Fine-Tuning Qwen3 with Unsloth: Step-by-Step Guide
Qwen3, the latest generation of large language models, is redefining AI with advanced reasoning, instruction following, and robust multilingual support. With Unsloth, developers can fine-tune Qwen3 models at unprecedented speed and efficiency—even on limited hardware.
Why Fine-Tune Qwen3 with Unsloth?
The latest Qwen3 models set new benchmarks in reasoning, instruction following, and multilingual capabilities. Unsloth enables you to fine-tune these models at twice the speed and with 70% less memory, supporting an 8x longer context length compared to traditional methods.
Balancing Reasoning and Conversation in Qwen3 Fine-Tuning
Qwen3 operates in both reasoning and conversational modes. The challenge: fine-tune for conversation without sacrificing reasoning skills. Training exclusively on conversational data can diminish Qwen3's logical performance.
Optimal Data Mix:
- 75% reasoning data
- 25% conversational data
This ratio preserves analytical performance while enhancing conversational fluency. Adjust as needed for your application.
1. Install Dependencies for LoRA Fine-Tuning
We'll use Low-Rank Adaptation (LoRA) for efficient Qwen3 fine-tuning. LoRA introduces trainable low-rank matrices into each model layer, updating only a small subset of parameters (1-10%). This reduces memory and computation requirements while maintaining performance.
2. Prepare Your Qwen3 Training Data
To leverage Qwen3's dual-mode capability, blend two datasets:
Reasoning Dataset
- Open Math Reasoning dataset (AIMO Progress Prize 2 winner)
- 10% sample of DeepSeek R1's verifiable reasoning trajectories (95%+ accuracy)
Conversational Dataset
- FineTome-100k by Maxime Labonne (ShareGPT format)
- Convert to Hugging Face's multi-turn conversation format
Target dataset structure:
Processing reasoning data:

Standardizing chat data with Unsloth:

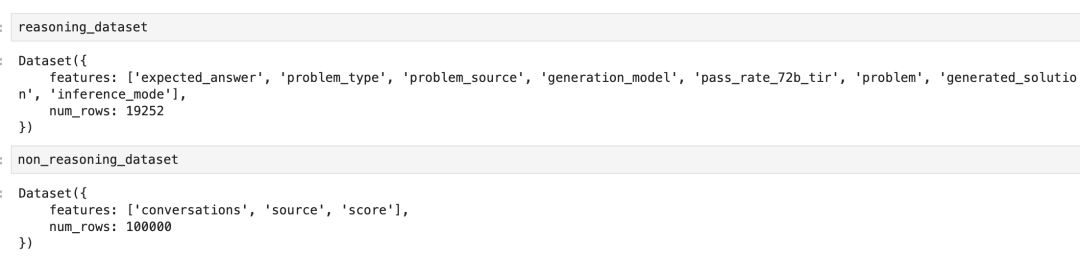
Dataset balance check:
- 19,252 reasoning examples
- 100,000 chat examples
To prevent reasoning skills from being diluted, mix datasets at a 75:25 reasoning-to-chat ratio.
3. Train Qwen3 Using SFTTrainer
Use Hugging Face's TRL library and the SFTTrainer for training. For demonstration, run for 60 steps. For full training, set num_train_epochs=1 and max_steps=None to train on the entire dataset.
4. Run Inference with Your Fine-Tuned Qwen3 Model
Unsloth's inference API makes testing easy. Adjust parameters for different modes:
- Reasoning Mode:
temperature=0.6, top_p=0.95, top_k=20 - Conversational Mode:
temperature=0.7, top_p=0.8, top_k=20
To activate reasoning, set enable_thinking=True. The model's step-by-step reasoning will be more explicit in this mode.
Saving Your Fine-Tuned Qwen3 Model
Save Only LoRA Adapters
This saves just the adapter weights (not the full base model). For a complete, standalone model, see the next steps.
Merge and Save in float16 Format
Merge LoRA adapters with the base model and save in float16. Backup of adapters is also saved. Toggle code blocks by changing if False to if True.
Merge and Save in GGUF Format
For compatibility with tools like llama.cpp, Jan, and Open WebUI, save in GGUF format. Unsloth supports quantization methods like q8_0 and q4_k_m.
You can now load quantized model files (e.g., model-unsloth.gguf, model-unsloth-Q4_K_M.gguf) into any GGUF-compatible application.
Next Steps: Customizing Qwen3 for Your Needs
You've successfully fine-tuned a Qwen3 model with Unsloth. For best results, continue testing and iterating with your own domain-specific datasets and evaluation metrics. Explore further by integrating custom data and leveraging the Hugging Face and Unsloth ecosystems.
Related Reading: