With its impressive performance and elegant architecture, SGLang is rapidly establishing itself in the competitive world of large language model (LLM) inference. Could it be the next PyTorch, poised to challenge the status quo in LLM deployment? After extensive custom development on SGLang, I've gained unique insights into its disaggregated inference design and share key takeaways for practitioners and researchers.
Understanding LLM Inference Phases: Prefill vs. Decode
At the core of LLM inference are two distinct phases: prompt processing (prefill) and token generation (decode).
- KV cache: Stores intermediate results from previous tokens, enabling efficient sequential generation.
- SLA: Service Level Agreement, ensuring performance or reliability targets.
- Continuous batching: Continuously adds new requests to a batch for optimal hardware utilization.
Prefill Phase: Compute-Bound Parallelism
During the prefill phase, the system processes all tokens in the initial prompt in parallel. This operation can saturate GPU compute resources, especially with large batch sizes or long prompts.
Decode Phase: Memory-Bound Sequential Processing
In contrast, the decode phase generates tokens one by one, a sequential process that often underutilizes GPU parallelism.
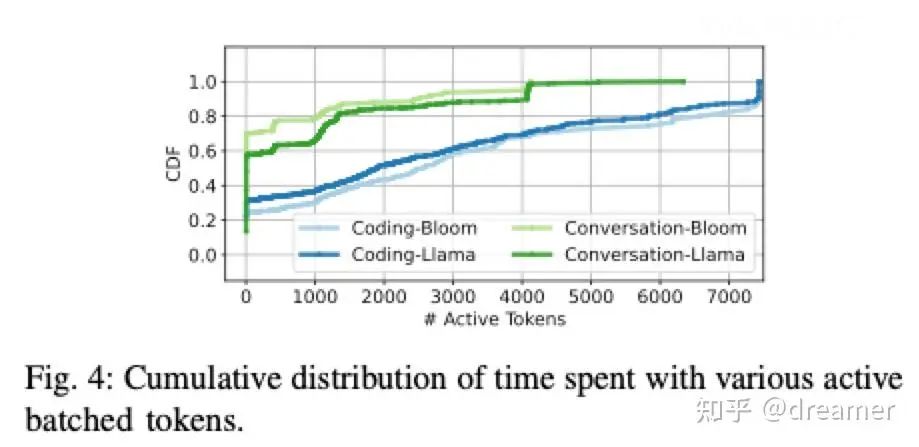
These phases have conflicting demands. Benchmarks show most inference time is spent in the generation phase, typically processing only a few tokens at a time. Increasing batch size can boost GPU utilization, but in a traditional, co-located architecture (where both phases run on the same GPUs), optimizing for one phase can hinder the other.
Throughput and Memory Bottlenecks
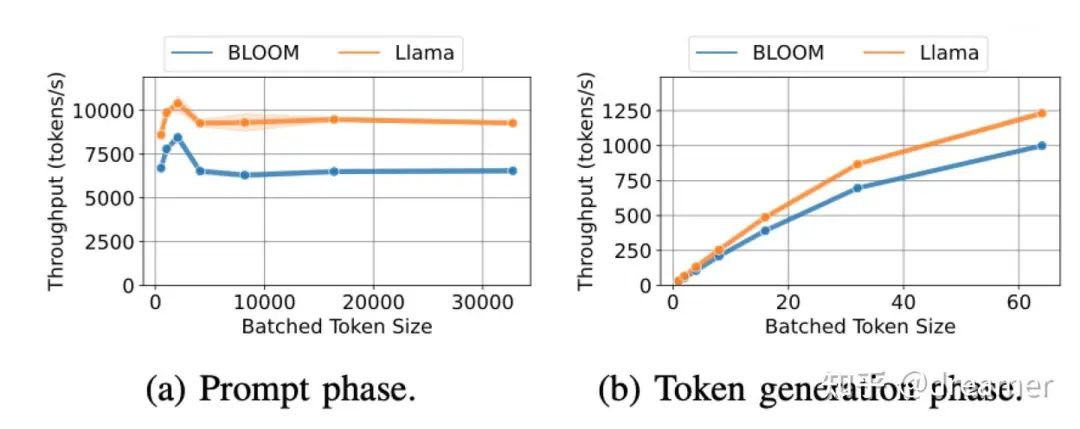
During prefill, throughput drops if the batch size is too large. Conversely, in the generation phase, throughput increases with batch size until the system hits out-of-memory (OOM) limits.
