It's been seven years since the original GPT architecture was unveiled. Looking back from our 2024-2025 vantage point, with models like DeepSeek-V3 and Llama 4 on the scene, it's striking how much the core structure has stayed the same since GPT-2 in 2019.
Sure, the details have evolved. Positional embeddings have matured from absolute to Rotary Positional Embeddings (RoPE). Multi-Head Attention has largely given way to the more efficient Grouped-Query Attention. And activation functions like SwiGLU have replaced GELU. But are these just incremental refinements, or are we witnessing genuine architectural breakthroughs? Are we building something new, or just polishing the same old engine?
Comparing Large Language Models (LLMs) to pinpoint the secret sauce behind their performance is notoriously difficult. Datasets, training techniques, and hyperparameters vary wildly and are often shrouded in mystery.
However, I believe there's immense value in dissecting the architectural shifts in the models themselves. It gives us a clear window into what LLM developers are prioritizing in 2025. (Figure 1 shows a selection of the models we'll cover.)
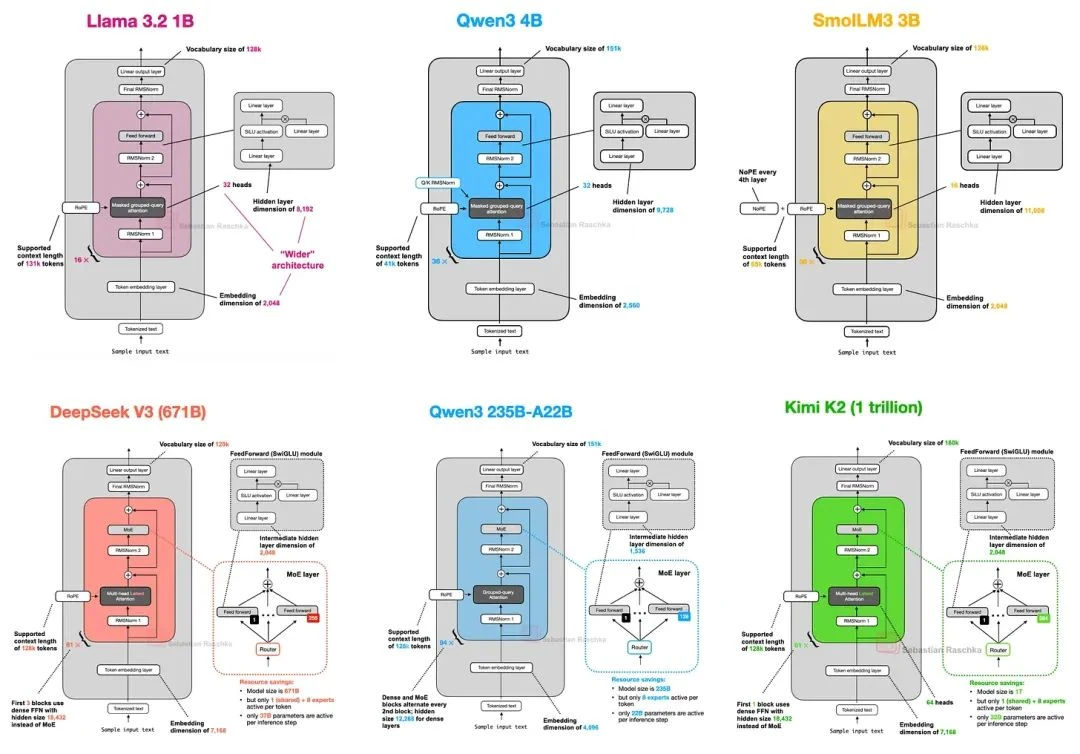
Therefore, this article will zero in on the architectural evolution of today's flagship open-source models, setting aside benchmark scores and training algorithms to focus purely on the blueprints.
DeepSeek V3/R1
You've likely heard about the splash DeepSeek R1[1] made when it dropped in January 2025. DeepSeek R1 is the inference-optimized model built upon the DeepSeek V3[2] architecture, which was first introduced in December 2024.
While this article focuses on 2025 architectures, it's fair to include DeepSeek V3. It only truly captured the community's attention after the release of its powerful successor, DeepSeek R1.
In this section, I'll spotlight two key architectural innovations in DeepSeek V3 that boost its computational efficiency and set it apart from the crowd.
Multi-Head Latent Attention (MLA)
Before we dive into Multi-Head Latent Attention (MLA), let's quickly recap some background to understand its purpose. Our starting point is Grouped-Query Attention (GQA), which has become the go-to, more efficient alternative to the original Multi-Head Attention (MHA).
In a nutshell, GQA streamlines MHA. Instead of each attention head having its own dedicated key (K) and value (V) projections, GQA groups multiple query (Q) heads to share a single set of K and V projections. This drastically cuts down on memory usage.
For example, as shown in Figure 2, with 4 attention heads and 2 key-value groups, heads 1 and 2 might share one K/V set, while heads 3 and 4 share another. This reduces the number of key and value computations, saving memory and speeding up inference without a significant hit to performance.
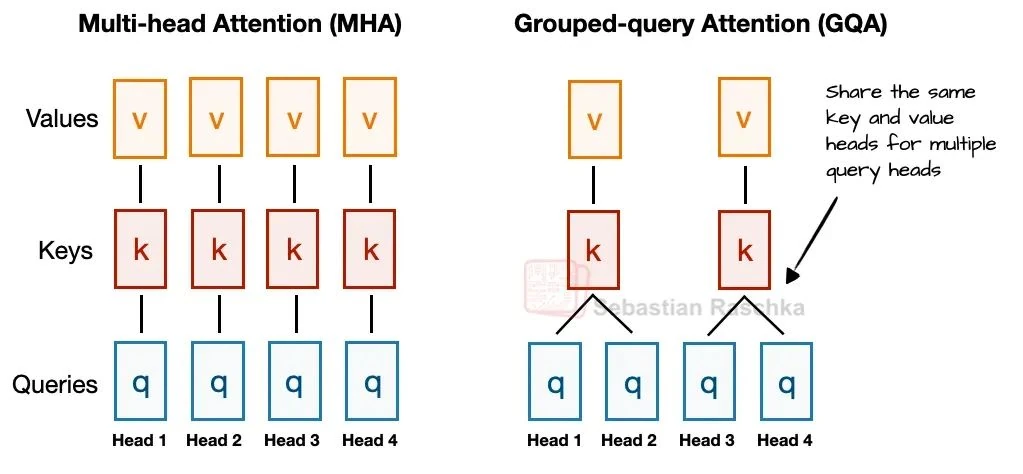
So, the core idea of GQA is to shrink the number of key and value heads. This achieves two things:
- It reduces the model's total parameter count.
- It slashes the memory bandwidth needed for the key and value tensors during inference, as fewer K/V pairs need to be stored in and retrieved from the KV cache.
While GQA is primarily an efficiency play, ablation studies (like those in the original GQA paper[3] and the Llama 2 paper[4]) have shown its modeling performance is on par with standard MHA.
Now, enter Multi-Head Latent Attention (MLA). It offers a different strategy for saving memory, one that's also perfectly suited for the KV cache. Instead of reducing the number of K/V heads like GQA, MLA compresses the key and value tensors into a lower-dimensional "latent" space before caching them.
During inference, these compressed tensors are projected back to their original size, as illustrated in Figure 3. This adds an extra matrix multiplication step but yields significant memory savings.
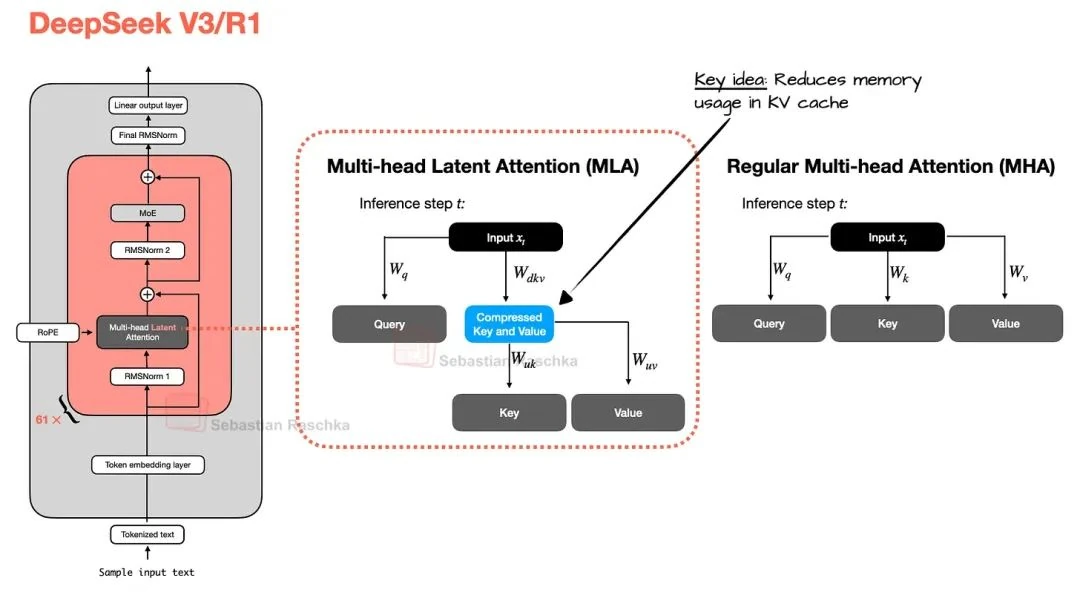
(Interestingly, the queries are also compressed during training, but not during inference.)
