Why Direct Reinforcement Learning on Base Language Models is the Next Frontier
Direct reinforcement learning (RL) on base language models is emerging as a transformative approach in LLM optimization. Unlike the traditional supervised fine-tuning (SFT) followed by RL, this 'zero-RL' method applies RL directly to base models, reframing the optimization process. Instead of a pure RL problem, it becomes a matter of efficiently sampling from the optimal distribution, similar to energy-based models (EBMs). This perspective expands available techniques, leveraging both RL and generative modeling advancements.
Historically, direct RL on base models was limited by vast search spaces and early model capabilities. Initial attempts using Proximal Policy Optimization (PPO) with rule-based reward models on SFT models showed only modest gains, especially for smaller models. Consequently, direct reinforcement learning on base language models was often deprioritized in favor of other optimization strategies.
The Evolution of Base Models: Why Zero-RL is Now Feasible
Recent improvements in pre-training—such as enhanced reasoning data and higher-quality datasets—have significantly boosted the zero-shot performance of base language models. Modern base models now match or exceed the capabilities of earlier instruction-tuned models, making direct RL on base models a practical and promising strategy for LLM optimization.
A preliminary 'sanity check' using REINFORCE++ on a 32B base model confirmed the viability of zero-RL, paving the way for more extensive experiments.
Revisiting RL Algorithms for Modern LLM Training
Traditional RL algorithms like Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC) were designed for multi-step environments. However, large language model (LLM) training typically involves single-step reward feedback, similar to a multi-armed bandit problem. Modern LLMs, after extensive pre-training, often display proto-instruction-following behavior, raising questions about the necessity of complex stability techniques developed for randomly initialized models. Early findings indicate that while these methods can help, they are not always essential in this context.
From a generative modeling perspective, if RL-based optimization is effective, alternative methods such as Markov Chain Monte Carlo (MCMC) sampling could also be relevant. The effectiveness of these techniques for modern LLMs is still under investigation.
Open-source projects like simple-reason-rl and tiny-zero have shown promise with zero-RL approaches. However, a systematic evaluation of foundational RL principles is needed to identify the most effective techniques for LLMs and verified reward models. Access to diverse internal checkpoints from various pre-training stages is a significant advantage for studying zero-RL scaling laws and iterative model improvement.
Experimental Insights: Zero-RL in Practice
A series of experiments evaluated zero-RL using a 7B parameter base model. The training data comprised math prompts of moderate difficulty, with the following reward scheme:
- Correct Answer: +1.0
- Incorrect Format: -1.0
- Wrong Answer (correct format): 0 or -0.5 (minimal impact on trends)
The results were compelling. Removing the Kullback-Leibler (KL) divergence constraint (by setting init_kl_coef=0 in OpenRLHF) led to steady increases in both reward and response length.
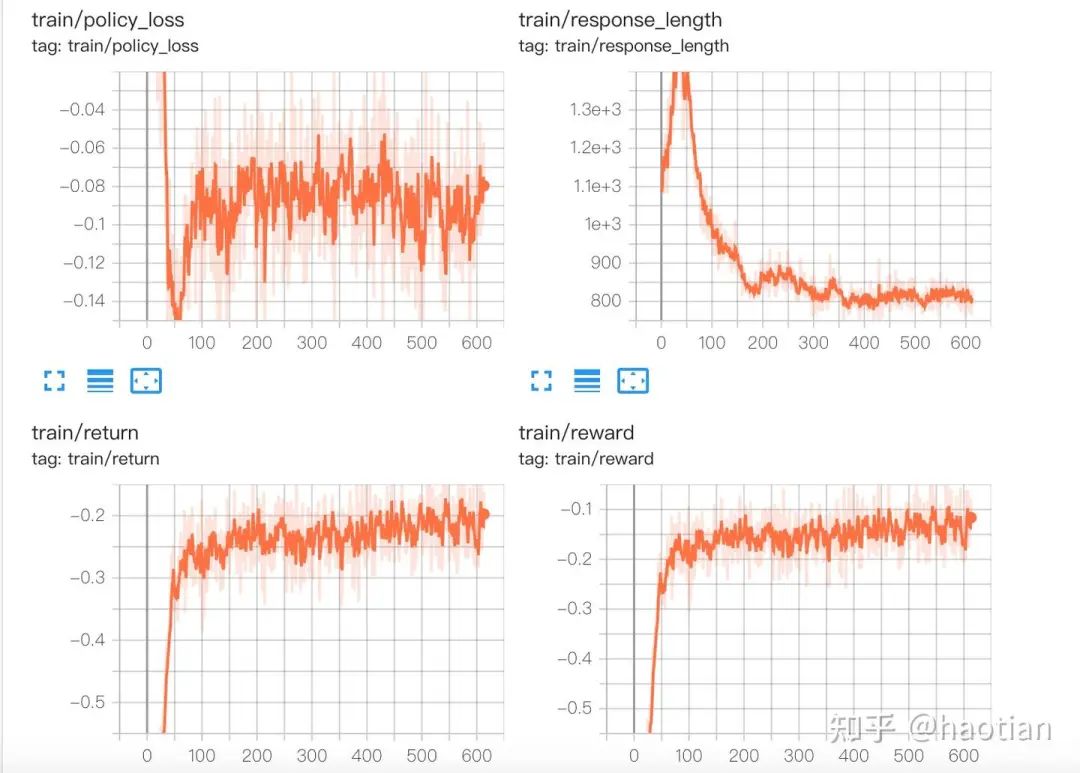
Reintroducing the KL constraint caused performance to plateau, with response length stagnating.