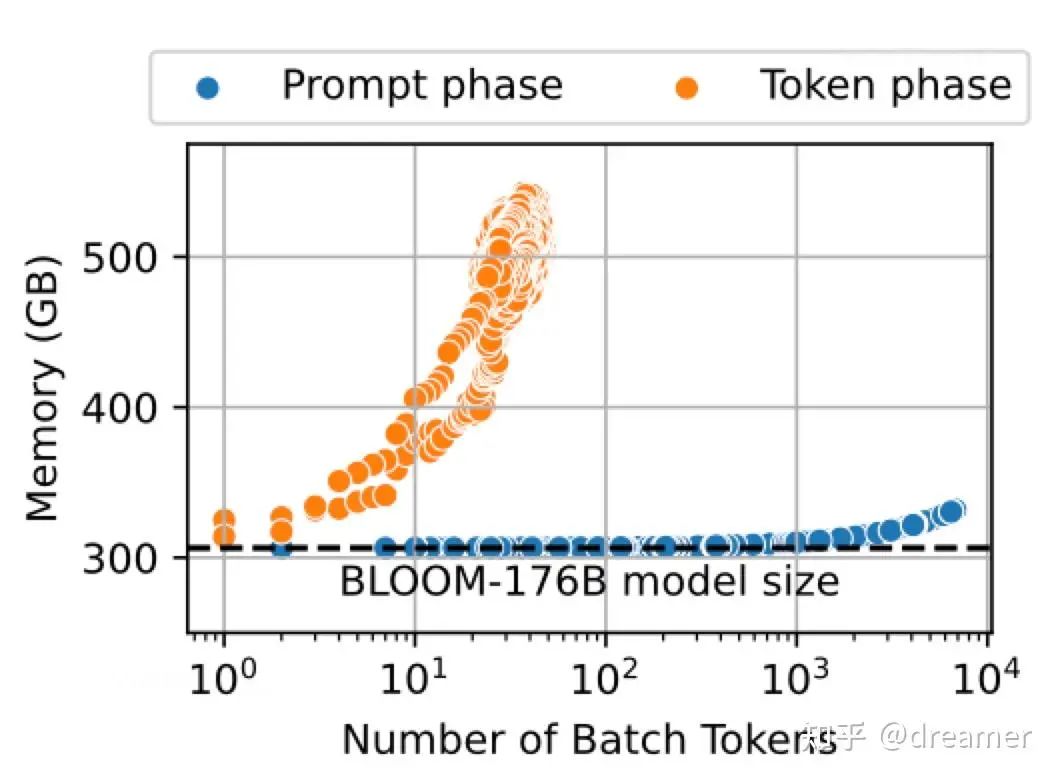
The generation phase is memory-hungry, as each new token requires access to the KV cache of all previous tokens. Thus, prefill is compute-bound, while generation is memory-bound. Running both phases on the same hardware is inefficient and costly, limiting optimization opportunities.