MLA wasn't invented for DeepSeek V3; its predecessor, DeepSeek-V2[5], introduced the technique. The V2 paper includes some fascinating ablation studies that shed light on why the DeepSeek team chose MLA over the more common GQA (see Figure 4).
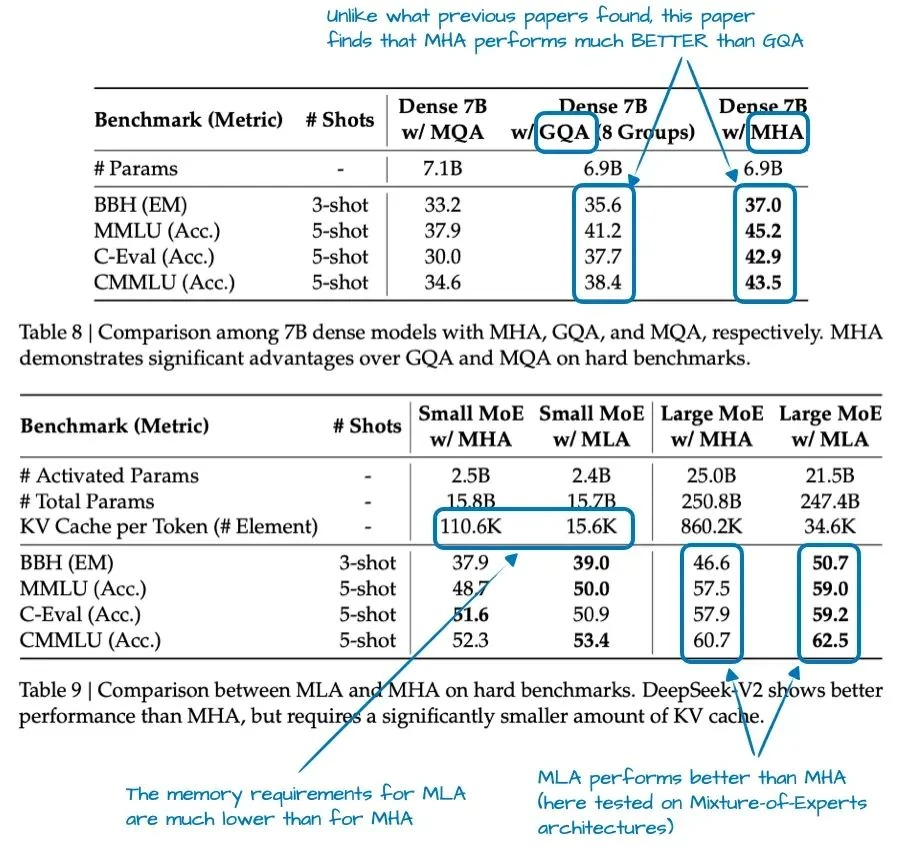
As the results in Figure 4 show, GQA actually underperformed MHA in their tests, while MLA managed to outperform it. This likely sealed the deal for the DeepSeek team. (An apples-to-apples comparison of the "KV cache per token" savings between MLA and GQA would be fascinating!)
To wrap up this section: MLA is a clever technique that reduces KV cache memory demands while also managing to slightly edge out standard MHA in modeling performance.
Mixture of Experts (MoE)
The other cornerstone of DeepSeek's architecture is its use of Mixture of Experts (MoE) layers. While MoE is not a new concept, it has enjoyed a major resurgence this year, and you'll see it appear in several other models we discuss.
Even if you're familiar with MoE, a quick refresher can't hurt.
The core idea behind MoE is simple yet powerful: replace each Feed-Forward Network (FFN) in a Transformer block with multiple "expert" layers. Each of these experts is itself an FFN. So, we're swapping one FFN block for a whole committee of them, as shown in Figure 5.
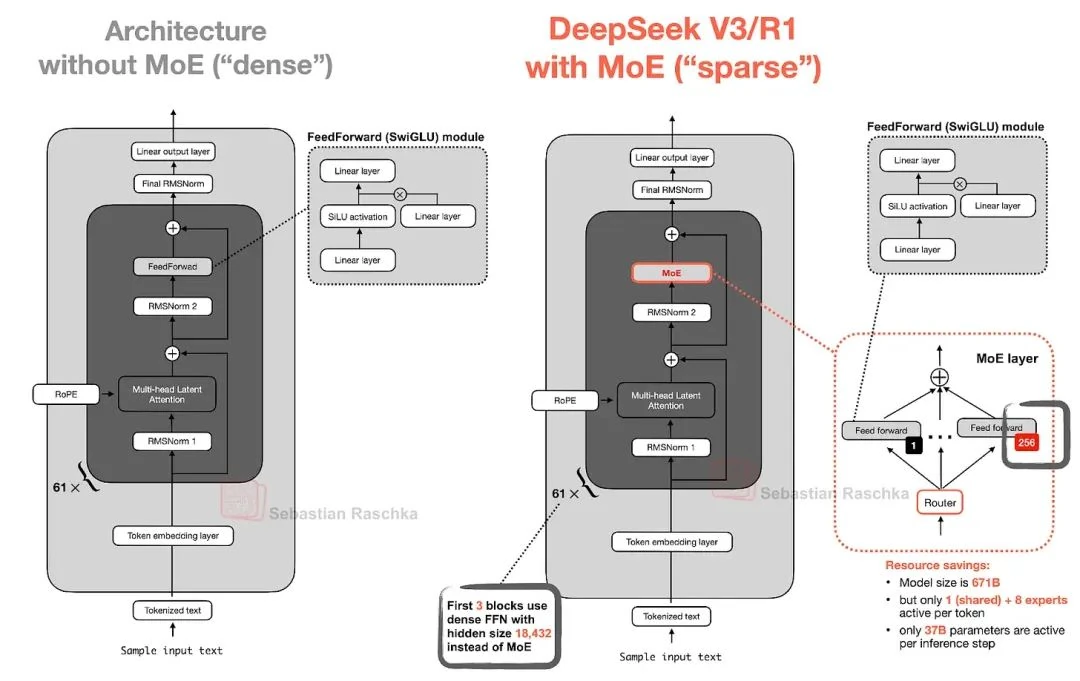
The FFN (the dark gray block in the figure) is where the vast majority of a model's parameters reside. (Remember, Transformer blocks, and thus FFNs, are stacked dozens of times—61 times in DeepSeek-V3's case.)
So, swapping one FFN for many in an MoE setup massively inflates the model's total parameter count. But here's the trick: for any given token, we don't use all the experts. A "router" mechanism selects just a small subset of experts to process that token. (We'll skip the nitty-gritty of the router for now to keep things moving.)
Because only a few experts are engaged at a time, MoE modules are called sparse modules, in contrast to dense modules that use their full parameter set for every computation. This sparsity is key. The enormous total parameter count gives the LLM a huge capacity to absorb knowledge during training, but the sparse activation keeps inference computationally efficient.
For instance, DeepSeek-V3 has 256 experts per MoE module, leading to a staggering 671 billion total parameters. But during inference, only 9 experts are activated for any token (1 shared expert plus 8 chosen by the router). This means only 37 billion parameters are actually in use at any given moment—a tiny fraction of the total.
A standout feature in DeepSeek-V3's MoE implementation is the shared expert—an expert that is activated for every single token. This idea isn't new; it was explored in the 2024 DeepSeek MoE paper[6] and the 2022 DeepSpeedMoE paper[7].
