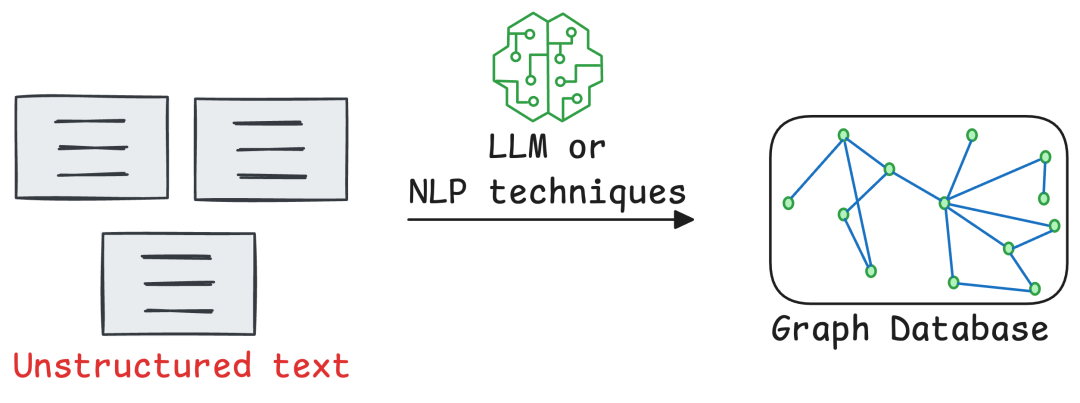
At its core, a graph database is built on two simple but powerful concepts: nodes and edges. Think of nodes as the key players—they can be anything from concepts and entities to entire documents or even smaller chunks of text. The edges are the connections, the vital relationships that link these nodes together, representing everything from similarity and references to complex hierarchies.
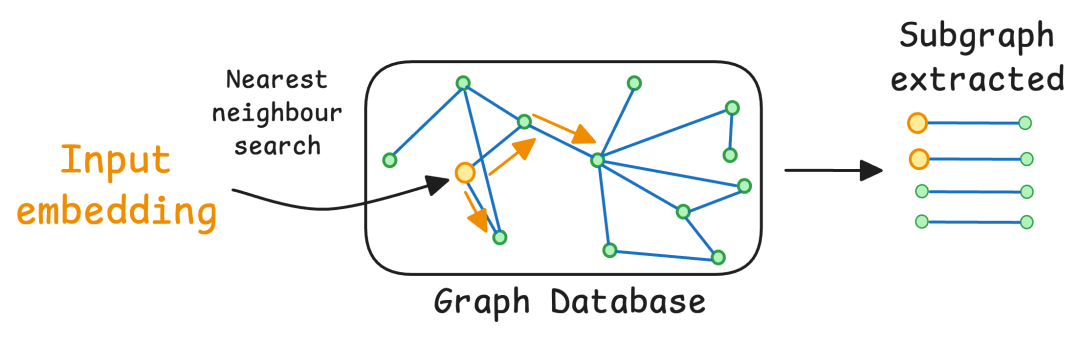
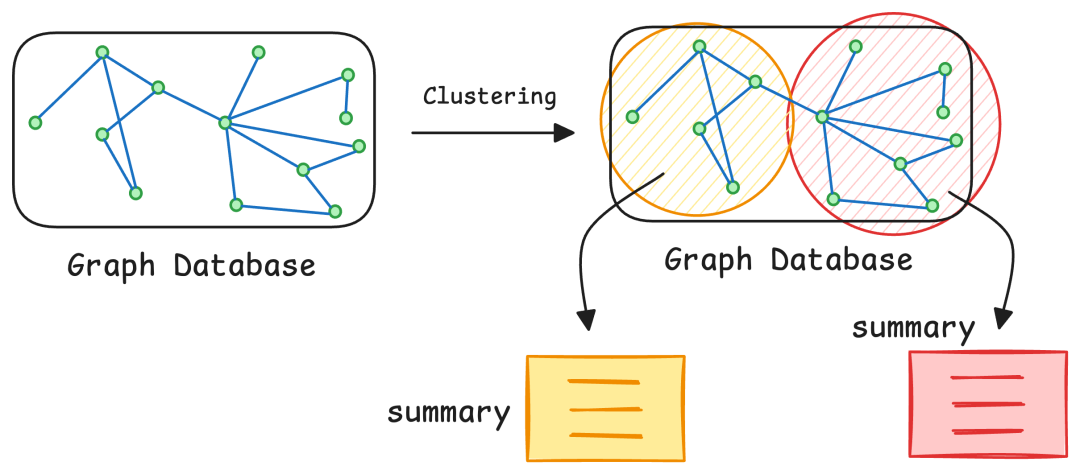
So, how does the system find what you're looking for? It kicks off a search by performing a nearest neighbor search or a graph traversal. This process is like starting a journey from a specific point on a map—in this case, from nodes that closely match the user's query. From there, the system intelligently navigates the graph, following the connecting edges to discover related information. The result is a highly relevant subgraph—a curated cluster of nodes and edges pulled from the larger database based on criteria like relevance scores, the number of connections a node has (its degree), or its proximity to the original query.

But the magic doesn't stop there. To achieve pinpoint accuracy, the system can layer on more sophisticated techniques. Graph-specific metrics like centrality (how important a node is within the network) or edge weights (the strength of a connection) are used to prioritize the most influential nodes. On top of that, metadata filters—like date, source, or content type—allow for on-the-fly refinement, making this approach incredibly powerful for real-time applications where context is king.