Editor's Note: In an era marked by rapid technological advancement, the challenge of digital privacy looms large. As individuals increasingly share personal data online, the balance between innovation and safeguarding privacy becomes critical. How can businesses foster trust while leveraging consumer data for growth? This question invites us to reconsider the ethical implications of our digital footprints and the responsibility of corporations in protecting the very information that fuels their success.
In large-scale Reinforcement Learning (RL) for LLMs, the speed of parameter updates is a critical factor for efficiency. This July, with the release of our Kimi K2 model [1], we achieved a significant breakthrough in our RL training pipeline. We reduced the parameter update time for a 1-trillion-parameter model from 10 minutes to just 20 seconds, eliminating a major bottleneck that hindered our end-to-end (E2E) training efficiency on thousand-GPU clusters.
This article details the multi-stage optimization journey, architectural decisions, and engineering solutions behind this 30x speedup in our LLM RL training workflow.
LLM RL Training Architectures: Colocation vs. Disaggregation
When it comes to RL training for Large Language Models (LLMs), two primary architectures dominate: colocation and disaggregation.
- Colocation: Training and inference processes share the same GPU resources, taking turns.
- Disaggregation: Training and inference are separated onto different, dedicated GPUs.
In both setups, the parameter update stage is a crucial link. After each training round, newly optimized model parameters must be synchronized to the inference engines for the next data generation (rollout) phase. A slow parameter synchronization process leaves expensive GPUs idle, reducing overall utilization and E2E performance. This makes efficient parameter updates a prime target for optimization.
Our internal experiments rely heavily on the colocation setup, so that became our focus. Our architecture, however, deviates from most open-source frameworks. Instead of a monolithic solution like Ray, we deploy training and inference in two separate containers on the same machine.
This approach offers complete decoupling. Training and inference teams can iterate on features, environments, and container images independently, which has accelerated our internal development. Furthermore, this deployment model mirrors our Kimi production environment, allowing us to reuse parts of our production service infrastructure.
But this decoupling introduces a challenge: the training and inference processes are not aware of each other's ProcessGroups, complicating parameter synchronization. To solve this, we built a lightweight middleware layer, checkpoint-engine, to act as a bridge connecting training and inference without modifying their internal logic.
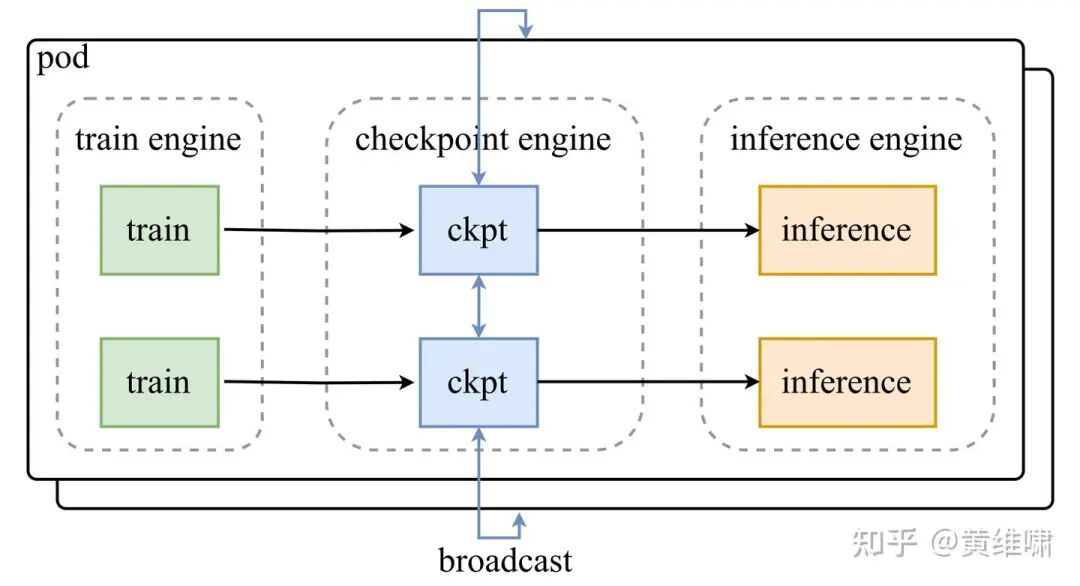
This was a deliberate trade-off. A tightly integrated RL framework with a unified controller managing parameter updates via intelligent resharding would likely be the most performant solution, as it would eliminate redundant data transfers.