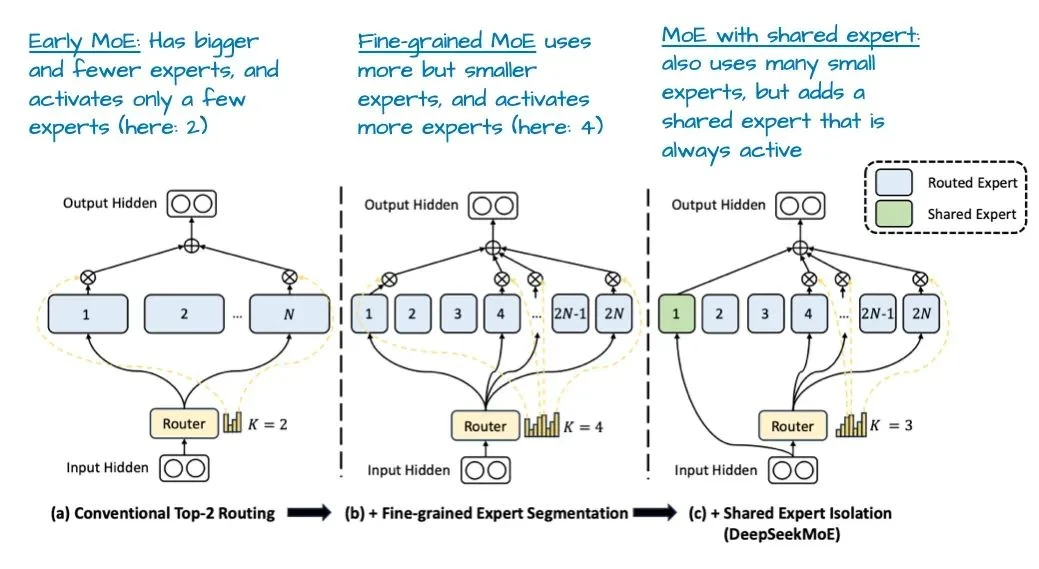
The DeepSpeedMoE paper first noted that a shared expert improves overall performance. The intuition is that this expert can learn common, repetitive patterns, freeing up the other specialized experts to focus on more niche knowledge.
In summary, DeepSeek-V3 is a behemoth of a model with 671 billion parameters, dwarfing other open-weight models like the 405B Llama 3 at the time of its release. Yet, thanks to its MoE architecture, it's surprisingly efficient at inference, activating just 37B parameters per token. Its other key differentiator is the use of Multi-Head Latent Attention (MLA) over Grouped-Query Attention (GQA), a choice backed by internal studies showing MLA's superior modeling performance.
OLMo 2
The OLMo series from the nonprofit Allen Institute for AI stands out for its radical transparency. The team shares extensive details about their training data, code, and methodology in detailed technical reports.
While you might not see OLMo topping the leaderboards, these models are exceptionally well-documented, making them an invaluable blueprint for anyone looking to build their own LLMs.
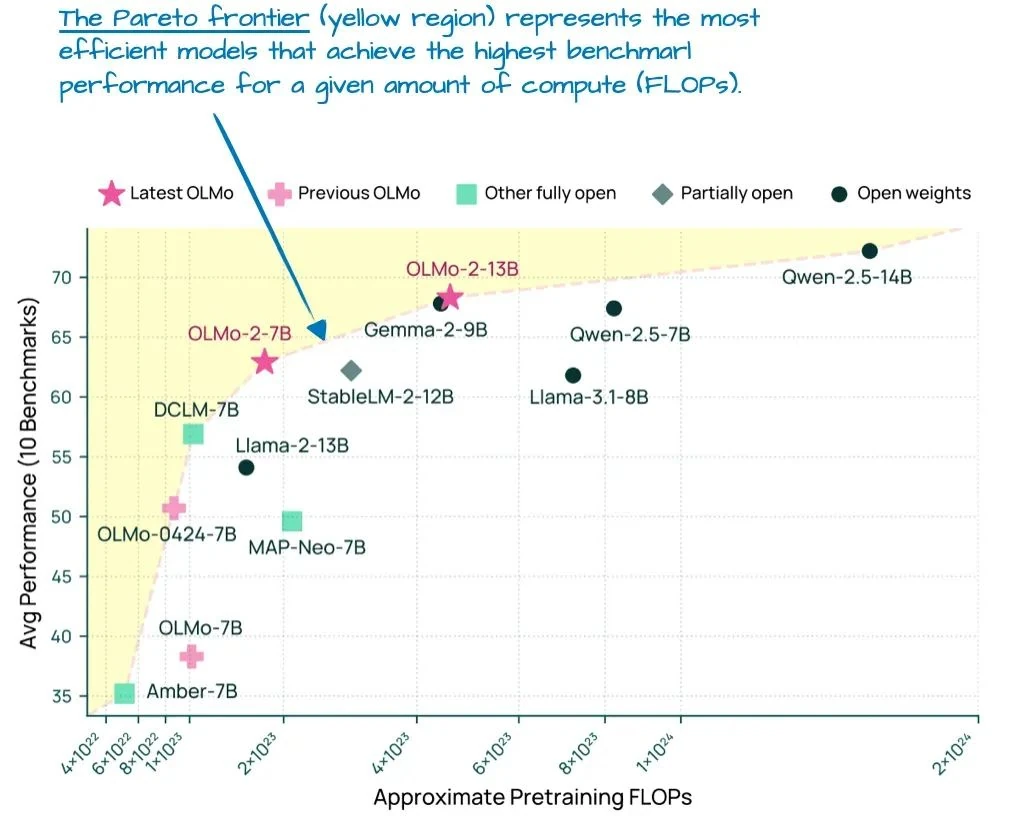
And don't mistake transparency for weakness. Upon its release in January (before the arrival of Llama 4, Gemma 3, and Qwen 3), the OLMo 2[8] model was on the Pareto frontier, offering a best-in-class trade-off between computation and performance, as shown in Figure 7.
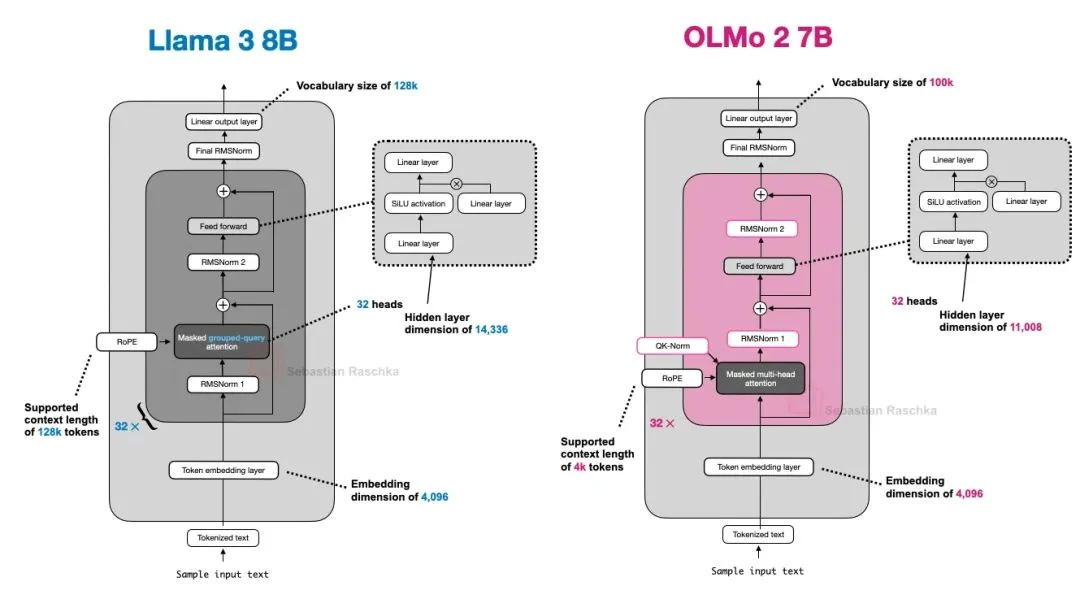
As promised, we're focusing purely on architectural details. So, what makes OLMo 2 interesting? It all comes down to normalization: the placement of its RMSNorm layers and the addition of a QK-norm.
It's also worth noting that OLMo 2 sticks with traditional Multi-Head Attention (MHA), forgoing the now-common MLA or GQA.
Overall, OLMo 2 follows the classic GPT-style architecture, but with a few notable twists. Let's start with the normalization layers.