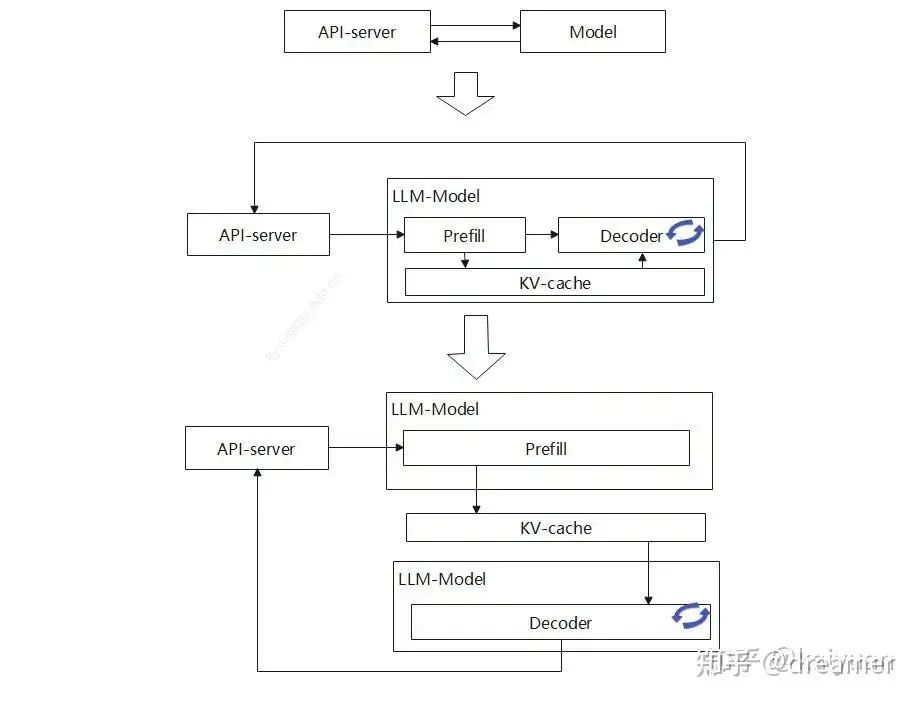
Disaggregated Inference: Overcoming Latency Challenges
Why not separate prefill and decode? The main challenge is the latency of transferring the large KV cache between clusters. This transfer can significantly delay token generation.
Latency Hiding via Layered KV Cache Transfer
A solution is latency hiding—transferring the KV cache in layers and overlapping data transfer with computation.
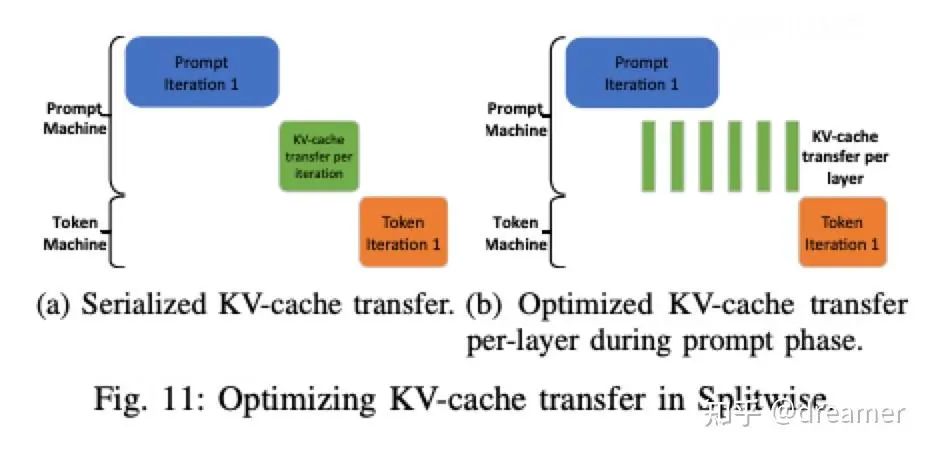
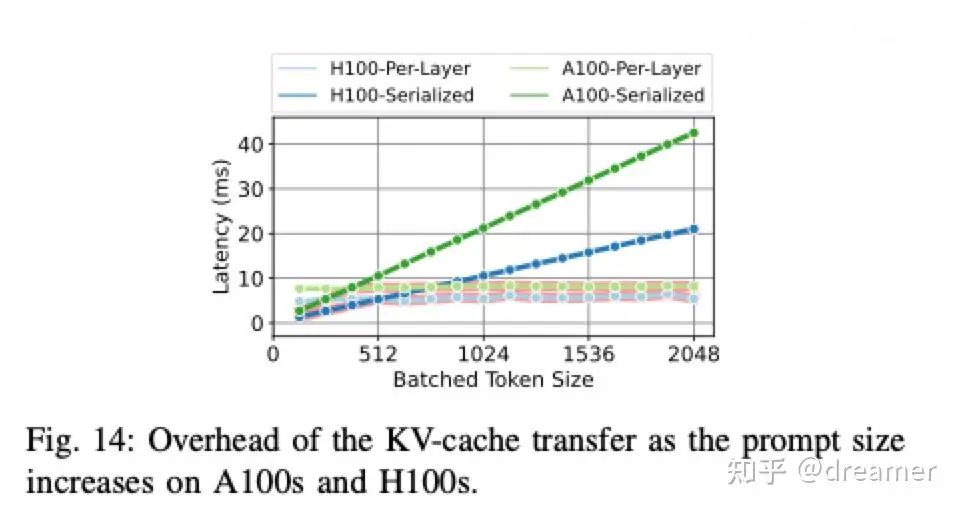
By overlapping transfer and computation, idle time is minimized. The non-overlapped transfer takes about 8ms, regardless of prompt length. Since a single token generation step takes 100-120ms, this overhead adds only ~7% to latency, mainly affecting the first token. Subsequent tokens are barely impacted.