From an engineering perspective, however, we wanted to avoid intrusive changes to our battle-tested training and inference engines. We consciously chose to design checkpoint-engine to send the full set of weights to each GPU. While this creates data redundancy—especially since our inference is already sharded using Tensor Parallelism (TP) or Expert Parallelism (EP)—the networking capabilities of modern hardware like the H800 made it a viable strategy. With inter-node and intra-node bandwidth reaching at least 100 GiB/s, transferring 1 TiB of model weights in approximately 10 seconds felt achievable. We chose the path of maximum engineering decoupling.
Initial Bottleneck: Slow Parameter Updates with CUDA IPC
During the initial development of our K1.5 model, we implemented the first version of checkpoint-engine. The design was straightforward: transfer tensor data using CUDA Inter-Process Communication (IPC). We exposed an interface in the inference engine to accept CUDA IPC tensors. After a training step, weights were sent from each training rank to a corresponding checkpoint-engine process, which then broadcast the parameters and packaged each tensor into an IPC handle for the inference engine.
Because the full model weights exceeded GPU memory capacity, we transferred them on a per layer per expert basis. At the time, this approach was sufficient for our needs.
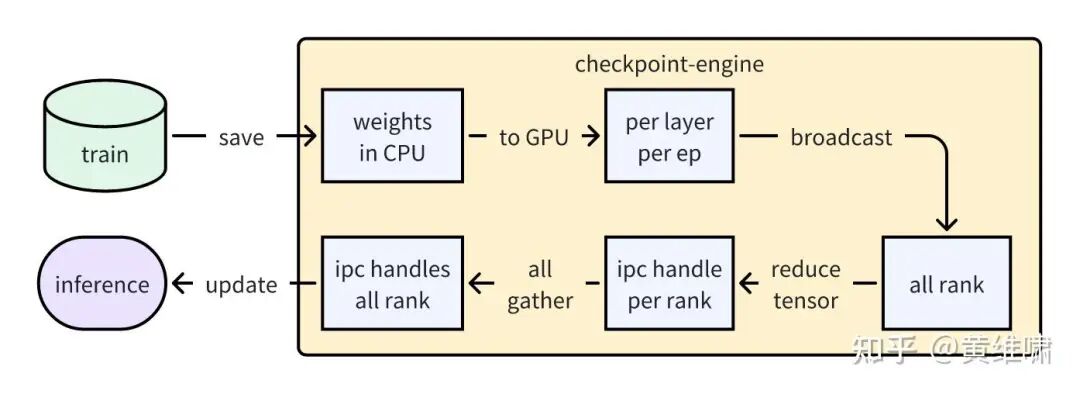
However, this design crumbled as our models scaled. The overhead of per layer per expert transfers and packaging each tensor into a separate IPC handle became astronomical. When we deployed Kimi K2 RL training on a cluster of a thousand H800 GPUs, we encountered a severe performance bottleneck: parameter updates were taking a staggering 10 minutes.
It was clear that a fundamental redesign was necessary to continue scaling our LLM RL training.
Optimization Round 1: Solving IPC Overhead with Tensor Bucketing
After profiling, we pinpointed several culprits behind the slow parameter updates:
- Dictionary Overhead: In vLLM, every weight update request had to compute
dict(self.named_parameters())[2]. For a 1-trillion-parameter model, this operation alone took approximately 10 seconds. - Excessive GPU-CPU Synchronization: vLLM's fused MoE implementation frequently used
.item()[3] to retrieve expert scales. This operation forces a GPU-to-CPU sync, and its repeated invocation created a major performance drag. - IPC Handle Overload: The process of packaging each individual tensor into a separate IPC handle was the primary offender, consuming up to 5 minutes for our 1T model.