RMSNorm Layer Position
Like Llama, Gemma, and most modern LLMs, OLMo 2 uses RMSNorm instead of the original LayerNorm. Since RMSNorm (a simplified LayerNorm with fewer parameters) is now standard practice, we'll skip the LayerNorm vs. RMSNorm debate.
What's really worth discussing is the placement of these RMSNorm layers. The original "Attention is All You Need" Transformer used Post-Norm, placing normalization layers after the attention and FFN modules.
GPT and most of its successors switched to Pre-Norm, moving the normalization layers before the attention and FFN modules. The figure below illustrates the difference.

Back in 2020, Xiong et al.[9] demonstrated that Pre-Norm leads to more stable gradients during training and works well even without the careful learning rate warm-up that Post-Norm requires.
So why does this matter? Because OLMo 2 brings back a form of Post-Norm. Instead of placing normalization before the attention and FFN layers, it places them after, as shown in the figure above. Note that the normalization layers are still inside the residual connection, unlike the original Transformer architecture.
The rationale? Improved training stability, as shown in the figure below.
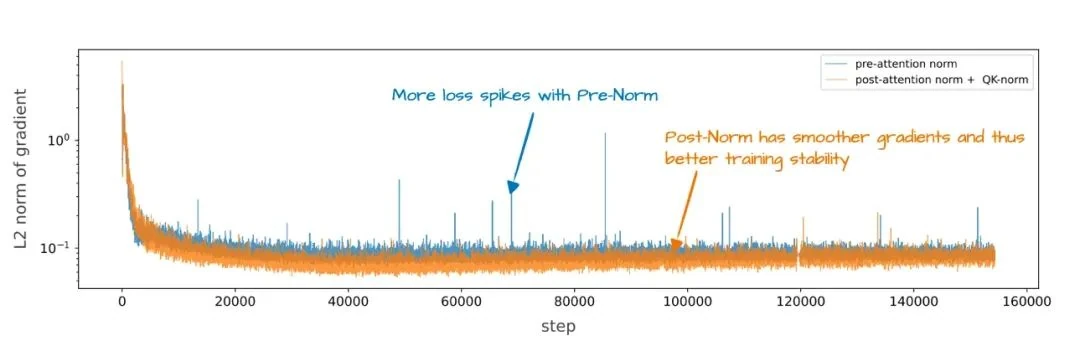
Unfortunately, this chart shows the combined effect of reordering the norm layers and adding QK-Norm, a separate technique. This makes it hard to isolate the contribution of the Post-Norm placement alone.
QK-Norm
Since we've already mentioned it, let's unpack QK-Norm. You'll see this technique again in models like Gemma 2 and Gemma 3.
QK-Norm is simply another RMSNorm layer, but it's applied inside the MHA module to the query (q) and key (k) vectors before RoPE is applied. To visualize this, here’s a snippet from the GQA layer I wrote for my from-scratch Qwen3 implementation[10] (the application is analogous in OLMo's MHA):
As mentioned, QK-Norm, in tandem with Post-Norm, helps stabilize training. This technique wasn't invented by the OLMo 2 team; it dates back to the 2023 Scaling Vision Transformers paper[11].
In short, OLMo 2's noteworthy architectural decisions are all about normalization. By moving RMSNorm layers to a Post-Norm position and adding QK-Norm inside the attention block, the team achieved more stable training.
The figure below provides a final comparison with Llama 3. Besides OLMo 2's use of MHA instead of GQA, the architectures are quite similar. (Though it's worth noting the OLMo 2 team did release a 32B variant with GQA three months later[12].)
Gemma 3
Google's Gemma models have consistently been excellent, though perhaps a bit underrated compared to heavy-hitters like the Llama series.
Gemma is known for its large vocabulary (to better support multiple languages) and its focus on the 27B parameter size—a sweet spot that's more powerful than 8B models but less resource-hungry than 70B models. For what it's worth, it runs beautifully on my Mac Mini.
So, what's architecturally interesting about Gemma 3[13]? While models like DeepSeek-V3 use MoE to manage inference costs, Gemma 3 employs a different trick up its sleeve: sliding window attention.
Sliding Window Attention
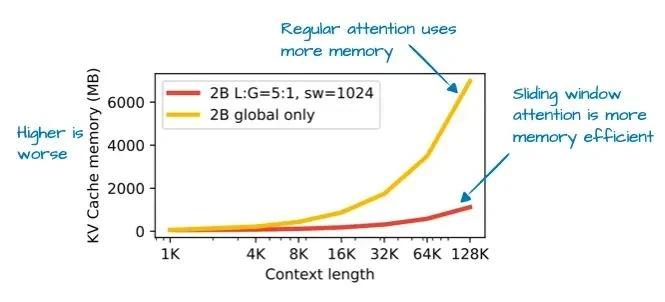
By using sliding window attention (a technique from the 2020 LongFormer paper[14] also used in Gemma 2[15]), the Gemma 3 team dramatically reduced the memory footprint of the KV cache, as shown below.
So, what is sliding window attention? Think of standard self-attention as global attention, where every token can "see" every other token in the sequence. Sliding window attention is a form of local attention, where we restrict a token's view to a fixed-size window of its neighbors. This is illustrated below.
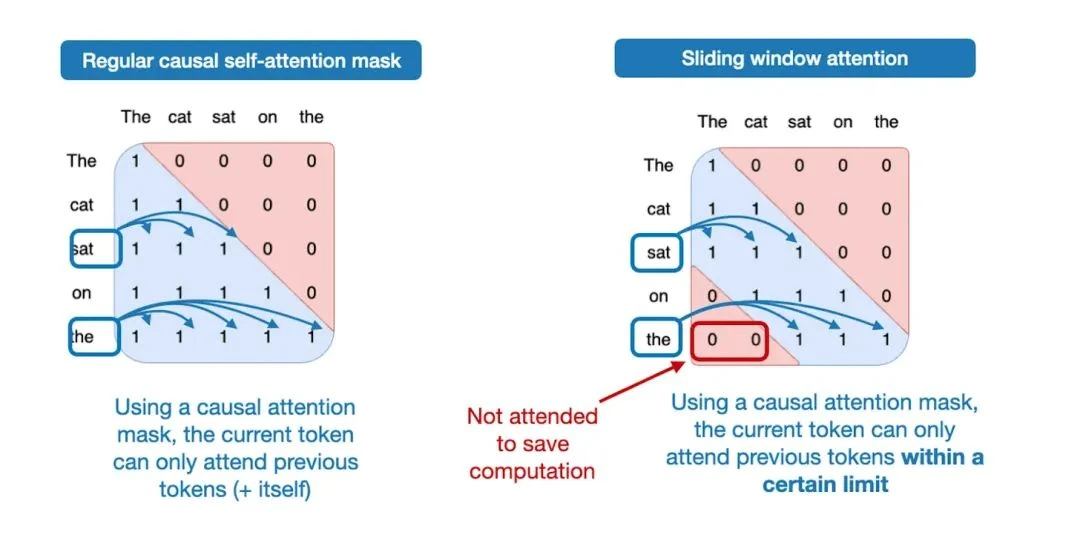
This technique can be used with both MHA and GQA; Gemma 3 uses it with GQA.
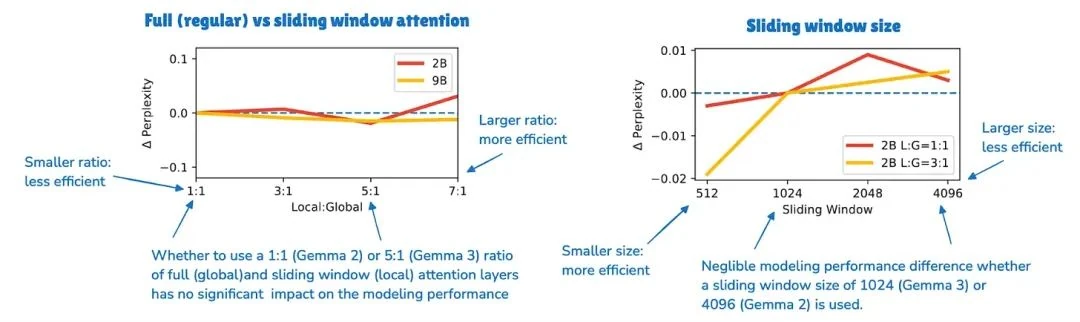
Now, Gemma 2 also used sliding window attention. What's new in Gemma 3 is the ratio of local to global attention layers. Gemma 2 used a 1:1 mix. Gemma 3 shifts to a 5:1 ratio, meaning there is only one full (global) attention layer for every five sliding window (local) attention layers. They also shrank the window size from 4096 tokens in Gemma 2 to just 1024 in Gemma 3. This aggressively prioritizes efficient, local computation.