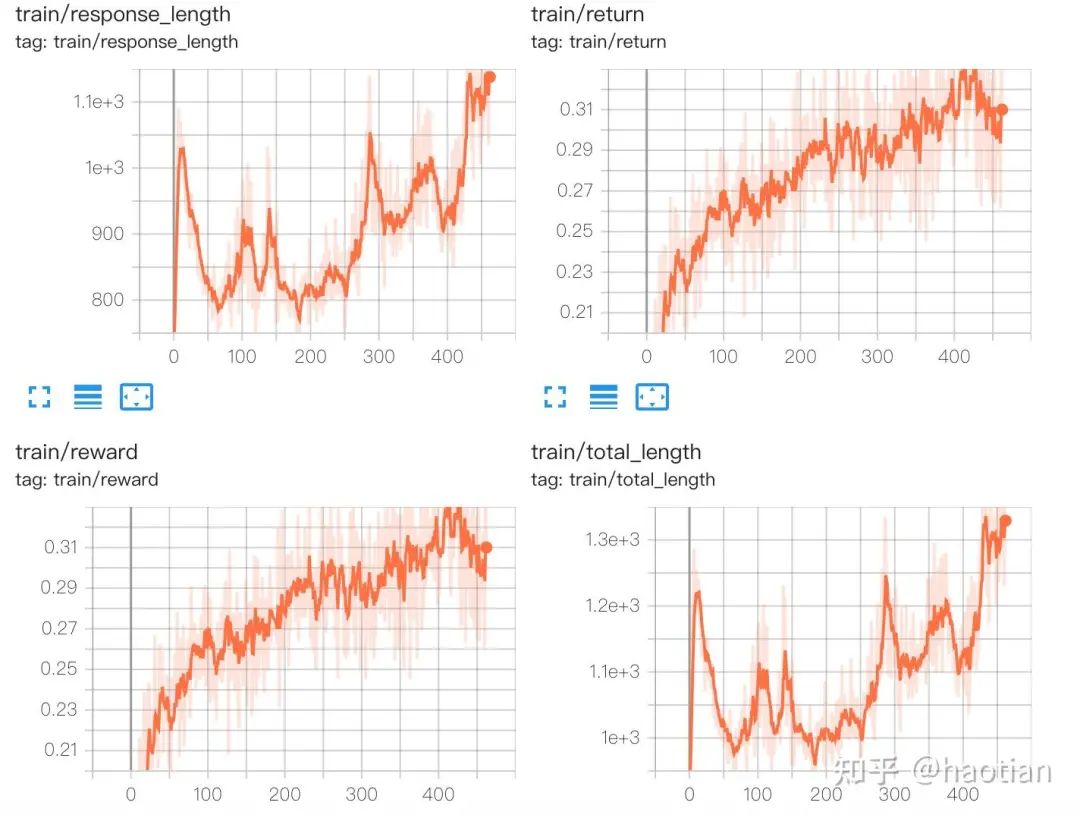
Using the basic REINFORCE algorithm without KL constraint, even a 7B base model showed continuous, stable growth with less saturation. In contrast, KL-constrained methods like REINFORCE++ and RLOO plateaued across models from 7B to 32B parameters, with response length initially rising, then falling and stabilizing regardless of prompt template.
Evaluation metrics confirmed these trends: the unconstrained REINFORCE model exhibited healthy growth, while the KL-constrained variant plateaued after about 100 steps.
Notably, removing the KL constraint slightly decreased training set reward, possibly due to the model tackling more challenging problems. The challenge remains to maintain stable growth without KL regularization. Alternative stabilization methods, such as policy Exponential Moving Average (EMA) and new advantage calculation techniques, are under exploration.
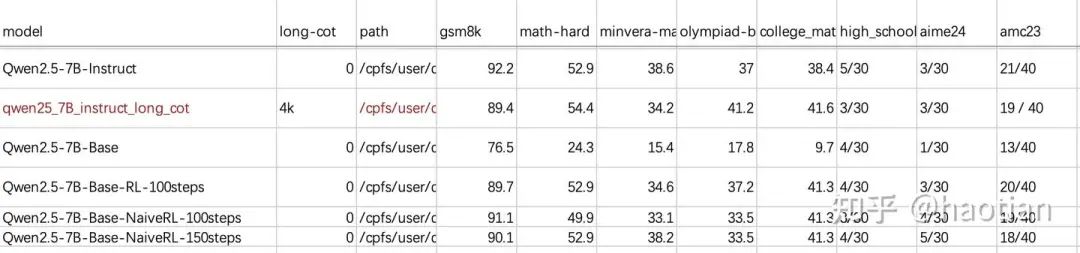
A further limitation is the slow evaluation of multiple benchmarks during training, highlighting the need for efficient online policy evaluation—especially important given the stochastic nature of prompts and sampling.
Future Directions and Open Challenges in Direct RL for Base Models
Re-examining classical RL methods with advanced base language models can drive major breakthroughs in LLM optimization. Key next steps include developing RL frameworks that enable true environmental interaction, potentially through complex, asynchronous environments. Such advancements are essential for building more capable reasoning agents.
Platforms like OpenRLHF and VERL offer flexibility to explore alternative optimization and sampling methods, including those inspired by energy-based models. This area remains highly promising for future research and innovation.