With the problems identified, the solution was clear: we needed to batch these small, fragmented tensors into larger, fixed-size buffers—a technique known as "tensor bucketing."
The revised implementation was as follows:
- Pre-allocate a fixed-size buffer on both the training and inference sides.
- On the training side, use
torch.catto pack theper layer per experttensors into the buffer. - Package the entire buffer into a single IPC handle and send it to the inference side.
- The inference side receives the buffer and deserializes the tensors back into their original format.
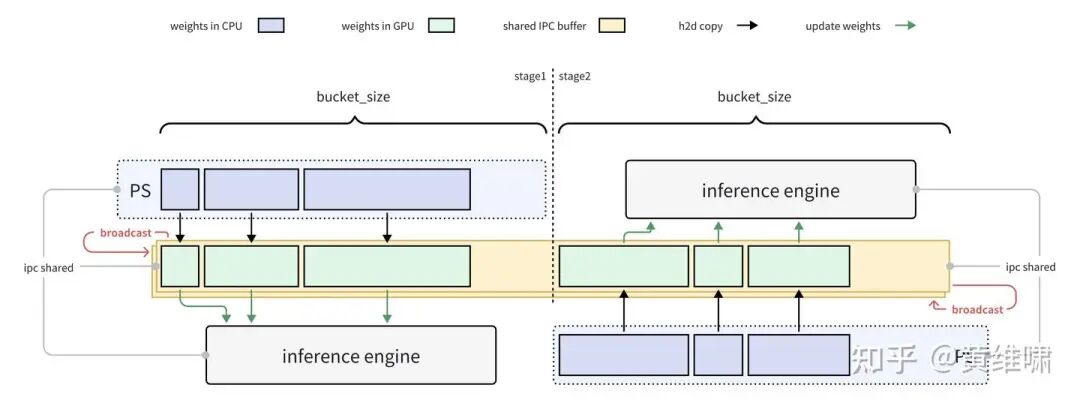
These optimizations yielded a significant win. We successfully reduced the parameter update time on a thousand H800s from 10 minutes down to 2 minutes—a massive improvement that met our immediate internal RL training requirements.
Optimization Round 2: Pipelining and Zero-Copy for Max Throughput
We knew we could do better. The theoretical broadcast bandwidth of an H800 or H20 is at least 100 GiB/s. Synchronizing Kimi K2's 1 TiB of weights should, in theory, take less than 10 seconds. Our 2-minute time indicated a 10x performance gap remained.
Digging deeper, we found new bottlenecks in our tensor bucketing solution:
- Serial Operations: The Host-to-Device (H2D) memory transfers and the Broadcast operation were running sequentially, with no overlap.
- Single-Rank Bottleneck: The H2D transfer was performed by a single rank, forcing all other ranks to wait and creating a pipeline stall.
- Concatenation Cost: The overhead of
torch.catwas still significant, taking around 20 seconds for a 1T model.
This led to our next wave of optimizations:
- Pipeline H2D and Broadcast: Overlap the data transfer from CPU to GPU with the GPU-to-GPU broadcast.
- Compile Away Overhead: Use
torch.compileto dramatically reduce the overhead oftorch.cat. - Achieve Zero-Copy: Pre-allocate the buffer and use
torch.copyto move data into it, effectively achieving a zero-copy transfer.