According to their ablation studies, this heavy reliance on local attention has a minimal impact on modeling performance.
While sliding window attention is Gemma 3's headline feature, it's worth briefly touching on its normalization layers, following our discussion on OLMo 2.
Normalization Layers
In a small but interesting design choice, Gemma 3 uses RMSNorm in both Pre-Norm and Post-Norm configurations, sandwiching its GQA module.
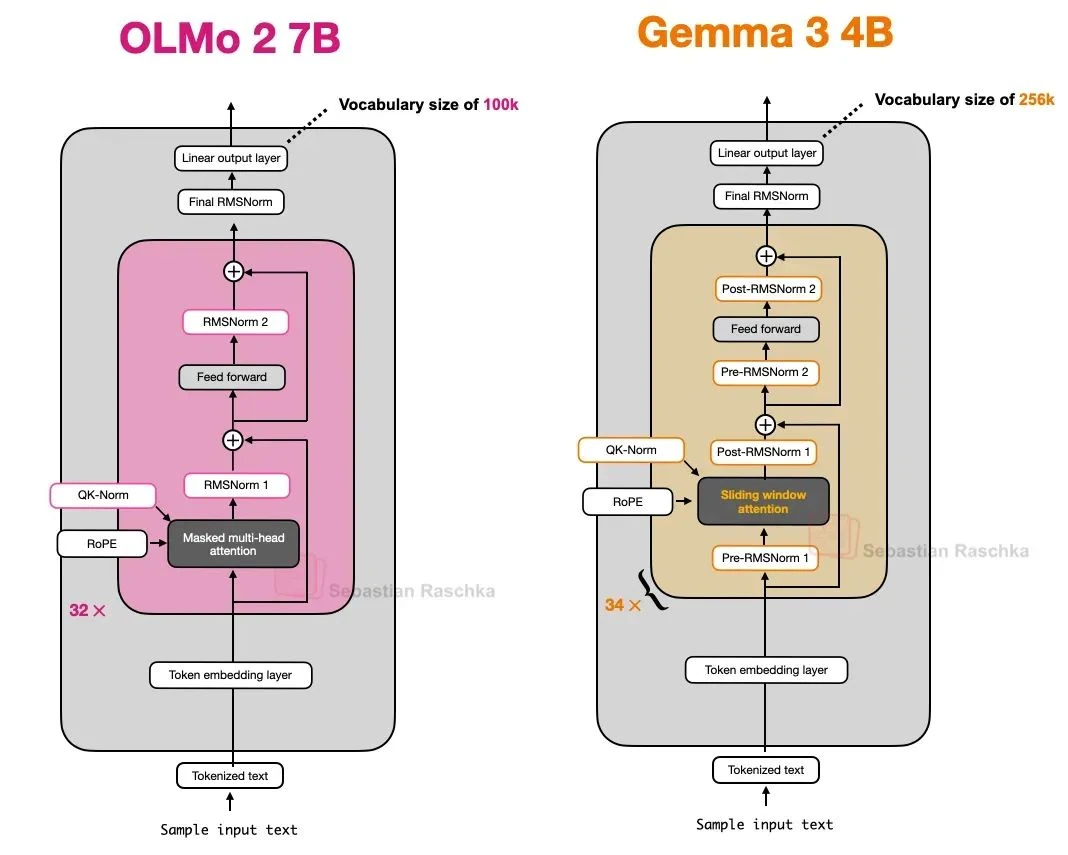
This "belt and suspenders" approach seems intuitive, aiming to capture the benefits of both placements. At worst, if one layer is redundant, it introduces a minor inefficiency. But since RMSNorm is computationally cheap in the grand scheme of things, the practical impact is negligible.
To sum up, Gemma 3 is a high-performing and somewhat underrated open-weight LLM. Its most compelling feature is the strategic use of sliding window attention for efficiency—it would be fascinating to see this combined with MoE in the future. It also features a unique dual-normalization setup around its attention blocks.
Gemma 3n
A few months after Gemma 3, Google released Gemma 3n[16], an efficiency-optimized version designed to run on mobile devices.
One of Gemma 3n's key efficiency hacks is per-layer embedding (PLE). The idea is to keep only a subset of the model's parameters in GPU memory. Other parameters, like token embeddings for different modalities (text, audio, vision), are streamed from the CPU or SSD on demand.
The figure below illustrates the memory savings from PLE, citing 5.44 billion parameters for a standard Gemma 3 model. This likely refers to a 4B variant of Gemma 3.
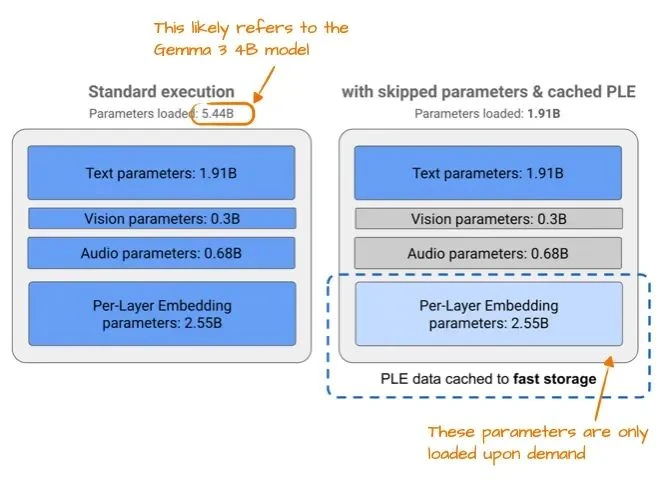
The discrepancy between 5.44B and 4B highlights an interesting quirk in how parameter counts are often reported. Companies sometimes exclude embedding parameters to make a model seem smaller, but will include them when it helps illustrate a larger saving, as seen here. This practice has become common across the field.
Another clever trick is the MatFormer[17] concept (short for Matryoshka Transformer). Gemma 3n is built as a shared architecture that can be "sliced" into smaller, independently functional models. Each slice is trained to operate on its own, so at inference time, you can run just the smaller slice you need instead of the full model.
Mistral Small 3.1
Released in March, shortly after Gemma 3, Mistral Small 3.1 24B[18] is noteworthy for outperforming the larger Gemma 3 27B on several benchmarks (math being the exception) while being faster.
Mistral Small 3.1's zippier inference speeds likely stem from its custom tokenizer, a smaller KV cache, and fewer layers. Otherwise, it sports a fairly standard architecture, as shown below.
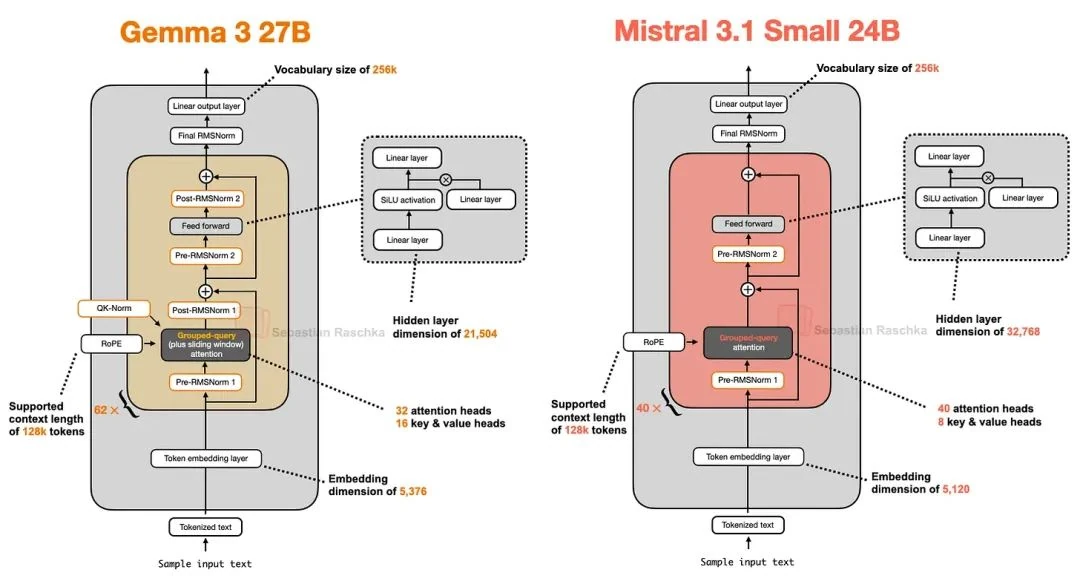
Interestingly, earlier Mistral models used sliding window attention, but the team appears to have abandoned it in this release. Since Mistral uses standard GQA instead of Gemma 3's sliding window variant, I speculate that this allows them to leverage highly optimized code like FlashAttention. While sliding window attention saves memory, it doesn't necessarily reduce inference latency, which seems to be the primary focus for Mistral Small 3.1.