When to Use Prefill-Decode (PD) Separation
PD separation is most beneficial when prompt length exceeds 10 tokens, as suggested by NVIDIA researchers. For shorter prompts, co-located setups may perform better.
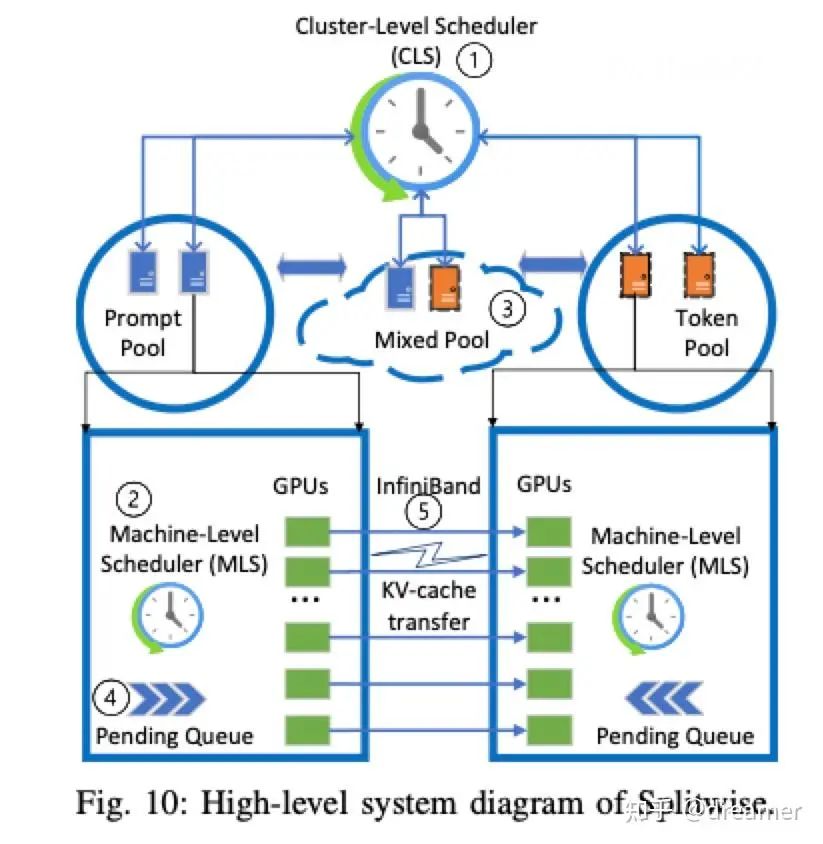
Hybrid Scheduling Architectures
Modern systems use hybrid architectures for optimal resource allocation:
- Cluster Level Scheduler (CLS): Manages a heterogeneous cluster, with dedicated prefill, decode, and mixed pools.
- Machine Level Scheduler (MLS): Handles request scheduling and reports status to the CLS.
- Layer-wise KV Cache Transfer: Overlaps prefill computation with data transfer, optimizing Time To First Token (TTFT).
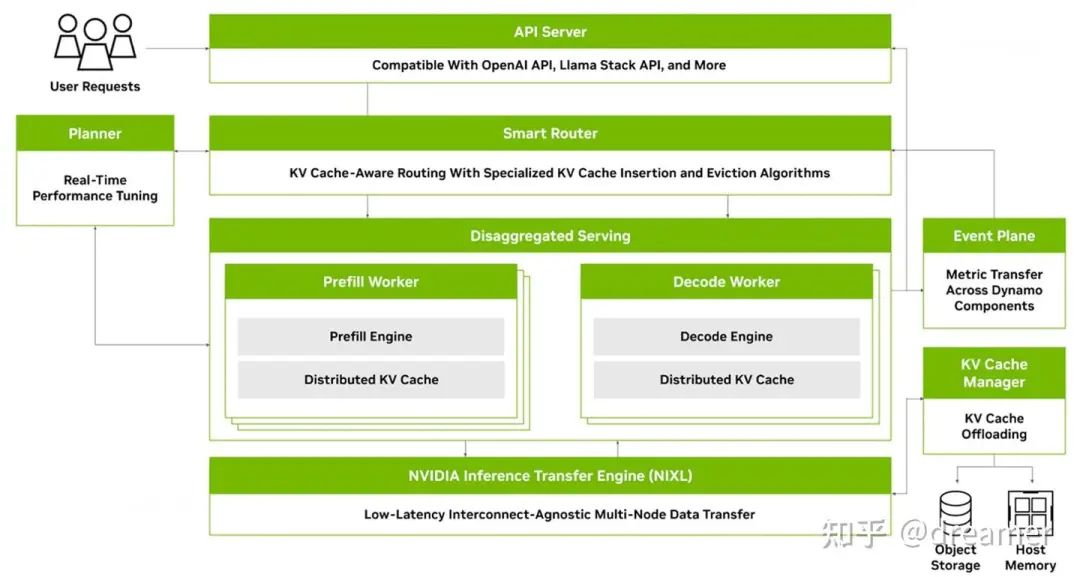
Smart routers are emerging to dynamically direct traffic based on these principles.
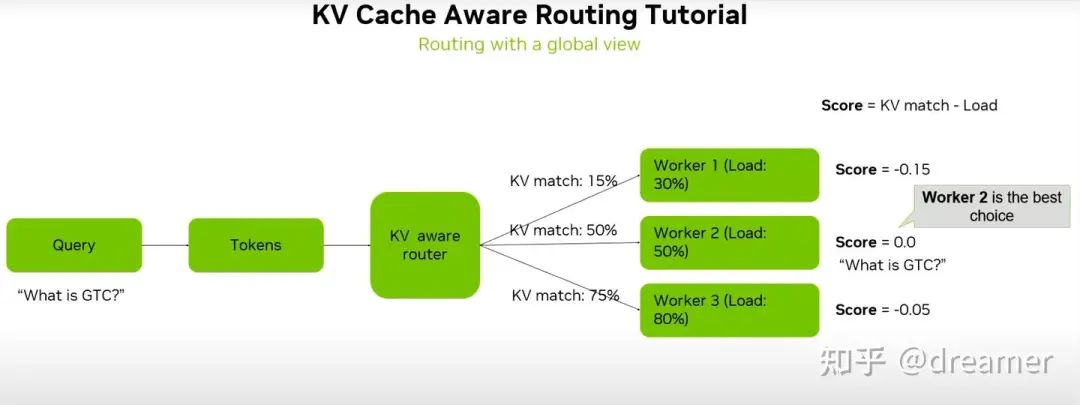
The Next Step: AI-Driven Planners
The future is a "planner"—an AI agent using reinforcement learning to manage auto-scaling, meet SLAs, and enable hybrid deployment of multiple models on shared infrastructure.
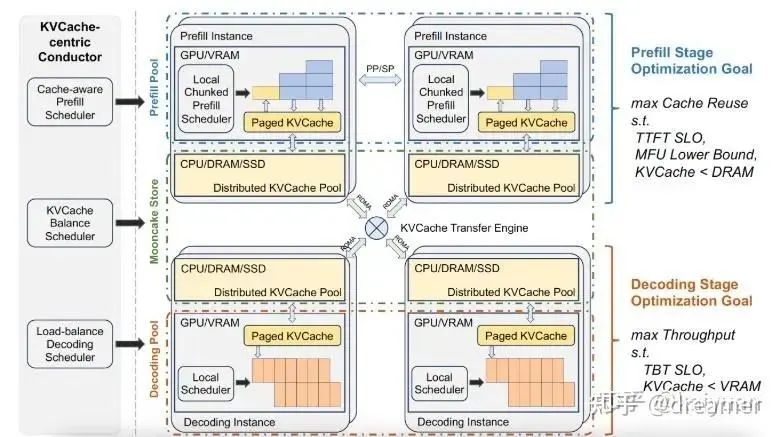
A robust system should process requests up to a load threshold, then gracefully reject or queue excess requests. This avoids wasted computation if a request completes prefill but stalls at decode. Mooncake, the engine behind SGLang's disaggregation, uses an "early exit" strategy based on real-time GPU availability. The trade-off: this approach is currently incompatible with continuous batching.