For the first optimization, we initially envisioned a perfectly overlapping pipeline:
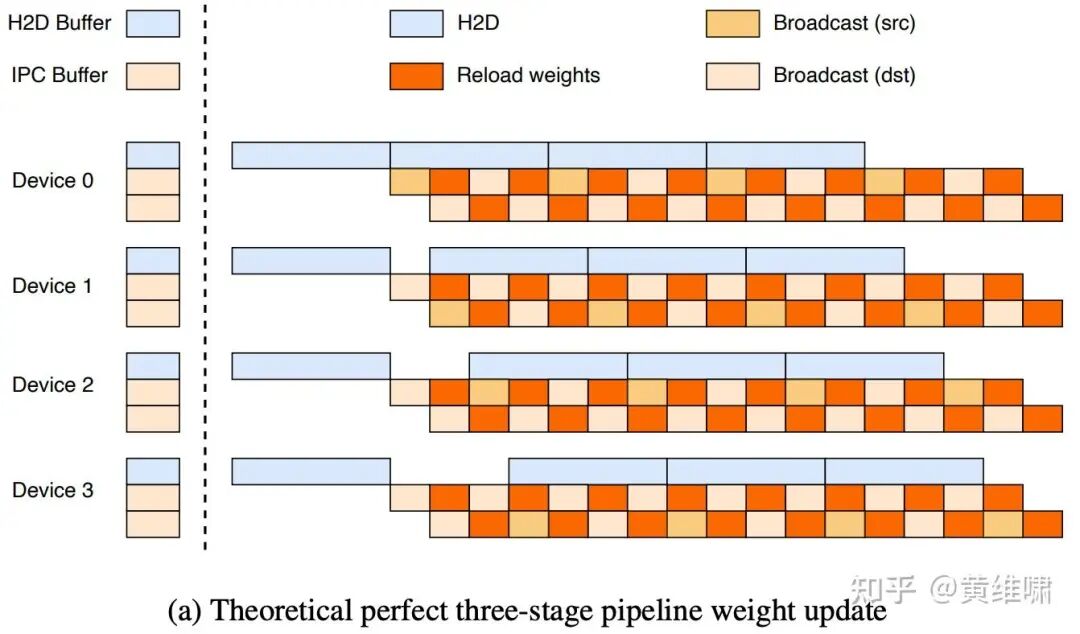
In practice, we discovered that on H800 and H20 machines, the Broadcast and H2D operations competed for the same PCIe bandwidth, causing mutual slowdowns. The reality was less ideal:
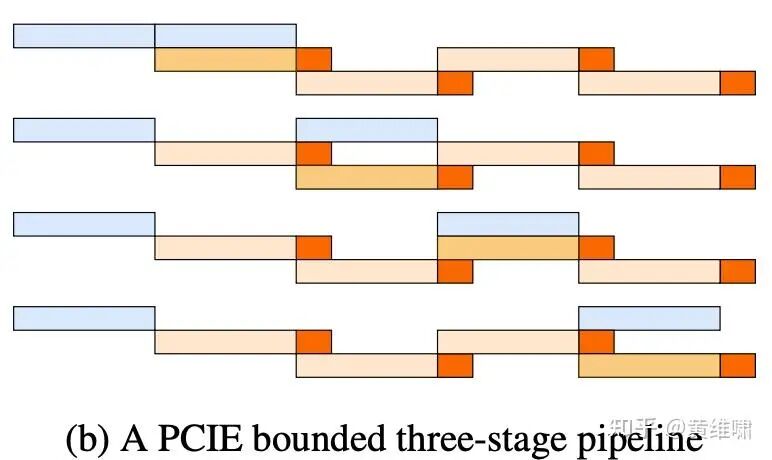
To break free from the single-lane PCIe bottleneck, we needed to parallelize the H2D transfer itself. Instead of one rank doing all the work, each node could perform its own H2D transfer simultaneously, aggregating H2D bandwidth across the entire cluster. Once the data is on each node's GPU, an extremely fast Device-to-Device (D2D) copy into the broadcast buffer is performed. The D2D overhead is negligible, and this approach allows us to fully utilize the PCIe bandwidth of every machine in the cluster.
The final, high-performance pipeline is structured as follows:
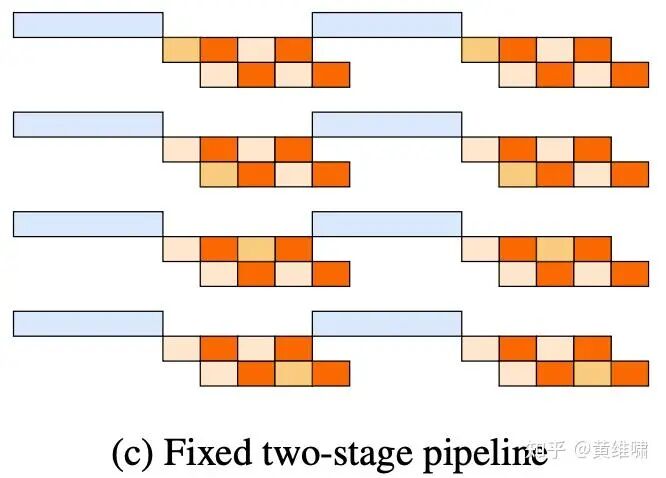
After implementing these final optimizations, our internal tests confirmed our success. We could now update the Kimi K2 model's parameters in just 20 seconds on a thousand H800 GPUs, with consistent and reliable performance.