Llama 4
Our earlier deep dive into Mixture of Experts (MoE) pays off here, as Llama 4[19] also adopts the MoE paradigm. Its architecture is relatively standard and bears a strong resemblance to DeepSeek-V3. (Llama 4 also includes native multimodal support, but for this article, we're focusing on the text-only model.)
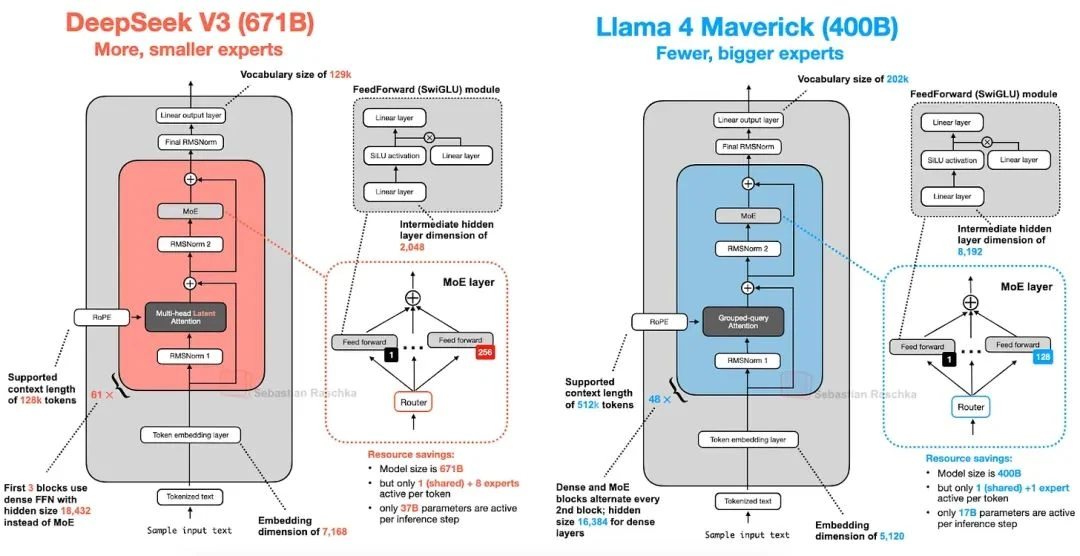
While the Llama 4 Maverick architecture looks familiar, there are some interesting differences when compared to DeepSeek-V3.
First, Llama 4 uses GQA, like its predecessors, whereas DeepSeek-V3 uses the more exotic MLA. Both are massive models, but DeepSeek-V3 has about 68% more total parameters. However, DeepSeek-V3 also has more than double the number of active parameters (37B vs. Llama 4 Maverick's 17B).
Their MoE implementations also differ. Llama 4 uses a more classic setup with fewer, larger experts (activating 2 experts with a hidden size of 8192). In contrast, DeepSeek-V3 uses more, smaller experts (activating 9 experts with a hidden size of 2048). Furthermore, Llama 4 alternates between MoE and dense FFN layers, while DeepSeek uses MoE layers in nearly every Transformer block.
Given the many small architectural differences, it's hard to isolate their individual impact on performance. The main takeaway, however, is clear: MoE has become a dominant architectural trend in 2025.
Qwen3
The Qwen team has a track record of delivering top-tier open-weight LLMs. I remember co-advising the LLM Efficiency Challenge at NeurIPS 2023, where every single winning solution was built on Qwen2.
Now, the Qwen3 series continues this tradition, with models ranking at the top of their respective size classes. The series includes seven dense models (from 0.6B to 32B) and two MoE models (30B-A3B and 235B-A22B).
Let's start with the dense architecture. At the time of writing, the 0.6B model is likely the smallest current-generation open-weight model available. In my experience, it performs remarkably well for its size, offering excellent throughput and a tiny memory footprint for local use. Its small size also makes it easy to fine-tune on a local machine for educational purposes.
As a result, Qwen3 0.6B has largely replaced Llama 3 1B for many use cases. The figure below compares the two architectures.
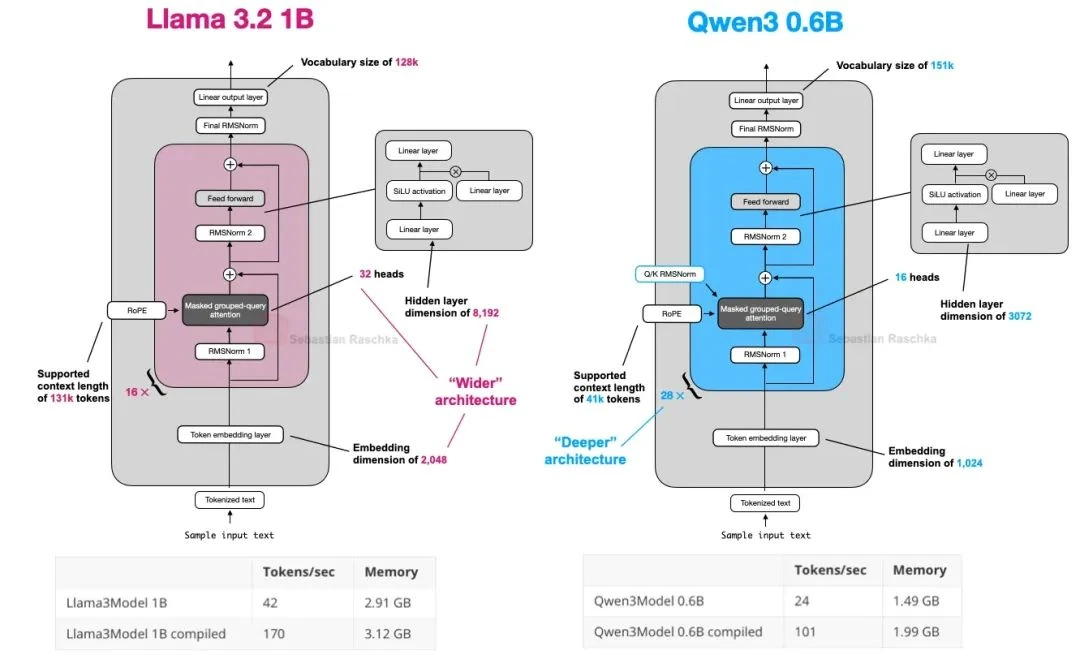
If you're interested in a clean Qwen3 implementation without third-party library dependencies, I recently built one from scratch in pure PyTorch[20].
The performance data in the figure above is based on my from-scratch implementation running on an A100 GPU. As you can see, Qwen3 has a smaller memory footprint due to its smaller overall size, hidden layers, and fewer attention heads. However, it uses more Transformer blocks than Llama 3, resulting in a slightly slower generation speed (tokens per second).
As mentioned, Qwen3 also comes in two MoE flavors. Why do teams like Qwen release both dense and sparse variants?
MoE variants, as we've discussed, help slash the inference cost of very large models. Offering both gives users flexibility. Dense models are generally easier to fine-tune, deploy, and optimize across various hardware. MoE models, on the other hand, are built for scaled-up inference, offering a much higher model capacity (more knowledge learned during training) for a given inference budget.
By releasing both, the Qwen3 series caters to a wider range of applications: dense models for robustness and ease of use, and MoE models for large-scale, efficient serving.
To conclude this section, let's compare the Qwen3 235B-A22B (where A22B means "22 billion active parameters") with DeepSeek-V3, which has nearly twice the active parameters (37B).
