GPU Performance from First Principles
The Core Challenges of GPU Performance
At the heart of modern AI and high-performance computing lies the GPU. But unlocking its full potential isn't always straightforward. To truly optimize performance, we need to understand the fundamental bottlenecks.

-
Challenge 1: Compute-Bound vs. Memory-Bound Operations
Not all tasks are created equal. Some operations, like large matrix multiplications, are compute-bound; their speed is limited by the GPU's raw number-crunching power. In contrast, operations common in convolutional networks are often memory-bound, bottlenecked by how quickly data can be moved from memory to the processing units. This distinction is a key reason for the success of Transformers—their architecture heavily favors matrix computations, allowing them to fully leverage the immense computational horsepower of modern GPUs.

-
Challenge 2: Underutilized Memory Bandwidth
Modern GPUs boast staggering memory bandwidth, but are we always using it effectively? A common issue is low instruction-level memory efficiency. In simple terms, a single instruction often fails to request enough data to saturate the GPU's massive memory pipeline. This leaves precious bandwidth on the table, creating a hidden performance ceiling.

Strategies for Maximizing Throughput
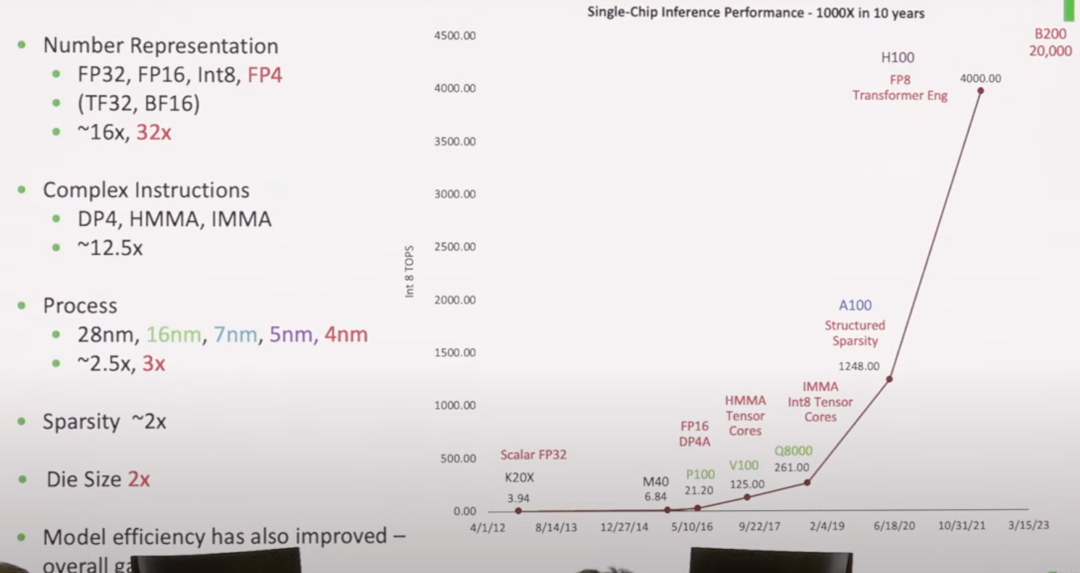
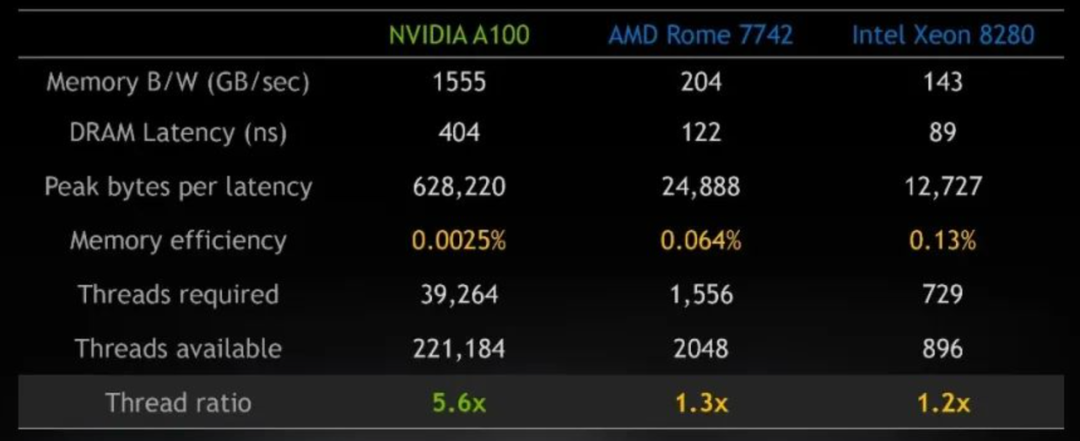
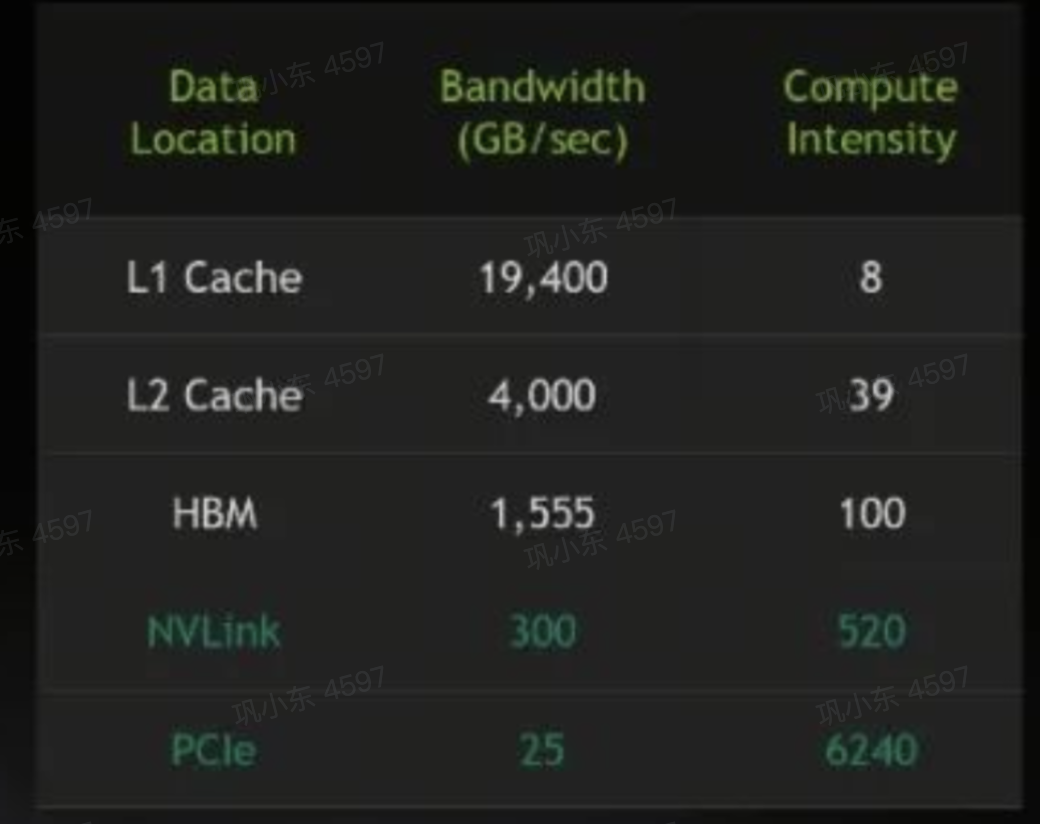
A Look at Concrete Implementations
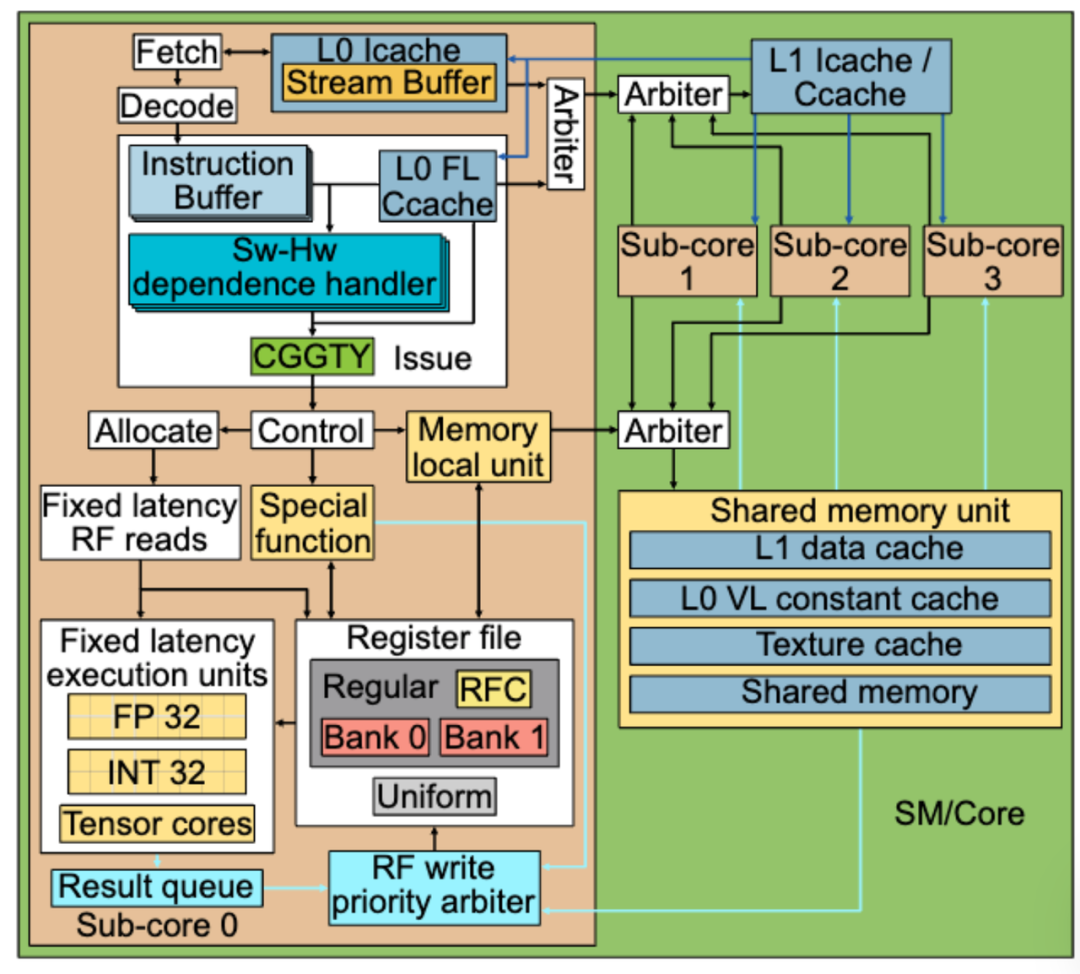
Note: The SM-to-SM (Streaming Multiprocessor) interconnect is not depicted in this diagram.
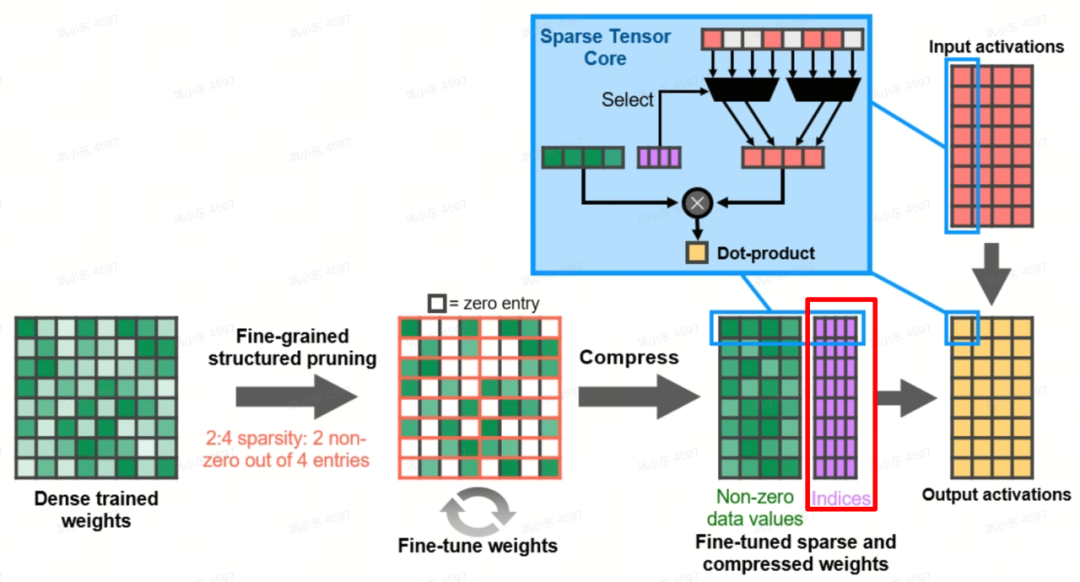
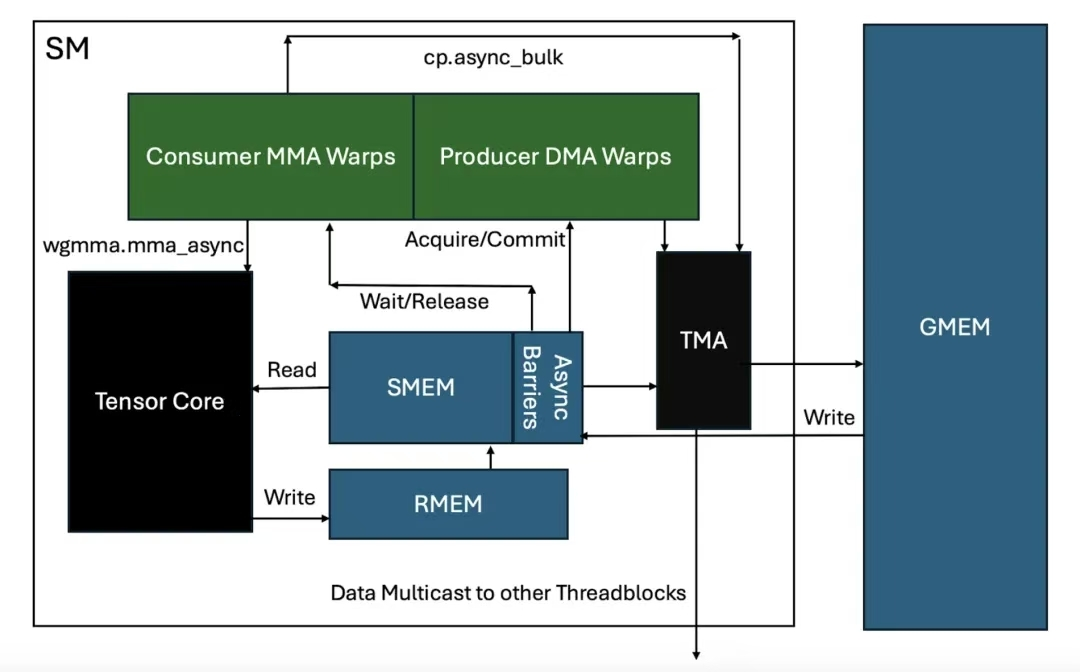
Q1: The Future of CPUs and GPUs: Will One Dominate the Other?
A1: It's less about domination and more about specialization. While GPUs excel at throughput for parallel tasks, their single-thread efficiency and latency are significantly lower than CPUs. Furthermore, hardware optimizations from vendors are reaching a point of diminishing returns, with no revolutionary breakthroughs on the immediate horizon.
A helpful analogy is the "controller vs. worker" model. In any efficient system, you have far more workers than controllers (workers >> controllers). The CPU acts as the high-level controller—managing tasks, handling complex logic, and directing traffic. The GPU is a massive team of specialized workers, executing parallel instructions with incredible speed.
Given this dynamic, CPUs will likely maintain their crucial role as the system's orchestrator, while GPUs will continue to evolve as powerful, specialized co-processors. The future is collaborative, not competitive.
