How to Choose the Right ldmatrix Operation in CUTLASS CuTe
CUTLASS CuTe is a high-performance library for matrix computations on NVIDIA GPUs. Selecting the optimal ldmatrix operation is crucial for efficient data movement between Shared Memory and Registers, especially in GEMM pipelines. This guide explains how your TiledMMA configuration and the logical layout of your input matrix in Shared Memory determine the best Copy_Operation for wrapping the ldmatrix instruction.
All examples use CUTLASS version 3.5 on an NVIDIA A100 GPU (Compute Capability 8.0).
Prerequisite: Familiarity with CUTLASS CuTe is assumed. For foundational concepts, see the CuTe series by Reed.
Key Factors for Selecting an ldmatrix Operation
To choose the best ldmatrix instruction in CUTLASS CuTe, consider:
- The expansion strategy of your
TiledMMA. - The logical layout (Row-Major or Column-Major) of your input matrix in Shared Memory.
1. Understanding the TiledMMA Expansion Strategy
A TiledMMA in CUTLASS CuTe is built by expanding a base MMA_Atom through repetition along the M, N, or K dimensions. In CUTLASS 3.5, this is managed by the PermutationMNK parameter. For example, using SM80_16x8x8_F16F16F16F16_TN as the MMA_Operation and expanding by a factor of 2 along N (ValLayoutMNK = (1, 2, 1)), each warp computes a 16x16x8 matrix multiplication.
To execute this, a warp must:
- Load the 16x8 matrix A and the 8x16 matrix B from Shared Memory into Registers.
- Perform two
mmainstructions, each multiplying A with an 8x8 partition of B, producing two 16x8 partitions of C.
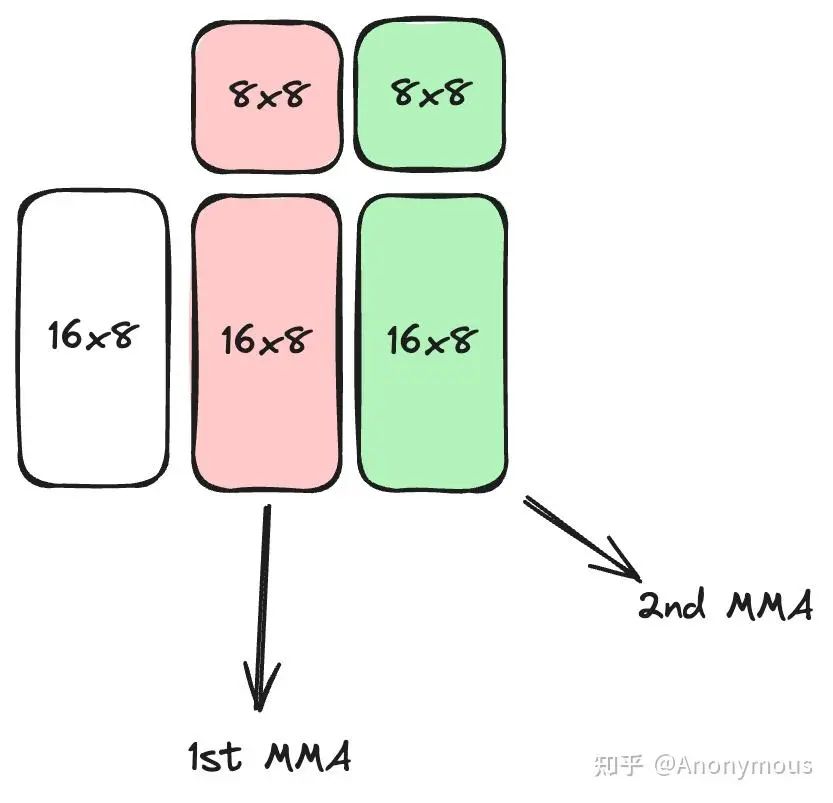
Efficient Data Loading with ldmatrix
The ldmatrix instruction loads one or more 8x8 sub-matrices into registers. The x1, x2, and x4 variants load 1, 2, or 4 sub-matrices, respectively. For example, both A (16x8) and B (8x16) contain two 8x8 sub-matrices, so ldmatrix.x2 loads them efficiently. CuTe's make_tiled_copy_A/B functions calculate the required addresses based on the TiledMMA layout and selected Copy_Atom.
Using the largest possible ldmatrix variant (e.g., x4 for four sub-matrices) minimizes instruction overhead and maximizes performance. Using a variant that doesn't match the tile size (e.g., x4 for only two sub-matrices) results in compile-time errors such as: TiledCopy uses too few vals for selected CopyAtom.
For more details, refer to the PTX ISA documentation.
2. Input Matrix Layout in Shared Memory
The ldmatrix instruction requires each row of an 8x8 sub-matrix to be contiguous in memory. This is naturally satisfied for Row-Major layouts. For Column-Major layouts, use the trans (transpose) qualifier, which transposes the sub-matrix during the load.
Rule of Thumb:
- If the input matrix in Shared Memory is Row-Major, use a
Copy_Operationending in_N(Normal, no transpose). - If the input matrix is Column-Major, use a
Copy_Operationending in_T(Transpose).
CuTe's make_tiled_copy_A/B functions abstract these details, ensuring correct address calculation and operation selection.
Swizzling Considerations in Shared Memory
In practical GEMM pipelines, Shared Memory data is often swizzled to reduce bank conflicts and optimize bandwidth. CuTe's Swizzle layout abstracts the physical arrangement, so you only need to consider the logical layout (Row-Major or Column-Major) when configuring Shared Memory-to-Register copies. For more, see Reed's article on Swizzling in CuTe.
Practical Examples of ldmatrix Selection
Example 1: Large Tile
- Config:
MMA_Operation=SM80_16x8x16_F16F16F16F16_TN,ValLayoutMNK= (1, 2, 1) - Analysis: Each warp processes 16x16 matrices (four 8x8 sub-matrices). Use
ldmatrix.x4for optimal performance. - Selection:
- Row-Major:
SM75_U32x4_LDSM_N - Column-Major:
SM75_U16x8_LDSM_T
- Row-Major:
Example 2: Small Tile
- Config:
MMA_Operation=SM80_16x8x8_F16F16F16F16_TN,ValLayoutMNK= (1, 1, 1) - Analysis: B is 8x8 (one sub-matrix). Use
ldmatrix.x1. - Selection:
- Row-Major:
SM75_U32x1_LDSM_N - Column-Major:
SM75_U16x2_LDSM_T
- Row-Major:
Summary: Best Practices for ldmatrix in CUTLASS CuTe
To select the optimal ldmatrix instruction in CUTLASS CuTe:
- Match the
ldmatrixvariant (x1,x2,x4) to the number of 8x8 sub-matrices in your tile (as determined byTiledMMA). - Choose the
_Nor_Tsuffix based on whether your Shared Memory input is Row-Major or Column-Major.
Aligning these choices ensures maximum performance and clarity in your GEMM pipeline.
Further Reading:
- [Tiler parameter selection in TiledCopy]
- [Swizzle abstraction details]
- [Collective communication in CuTe]
For more, review the code samples and experiment with different configurations.
References: