Qwen3 Model Family: QK-Norm and Enhanced Attention Mechanism
The Qwen3 model family, Alibaba's latest large language model release, introduces a significant upgrade for on-device AI: the adoption of QK-Norm in its attention mechanism. While Qwen3's new 'Think' capabilities are widely discussed, the transition from QKV-bias to QK-Norm is a crucial improvement for stable and efficient inference on edge devices.
What is QK-Norm in Qwen3's Attention Mechanism?
According to the official release notes:
"Besides, we remove QKV-bias used in Qwen2 (Yang et al., 2024a) and introduce QK-Norm (Dehghani et al., 2023) to the attention mechanism to ensure stable training for Qwen3."
Qwen3 replaces the QKV-bias mechanism from previous versions with QK-Norm, a normalization technique applied to the query (Q) and key (K) vectors in the attention module. This change ensures numerical stability during both training and inference, especially when using lower-precision formats like FP16 (float16).
Why QK-Norm Matters for On-Device AI and FP16 Inference
Deploying large language models to edge devices often requires using FP16 for faster computation and reduced memory usage. However, numerical overflow can occur during the query @ key matrix multiplication in the attention mechanism, particularly with Qwen2 models. This happens because FP16 has a narrower dynamic range compared to bfloat16, which is commonly used during training.
Real-World Example: Overflow in Qwen2 FP16 Inference
When deploying the Qwen2-1.5B-Instruct model on an edge device with MNN and FP16 precision, invalid outputs were observed due to overflow in the attention calculation. Layer-by-layer analysis traced the issue to the query @ key operation.
To address this, the scaling factor was applied earlier in the computation, changing from (q @ k) / scale to q / scale @ k. This method, also used in PyTorch's Scaled Dot-Product Attention (SDPA), helps prevent overflow:
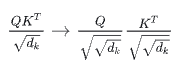
Comparative Analysis: Qwen1, Qwen2, and Qwen3
Testing revealed that Qwen2 was particularly prone to FP16 overflow, while Qwen1 was less affected. With the introduction of QK-Norm in Qwen3, numerical stability is significantly improved. Comparative analysis across all three generations, logging maximum values for QKV-bias and q@k results in each attention layer, demonstrates Qwen3's enhanced stability:
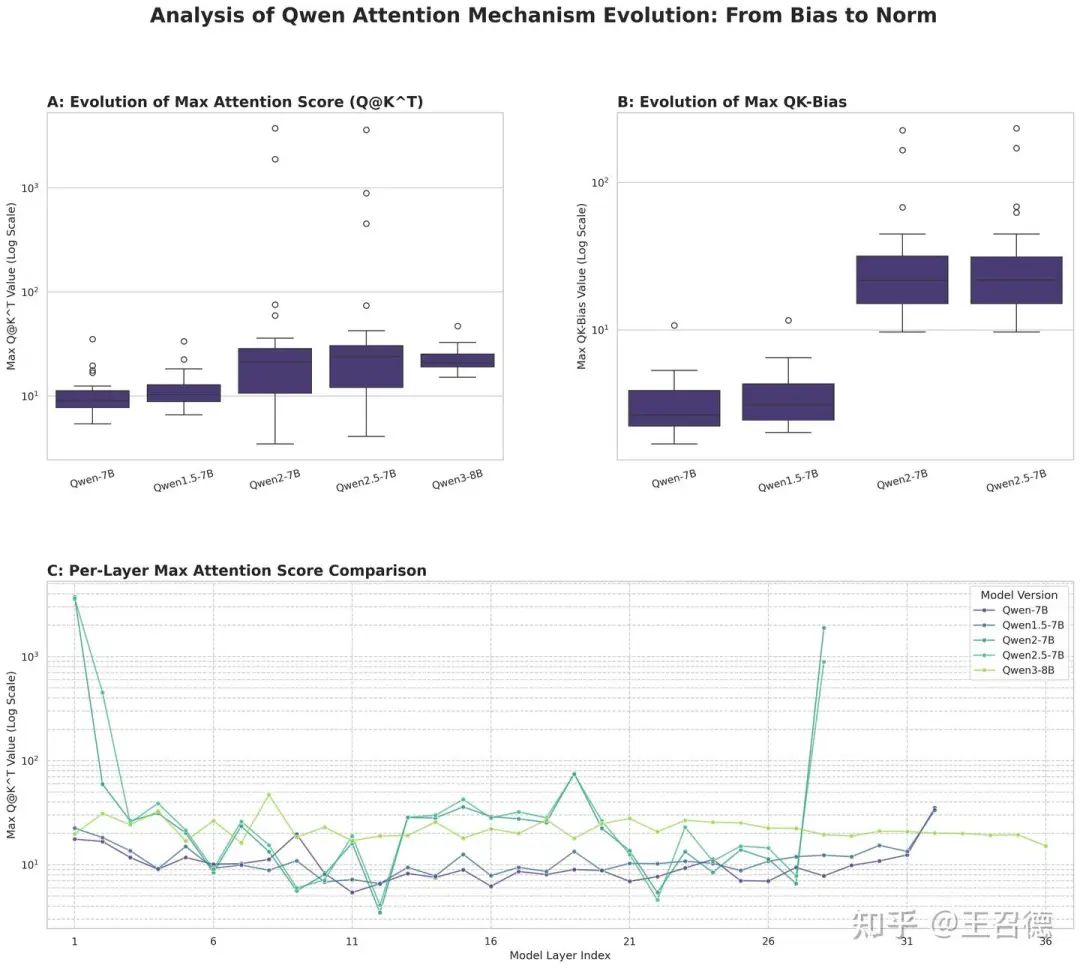
Key Benefits of QK-Norm in Qwen3
- Prevents FP16 Overflow: Normalizing Q and K vectors before the dot product reduces the risk of numerical overflow during inference.
- Improves Numerical Stability: Ensures reliable outputs on edge devices using float16 precision.
- Optimized for Edge Deployment: Makes Qwen3 a robust choice for resource-constrained, real-world applications.
For practitioners seeking stable on-device AI, Qwen3's QK-Norm attention mechanism is a meaningful architectural advancement.
Explore the Test Code for further details and implementation examples.