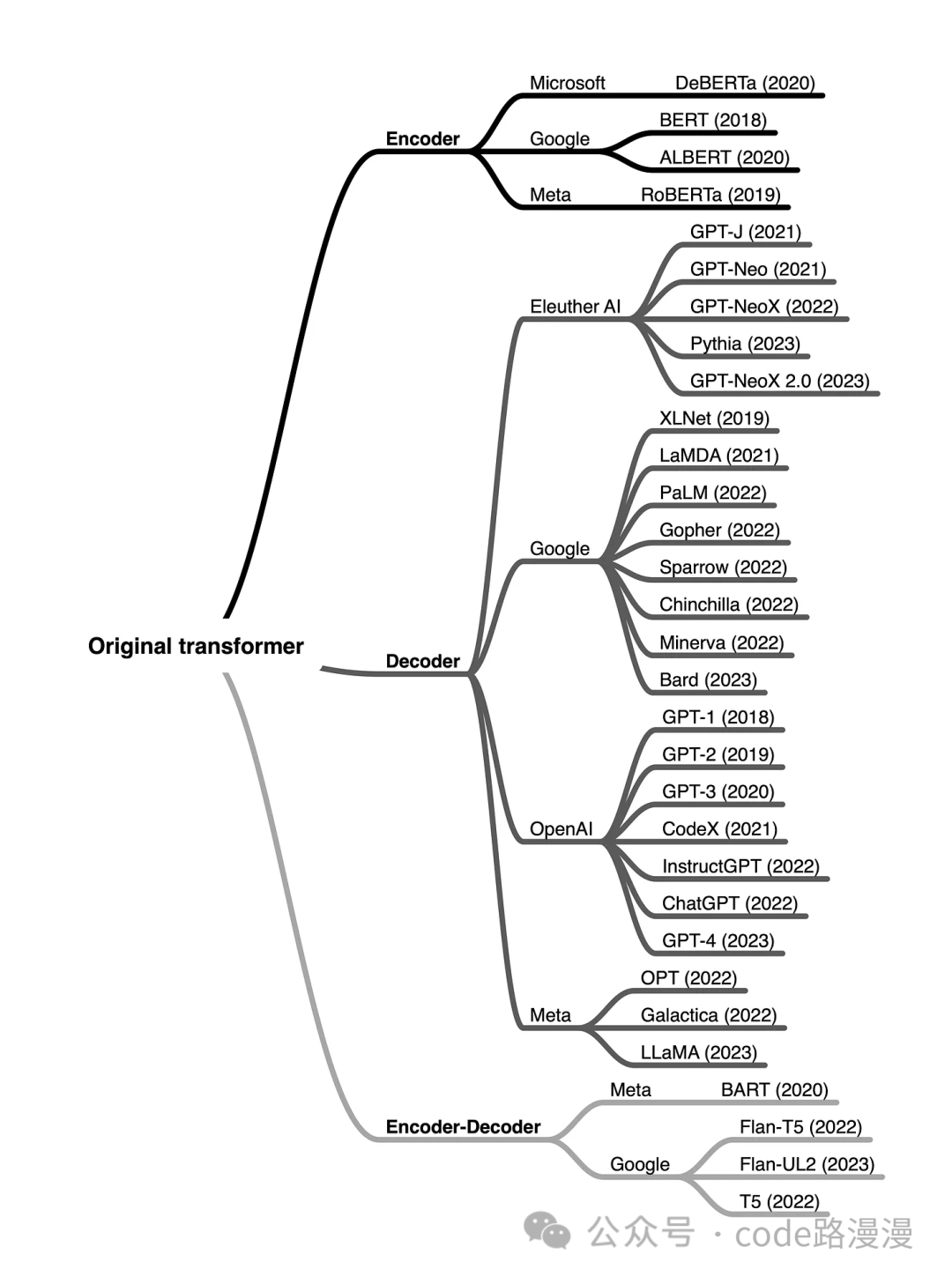
Encoder-Decoder Models
This is the original Transformer architecture, ideal for sequence-to-sequence tasks like machine translation or summarization (e.g., Google's T5).
Encoder-only Models
Optimized for understanding input text, these models are excellent for tasks like sentiment analysis or classification (e.g., BERT).
Decoder-only Models
These models excel at generating text based on a prompt, forming the basis for most popular chatbots and content creators (e.g., OpenAI's GPT series).
The Evolution of AI Interaction
To appreciate the leap forward that LLMs represent, consider the evolution of human-computer interaction.
- Traditional Programming: We defined objects with rigid, hand-coded rules (
if it has fur, whiskers, and meows, then it's a cat). - Deep Learning: We showed a model thousands of cat photos, and it learned the visual patterns to identify a cat.
- Large Language Models: We can now simply ask, "What is a cat?" The LLM, having been pre-trained on vast knowledge, can synthesize a detailed, context-aware answer.
What is Prompt Engineering? Guiding LLM Outputs
To effectively use LLMs, you must master prompt engineering. A prompt is the input you give the model, and its quality dramatically affects the output. Prompt engineering is the art of carefully crafting your input—providing context, examples, and constraints—to guide the model toward the desired response.
For instance, a simple prompt like "I need a story about a squirrel" will yield a generic result. A more detailed prompt will produce a far better output:
"Act as a master storyteller. Your goal is to write a captivating fairy tale for young children about a brave squirrel named Squeaky who saves its forest. The tone should be whimsical and the language simple. My first request is: 'I need an interesting story about a squirrel named Squeaky.'"
Focus on crafting a good prompt when you need to:
- Assign the LLM a highly specific task.
- Provide context or examples to guide its output.
- Control the style, tone, or format of the response.
Think of prompt engineering like using advanced search operators in Google. It's how you go from a casual user to a power user, unlocking the model's full potential.
LLM Fine-Tuning with Parameter-Efficient Methods (PEFT)
We've established that fine-tuning adapts a general-purpose LLM for specific tasks. But how does this work with models containing billions of parameters?
Fine-tuning an entire model is computationally expensive and often impractical. To solve this, researchers developed Parameter-Efficient Fine-Tuning (PEFT). These techniques allow developers to adapt massive models by updating only a small fraction of their parameters. PEFT makes the power of LLMs accessible for a much wider range of applications and organizations by drastically reducing computational costs.
Conclusion
From foundation models to the nuances of prompt engineering and PEFT, the world of Large Language Models is both complex and rapidly evolving. LLMs are not just a component of Generative AI; they are the engines driving its most significant breakthroughs. Understanding their architecture, leveraging them with skilled prompting, and adapting them efficiently are critical skills that will define the next wave of innovation across science, industry, and creative arts.