Implementation Details: State Machines and Queues
For each request, the system creates a "sender" (prefill) and a "receiver" (decode). A state machine orchestrates the end-to-end process, moving requests through several queues.
State Machine Coordination (TCP Handshake Analogy)
Requests progress through states, similar to a TCP connection state machine.
Dedicated Queues Per State
Prefill Side Queues:
- Waiting for prefill
- Undergoing prefill
- Waiting for KV cache transfer
Decode Side Queues:
- Incoming KV cache transfers
- Waiting for resource allocation
- Ready for token generation
Implementation Flow


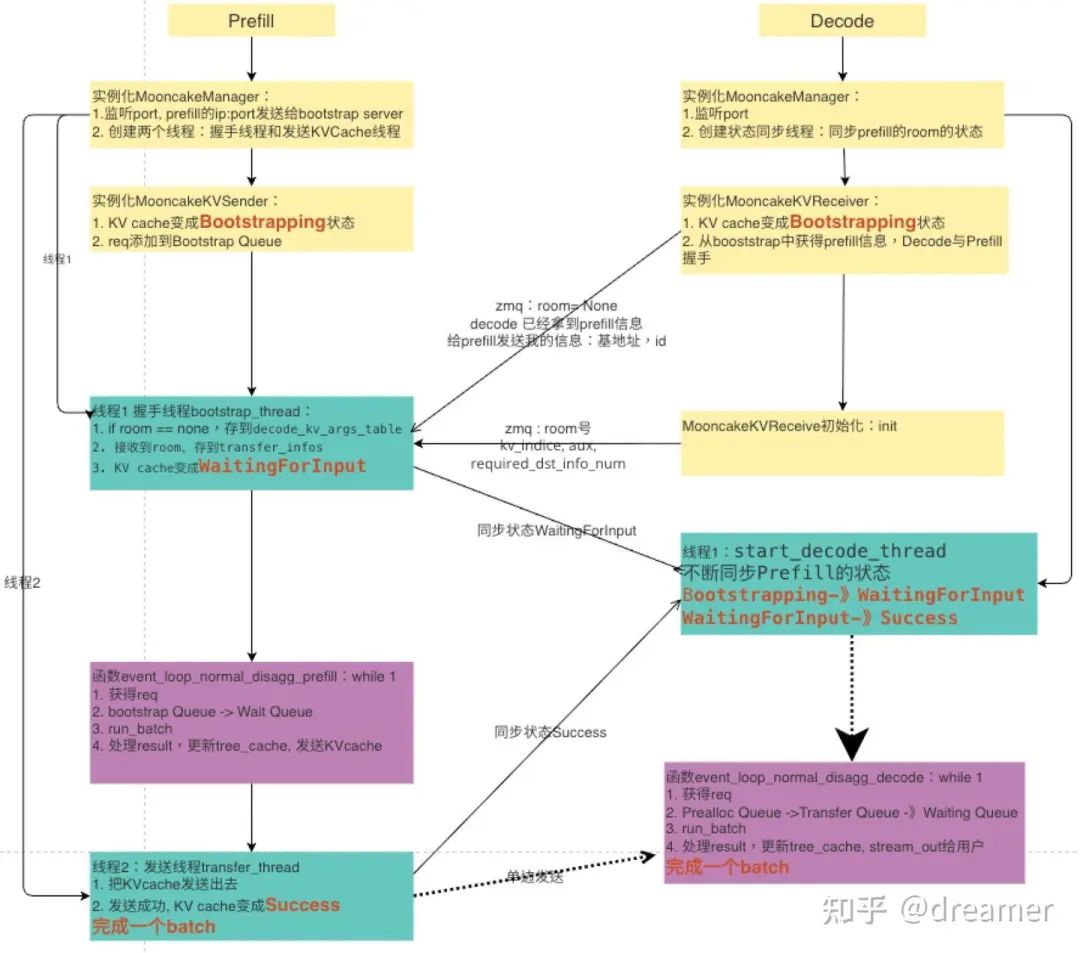
(In the optimized version, data transfer for the previous layer overlaps with computation for the current layer.)
