Qwen3 Training Pipeline: Pre-training, Reinforcement Learning, and Model Distillation
Qwen3 Pre-training: Building a Robust Foundation
Qwen3 training begins with a comprehensive three-stage pre-training process, designed to establish a strong base in general knowledge, advanced reasoning, and long-context adaptation.
1. Foundational Knowledge Training
- Utilizes a massive 30T token dataset across 119 languages and dialects, processed with a 4096-token sequence length.
- Focuses on mastering linguistic structures, grammar, common sense, and broad world knowledge.
- Establishes a versatile multilingual foundation for subsequent specialized training.
2. Specialized Reasoning Training
- Employs a 5T token dataset with a 4096-token sequence length and a faster learning rate decay.
- Increases the proportion of STEM, coding, and logical reasoning data, including high-quality synthetic data.
- Enhances Qwen3's problem-solving and analytical skills.
3. Long-Context Adaptation
- Extends the model's attention span using a 10B token dataset and a 32,768-token sequence length.
- 75% of training text ranges from 16K to 32K tokens; 25% ranges from 4K to 16K tokens.
- Integrates advanced techniques: Asymmetric Bidirectional Fusion (ABF), Yet Another Recurrent Network (YARN), and Dual-Chunk Attention (DCA) for efficient long-context processing.
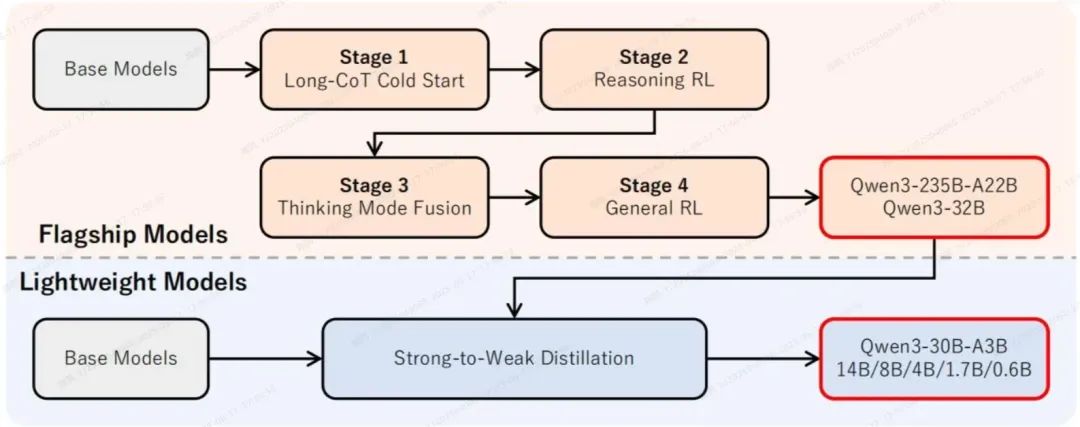
Qwen3 Post-training: From Knowledge to Intelligence
Chain-of-Thought (CoT) Cold Start
- Objective: Instill foundational step-by-step reasoning using a diverse dataset spanning mathematics, code, logical puzzles, and STEM problems.
- Dataset: Each problem includes a verified step-by-step solution or code-based test cases.
- Query Filtering: A large model filters out unverifiable or unsuitable queries, ensuring balanced domain coverage.
- Response Filtering: Candidate responses are rigorously filtered to ensure correctness, eliminate redundancy, and prevent data contamination.
Reinforcement Learning for Reasoning
- Uses a challenging dataset of 3,995 data pairs not seen during the cold start.
- Employs the GRPO (Generalized Rejection Sampling-based Policy Optimization) algorithm.
- Utilizes large batches, parallel multi-rollout exploration, dynamic entropy control, and off-policy training for efficient learning.
Thought Mode Fusion
- Integrates both step-by-step reasoning and direct answering capabilities.
- Applies Supervised Fine-Tuning (SFT) to fuse "thinking" and "non-thinking" modes.
- Introduces
/thinkand/no_thinktags to toggle response modes, preserving consistent input structure.
General-Purpose Reinforcement Learning
- Refines Qwen3 into a versatile assistant using a comprehensive reward system covering over 20 tasks.
- Focuses on instruction following, format adherence (including
/thinkand/no_thinktags), preference alignment, agent capabilities, and specialized scenarios like Retrieval-Augmented Generation (RAG). - Combines rule-based and model-based rewards for robust output evaluation.
Model Distillation
- Off-policy distillation: Student models imitate teacher responses in both thinking and non-thinking modes.
- On-policy distillation: Minimizes KL divergence between student and teacher logits, aligning internal reasoning processes.
Additional Qwen3 Training Details
Performance Insights
- Model distillation outperforms reinforcement learning on math and programming benchmarks, achieving superior results with only one-tenth of the GPU computation time.
- Later stages of thought mode fusion and general-purpose RL yield limited gains for knowledge- and STEM-heavy tasks, highlighting the efficiency of targeted early training.
Data Synthesis
- Qwen2.5-VL is used for advanced text recognition from images.
- Specialized vertical domain models synthesize high-quality, domain-specific data.
Key Qwen3 Architecture Parameters and Techniques
- Incorporates Grouped-Query Attention (GQA), SwiGLU, Rotary Position Embedding (RoPE), and RMSNorm.
- Introduces QK-Norm for training stability.
- Mixture-of-Experts (MoE) model uses fine-grained expert segmentation and global batch load balancing loss.
- Qwen3 MoE architecture features 128 experts, activating 8 experts per token with no shared experts.
Qwen3 Training Workflow Overview
The Qwen3 training pipeline flows as follows:
- Three-Stage Pre-training
- Chain-of-Thought Cold Start
- Reinforcement Learning for Reasoning
- Thought Mode Fusion
- General-Purpose Reinforcement Learning
- Model Distillation to smaller, efficient models
For more on advanced model architectures, see Qwen3 Mixture-of-Experts Explained and Understanding Rotary Position Embedding.