In a previous article, we explored the ldmatrix instruction for efficient matrix transfers from Shared Memory to Registers on NVIDIA GPUs. Here, we focus on optimizing data movement from Global Memory to Shared Memory—a critical step for high-performance CUDA kernels, especially in tensor operations and deep learning workloads.
Why Memory Coalescing Matters in CUDA
Pipelining is essential in GPU programming to hide memory latency and maximize throughput. NVIDIA's CuTe C++ template library abstracts the SM80 cp.async instruction into a high-level interface called TiledCopy. This enables asynchronous, coalesced data transfers from Global Memory to Shared Memory, allowing Tensor Cores to compute while data loads in parallel.
What is TiledCopy?
TiledCopy is a CuTe abstraction for efficiently copying tiles of data between memory spaces. It is highly configurable via thread and value layouts, making it adaptable for various tensor shapes and memory layouts.
auto tiled_copy = make_tiled_copy(
Copy_Atom<UniversalCopy, half_t>{},
Layout<Shape<_16, _8>, Stride<_8, _1>>{}, // ThrLayout
Layout<Shape<_1, _4>>{}); // ValLayout
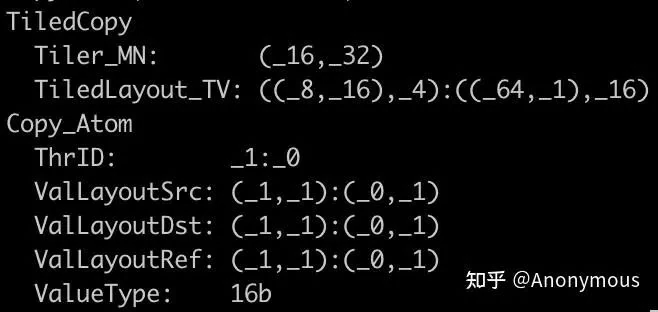
Understanding Tiler_MN and TiledLayout_TV
What is Tiler_MN?
Tiler_MNdefines the shape of the tile that a singleTiledCopyoperation moves.- It is determined by the thread layout (
ThrLayout) and value layout (ValLayout). TiledCopyis agnostic to the stride of the source tensor, making it flexible for row-major, column-major, or custom layouts.
For example, in a 4096x4096 row-major matrix, a (16, 64) tile has a stride of (4096, 1). In column-major, the stride is (1, 4096). TiledCopy works efficiently regardless, as long as the tile shape matches.
How is Tiler_MN Computed?
Copy_Atom<UniversalCopy, half_t>: Each thread copies onehalf_telement.ValLayout<Shape<_1, _4>>: Each thread copies a (1, 4) tile.ThrLayout<Shape<_16, _8>, Stride<_8, _1>>: Threads are arranged in a 16x8 grid.- Total tile shape: (16 threads, 32 elements) = (16, 32) for
Tiler_MN.
What is TiledLayout_TV?
TiledLayout_TV maps a thread's ID and its local element coordinate to a global coordinate in the tile. For example, thread 9 in a (16, 8) grid accesses its (0, 2) element, which maps to a unique position in the (16, 32) tile.

Memory Coalescing Patterns
Row-Major Layout: Optimal Coalescing
When copying a (16, 32) tile from a row-major matrix (stride (4096, 1)), threads access contiguous memory. Each group of 8 threads copies 32 consecutive elements, maximizing memory bandwidth.
| Thread ID | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Offset | 0-3 | 4-7 | 8-11 | 12-15 | 16-19 | 20-23 | 24-27 | 28-31 |
Column-Major Layout: Suboptimal Coalescing
For column-major matrices (stride (1, 4096)), threads access non-contiguous memory, resulting in inefficient, strided accesses and reduced bandwidth.
| Thread ID | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Offset | 0, 4096,... | 4, 4100,... | 8, 4104,... | ... | ... | ... | ... | ... |
Solution: Transposed TiledCopy for Column-Major
auto tiled_copy = make_tiled_copy(
Copy_Atom<UniversalCopy, half_t>{},
Layout<Shape<_8, _16>, Stride<_16, _1>>{}, // ThrLayout
Layout<Shape<_4, _1>>{}); // ValLayout
This layout ensures threads access contiguous memory even in column-major matrices, restoring coalesced access.
Leveraging cp.async for Asynchronous Copies
The cp.async instruction (SM80+) enables hardware-accelerated, asynchronous memory copies. To use it efficiently:
auto tiled_copy = make_tiled_copy(
Copy_Atom<SM80_CP_ASYNC_CACHEGLOBAL<cute::uint128_t>, half_t>{},
Layout<Shape<_16, _8>, Stride<_8, _1>>{}, // ThrLayout
Layout<Shape<_1, _8>>{}); // ValLayout
Copy_Atom<SM80_CP_ASYNC_CACHEGLOBAL<cute::uint128_t>, half_t>: Each thread copies 8half_telements (16 bytes) at once.ValLayout<Shape<_1, _8>>: Each thread's tile is contiguous, matching the 128-bit vector requirement.
Note: For column-major, use the transposed version to ensure contiguous access:
auto tiled_copy = make_tiled_copy(
Copy_Atom<SM80_CP_ASYNC_CACHEGLOBAL<cute::uint128_t>, half_t>{},
Layout<Shape<_8, _16>, Stride<_16, _1>>{}, // ThrLayout
Layout<Shape<_8, _1>>{}); // ValLayout
Cache Line Alignment for Maximum Bandwidth
A well-chosen TiledCopy aligns thread groups to cache lines. For example, 8 threads each copying 16 bytes access 128 bytes (one cache line). A full warp (32 threads) loads 4 cache lines efficiently.
auto tiled_copy = make_tiled_copy(
Copy_Atom<SM80_CP_ASYNC_CACHEGLOBAL<cute::uint128_t>, half_t>{},
Layout<Shape<_32, _4>, Stride<_4, _1>>{}, // ThrLayout
Layout<Shape<_1, _8>>{}); // ValLayout
Here, only 64 bytes are accessed per group, wasting half the cache line bandwidth. Always align thread and value layouts to cache line sizes (128 bytes) for optimal performance.
Conclusion
TiledCopy and cp.async enable high-throughput data transfers from global to shared memory in CUDA. By carefully choosing thread and value layouts, you can ensure memory coalescing, maximize cache line utilization, and fully exploit NVIDIA GPU hardware. For further optimization, explore how shared memory layouts (e.g., Swizzle) can avoid bank conflicts and further boost performance.