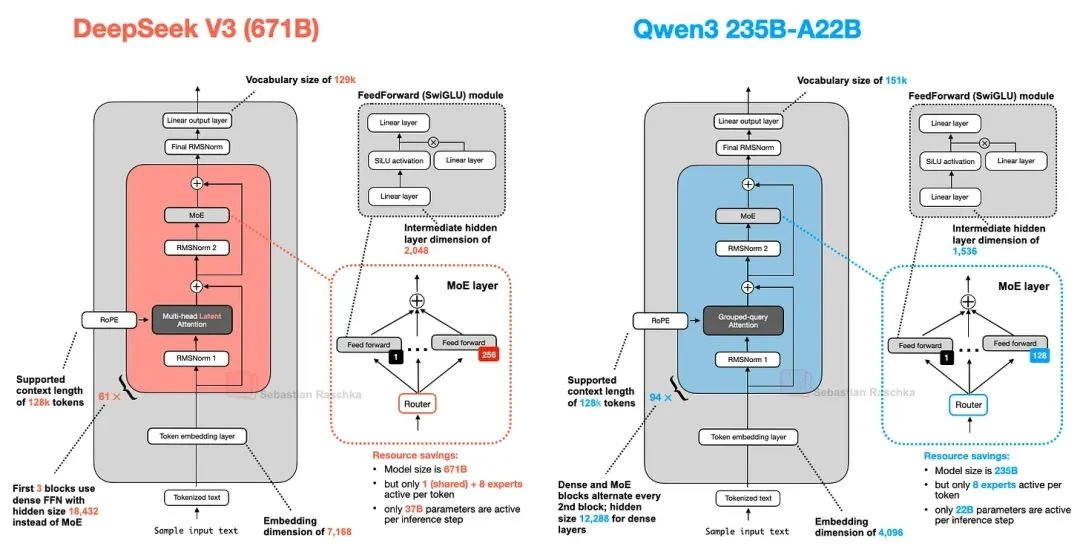
As the figure shows, the architectures are very similar. One notable difference is that the Qwen3 model no longer uses a shared expert, a feature present in earlier Qwen MoE models like Qwen2.5-MoE[21].
The Qwen3 team didn't disclose their reasoning, but if I were to guess, it's possible that as they increased the number of experts from 2 (in Qwen2.5-MoE) to 8 (in Qwen3), the shared expert was no longer needed for training stability. Dropping it would then be a straightforward way to save on computation and memory. (This, however, doesn't explain why DeepSeek-V3 retains its shared expert.)
SmolLM3
While SmolLM3[22] might not have the same name recognition as the other giants in this article, it's an interesting model that delivers impressive performance in a convenient 3B parameter size, neatly fitting between Qwen3's 1.7B and 4B offerings.
Furthermore, much like OLMo, the team shares a wealth of training details—a rare and always welcome practice.
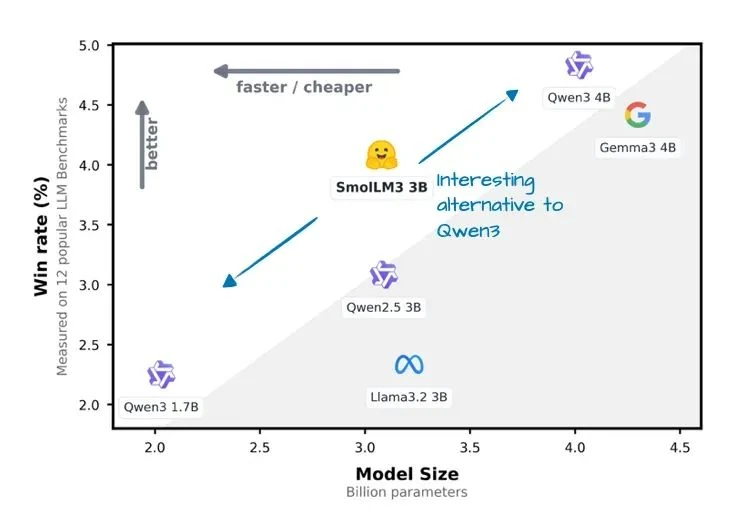
As the chart below shows, the SmolLM3 architecture looks quite standard. Perhaps its most intriguing aspect is its use of NoPE (No Positional Embeddings).
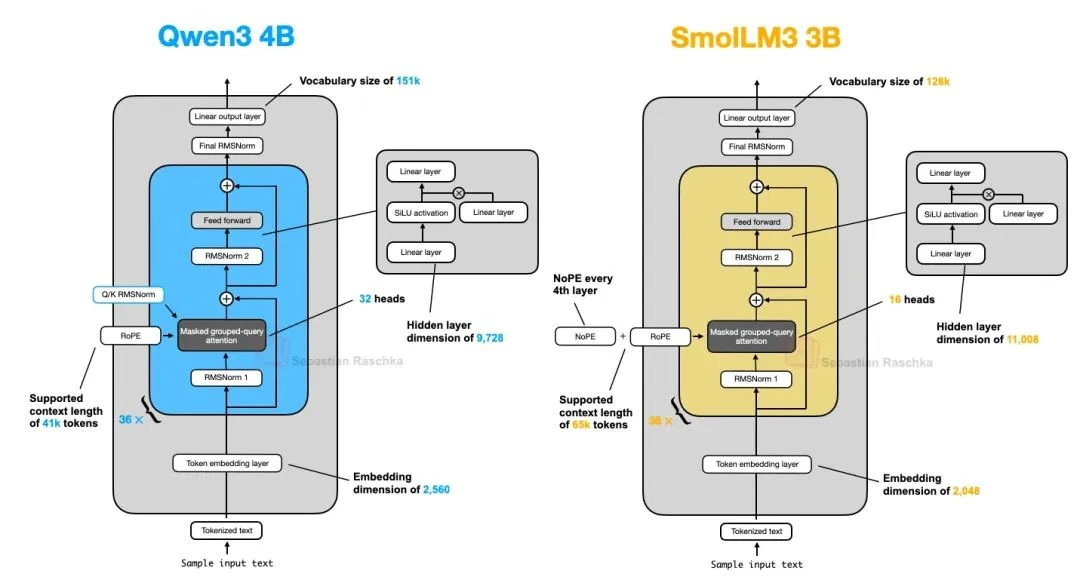
The concept of NoPE isn't new; it dates back to a 2023 paper, The Impact of Positional Encoding on Length Generalization in Transformers[23]. It involves removing any explicit injection of positional information, like the absolute positional embeddings of early GPTs or the now-common RoPE.
In Transformers, positional encodings are generally considered essential because the self-attention mechanism is permutation-invariant—it treats tokens as an unordered set. Positional encodings solve this by adding information about a token's place in the sequence.
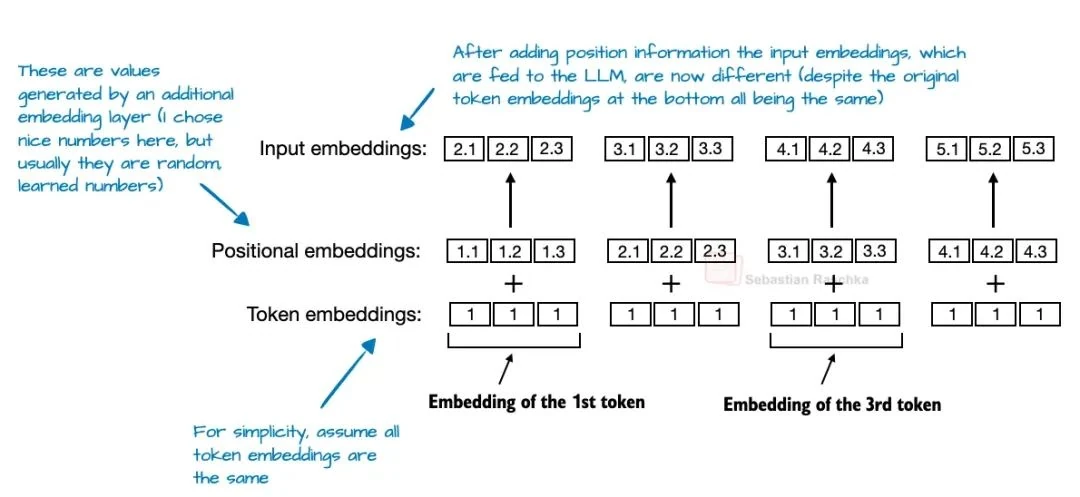
RoPE, for instance, rotates the query and key vectors based on their position. With NoPE, however, no such signal is added. Nothing.
So how does the model know the order of the tokens? The answer lies in the causal attention mask. This mask prevents a token from attending to any future tokens. A token at position t can only see tokens at positions ≤ t, which inherently preserves the autoregressive order. While no explicit positional data is injected, an implicit sense of directionality is baked into the model's structure, which the LLM can learn to leverage during training.
The NoPE paper[24] found that not only is explicit positional information unnecessary, but models without it also show better length generalization—their performance degrades less as sequence length increases.