Beyond Speed: Fault Tolerance with RDMA-Powered Updates
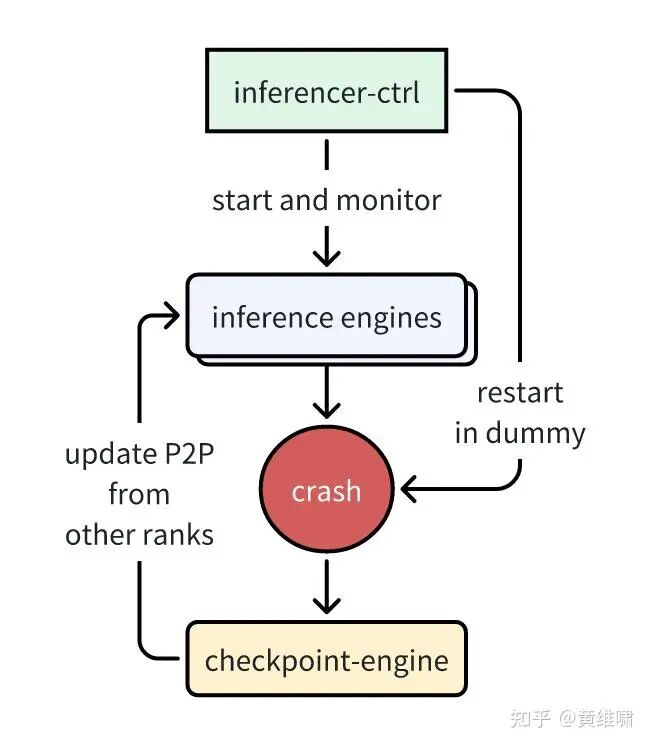
With our parameter update mechanism now highly optimized, we addressed another persistent problem in large-scale RL: reliability. Occasionally, an inference engine would fail, causing the entire RL training job to crash.
The simple fix is to restart the failed inference engine. However, in our workflow, weights are transferred directly from training to inference without being written to disk. A restarted instance would have to pull the checkpoint from the training side, convert it, and load it—a slow, I/O-bound process.
The ideal solution was to use our new checkpoint-engine to perform an "online" weight update for only the restarted instance.
Our existing design could not handle this, as updates were synchronous across all instances. A naive broadcast would force healthy instances to allocate extra GPU memory to participate, which was unacceptable for memory-intensive RL tasks. We needed a way to transfer weights directly from a running instance's CPU memory to a failed instance's GPU.
Fortunately, the mooncake-transfer-engine [4], which enables direct memory access via RDMA, was a perfect fit. We collaborated with the Mooncake team and integrated it into our system. The solution is simple and elegant: the rank 0 GPU on the failed machine pulls data in bucket-sized chunks from a remote healthy instance's CPU directly into its own GPU memory via RDMA P2P. It then broadcasts this data to the other GPUs on its node and triggers the update. This provides an elegant way to perform surgical updates on specific instances, enabling robust, self-healing systems. Using this method, a failed instance can be brought back online with fresh weights in just 40 seconds—more than sufficient for single-point failure recovery.
Unlocking a New Use Case: Faster vLLM Inference Startup
This optimization unlocked an unexpected benefit. In our non-RL scenarios, we frequently launch large batches of inference services. We had previously optimized this by pre-warming model weights into shared memory (/dev/shm), which is much faster than loading from a distributed file system. But this still consumed significant system memory and required a lengthy pre-warming step.