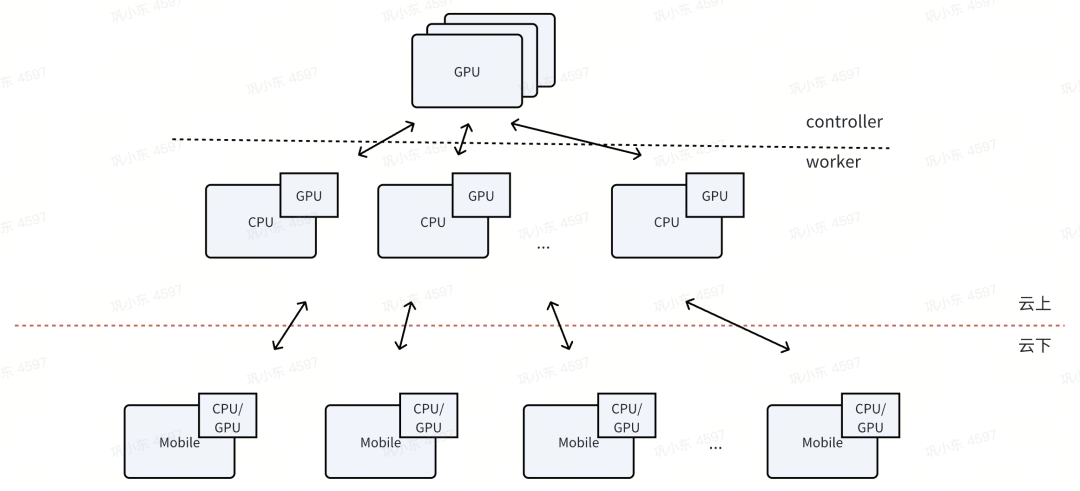
Q2: How will GPU architecture evolve?
A2: GPU architecture will advance on several key fronts. We can expect to see enhanced data representation capabilities, dedicated hardware for sparse matrix acceleration, and more sophisticated VRAM hierarchies. On the physical level, innovations in advanced chip packaging (like chiplets) and new transistor fabrication processes will continue to push the boundaries of performance and efficiency.
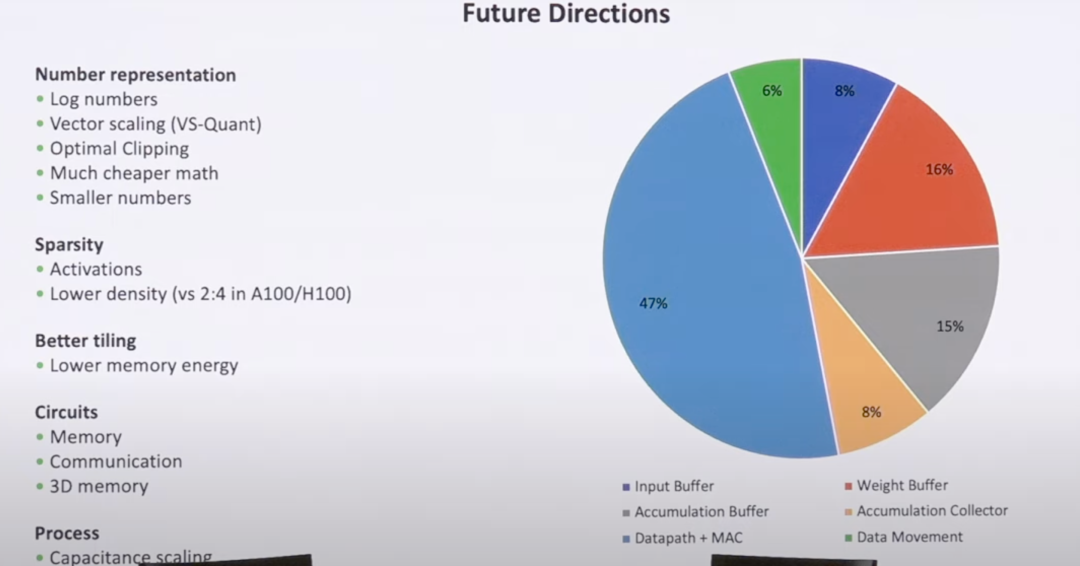
Q3: How will AI models co-evolve with hardware?
A3: AI models will become increasingly hardware-aware. The trend is moving towards using lower-precision data types (like FP8 or INT4) to fully leverage the massive throughput of specialized hardware like Tensor Cores. Additionally, techniques like weight sparsification will become more common, allowing models to run faster and more efficiently by reducing the overall computational load.