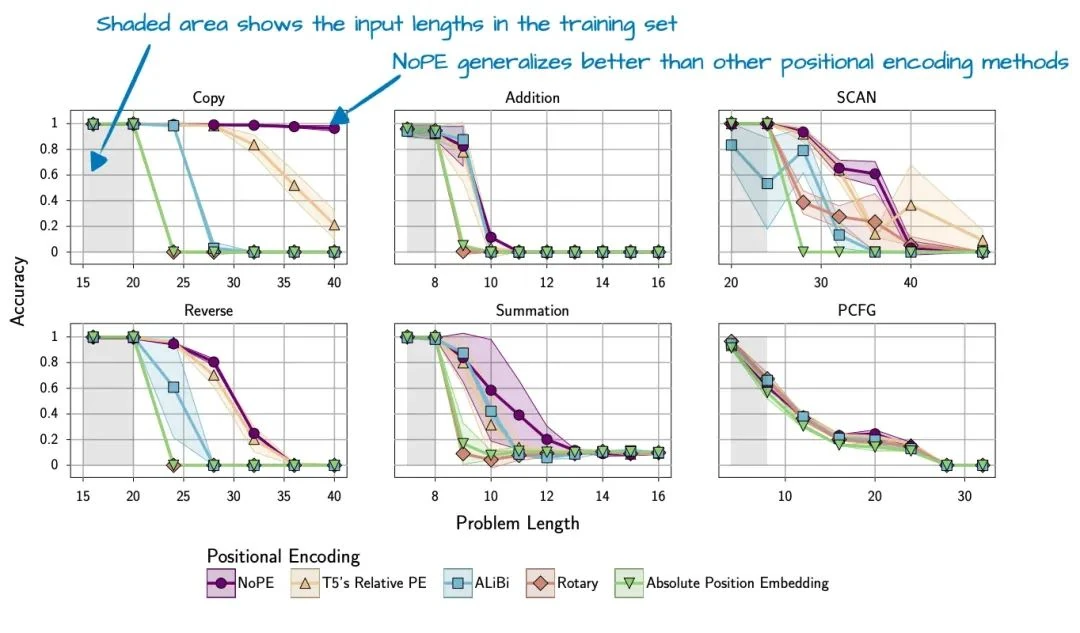
For this reason, the SmolLM3 team likely "applied" NoPE (or rather, omitted RoPE) in every fourth layer of their model.
Kimi 2
Kimi 2[25] recently took the AI community by storm, delivering incredible performance for an open-weight model. Benchmarks place it on par with top proprietary models from Google, Anthropic, and OpenAI.
One notable detail is its use of the relatively new Muon[26] optimizer instead of the standard AdamW. To my knowledge, this is the first time Muon has been used to train a production model of this scale (it had previously only been demonstrated up to 16B parameters[27]). The result was a beautifully smooth training loss curve, which may have helped propel the model to the top of the leaderboards.
While some have commented that the loss curve is too smooth, I don't find it abnormal (compare it to the OLMo 2 curve, for instance). What is truly impressive is how steadily the loss decays.
But as I mentioned at the start, training methods are a topic for another day.
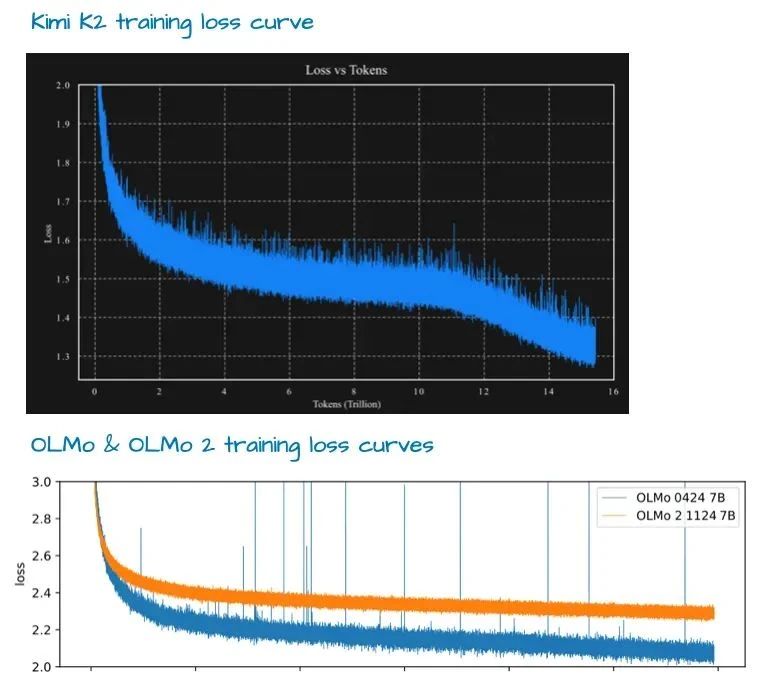
The model itself boasts a staggering 1 trillion parameters, making it a true titan. It is likely the largest LLM of this generation (given Llama 4 Behemoth is not yet released and proprietary models don't count).
This also brings our architectural tour full circle. Kimi 2 is built on the DeepSeek-V3 architecture we started with—they just scaled it up significantly, as shown below.
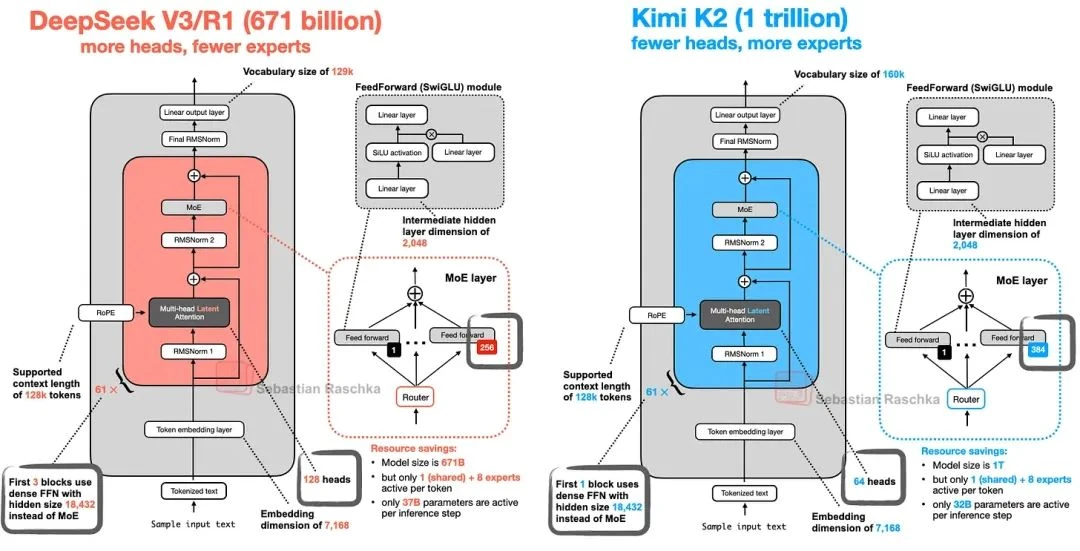
As you can see, Kimi 2 is essentially a supersized DeepSeek-V3, with more experts in its MoE modules and fewer heads in its Multi-Head Latent Attention (MLA) modules.
Kimi 2 didn't appear out of nowhere. The team's earlier Kimi 1.5 model was also highly impressive, but its paper[29] was unfortunately published on the same day as the DeepSeek R1 paper, and its weights were never publicly released.
The Kimi K2 team seems to have learned from this, sharing Kimi K2 as an open-weight model and securing its place as one of the most impressive open models available today.
All these years later, the world of LLMs is as exciting as ever. I can't wait to see what comes next.
- DeepSeek R1
- DeepSeek V3
- Original GQA paper
- Llama 2 paper
- DeepSeek-V2
- DeepSeek MoE from 2024
- DeepSpeedMoE paper from 2022
- OLMo 2
- Xiong, 2020
- Qwen3 from-scratch implementation
- Scaling Vision Transformers paper
- The OLMo 2 team released a 32B variant with GQA 3 months later
- Gemma 3
- LongFormer paper from 2020
- Gemma 2
- Gemma 3n
- MatFormer
- Mistral Small 3.1 24B
- Llama 4
- I recently implemented Qwen3 from scratch (using pure PyTorch)
- Qwen2.5-MoE
- SmolLM3
- The Impact of Positional Encoding on Length Generalization in Transformers
- NoPE paper
- Kimi 2
- Muon
- Previously
- Switch Transformer
- Kimi k1.5: Scaling Reinforcement Learning with LLMs paper