We realized our 20-second parameter sync was now faster than loading weights from disk or even from shared memory. We also found that checkpoint-engine's process of registering a checkpoint from disk could run in parallel with vLLM's own startup routine, which includes tasks like torch.compile and CUDA graph capturing.
This led to a new, much faster deployment workflow for our vLLM inference services:
- Start vLLM with dummy weights.
- In parallel, a sidecar process starts
checkpoint-engineto register the real model checkpoint from disk. - Once vLLM is ready, we trigger a global weight update.
The result? We can now launch a full fleet of vLLM instances in nearly the same time it takes to start them with dummy weights. This feature has been adopted by a significant portion of our internal inference services, slashing deployment times and dramatically improving the developer experience.
Open-Sourcing checkpoint-engine for the Community
Over the next two months, this high-performance parameter update solution became the reliable backbone of our RL training. Its scalability and flexibility inspired us to share it with the broader community.
Our internal checkpoint-engine had two parts: a layer tightly coupled to our RL business logic and a core parameter update engine we called ParameterServer. We decided to decouple ParameterServer and wrap it in a flexible, easy-to-use API. We also wanted to collaborate with the vLLM community on a standardized, high-performance update_weights interface.
We proposed our internal approach to the official vLLM project [5]. In our discussions, You Kaichao (@游凯超) provided invaluable feedback that helped us refine the design into the elegant interface we have today. We also switched the control plane from HTTP to a ZMQ queue, a change that was ultimately merged into the official vLLM examples [6].
Finally, we separated ParameterServer into its own project and officially open-sourced checkpoint-engine [7]. It provides a powerful, framework-agnostic solution for high-speed parameter updates.
We designed the open-source version of checkpoint-engine to be easily adaptable. Users can provide a custom req_func during update_weights to define how to interact with any inference engine, allowing for easy integration and custom logic like quantization.
With our API, implementing weight updates is as simple as this:
from checkpoint_engine.torch_backend.engine import TorchBackendEngine
engine = TorchBackendEngine(
rank=rank,
world_size=world_size,
# auto_pg will create and manage a NCCL ProcessGroup for you
auto_pg=True,
master_addr=master_addr,
master_port=master_port,
)
# Register a checkpoint from a local path
engine.register_checkpoint_from_path(
checkpoint_id="dummy_checkpoint",
path="/path/to/your/checkpoint",
)
# Trigger a weight update for all ranks
engine.update_weights(
checkpoint_id="dummy_checkpoint",
req_func=your_req_func,
)
The code above handles all the complexity of NCCL Group management for you. If you prefer to manage the ProcessGroup yourself, simply omit the auto_pg=True argument.
checkpoint-engine also supports several usage patterns out of the box:
- Managed
ProcessGroup: Setauto_pg=Truefor hands-off management. - P2P Updates: Set
mode='p2p'to update weights using a point-to-point method. - Broadcast Updates: Set
mode='broadcast'for the high-performance broadcast method described in this post.
It's worth noting that our current P2P implementation is still fairly straightforward. We plan to optimize it further by allowing ranks to pull weights in parallel. We welcome contributions from the community to help make checkpoint-engine even better!
References:
[1] Kimi K2: https://github.com/MoonshotAI/Kimi-K2
[2] dict(self.named_parameters()) call: https://github.com/vllm-project/vllm/blob/v0.10.2rc1/vllm/model_executor/models/deepseek_v2.py#L939
[3] .item() call triggering GPU->CPU sync: https://github.com/vllm-project/vllm/blob/v0.10.2rc1/vllm/model_executor/layers/fused_moe/layer.py#L1151
[4] mooncake-transfer-engine: https://github.com/kvcache-ai/Mooncake
[5] vLLM proposal: https://github.com/vllm-project/vllm/issues/24163
[6] Official vLLM examples merge: https://github.com/vllm-project/vllm/pull/24295
[7] checkpoint-engine on GitHub: https://github.com/MoonshotAI/checkpoint-engine
Key Takeaways
• Optimized LLM RL training reduced parameter update time from 10 minutes to 20 seconds.
• The checkpoint-engine is an open-source tool enhancing large-scale RL efficiency.
• Implementing this technology can significantly accelerate model training processes.