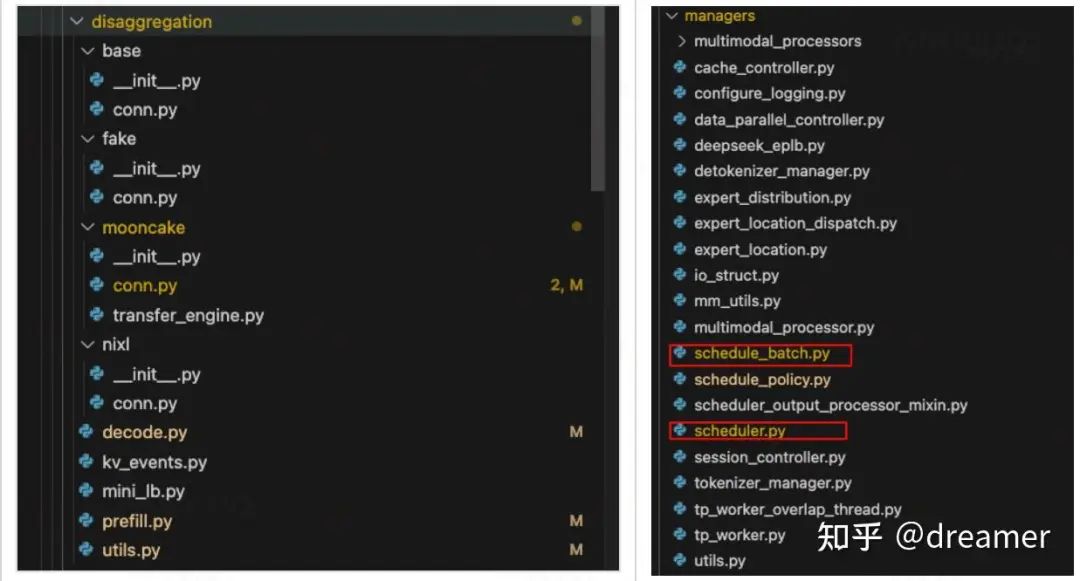
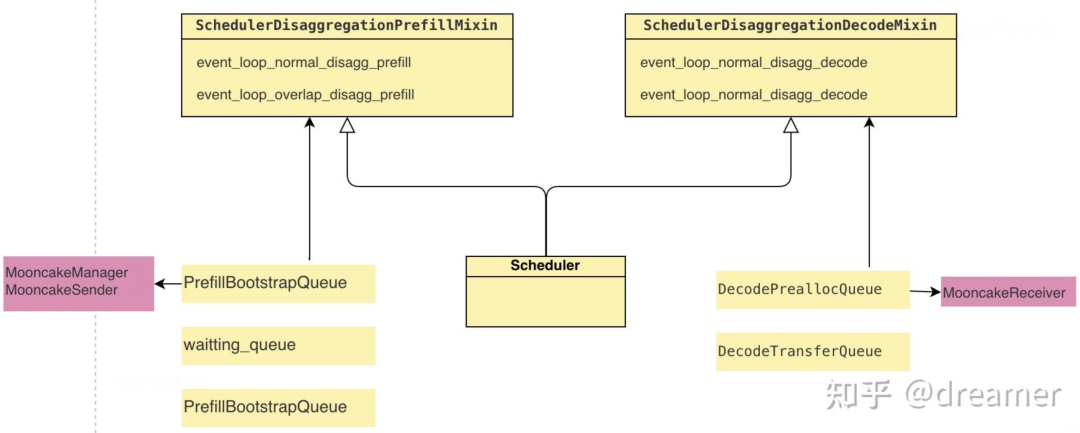
Key Classes and Functions in SGLang & Mooncake
class PrefillBootstrapQueuefunction event_loop_normal_disagg_prefillclass DecodePreallocQueueclass DecodeTransferQueuefunction event_loop_normal_disagg_decodeclass MooncakeKVManager(BaseKVManager)class MooncakeKVSender(BaseKVSender)class MooncakeKVReceiver(BaseKVReceiver)
For further exploration, review these classes in the SGLang repository. Mooncake is the open-source inference framework from Moonshot AI powering SGLang's KV cache transfer. The C++ binding is in transfer_engine_py.cpp.
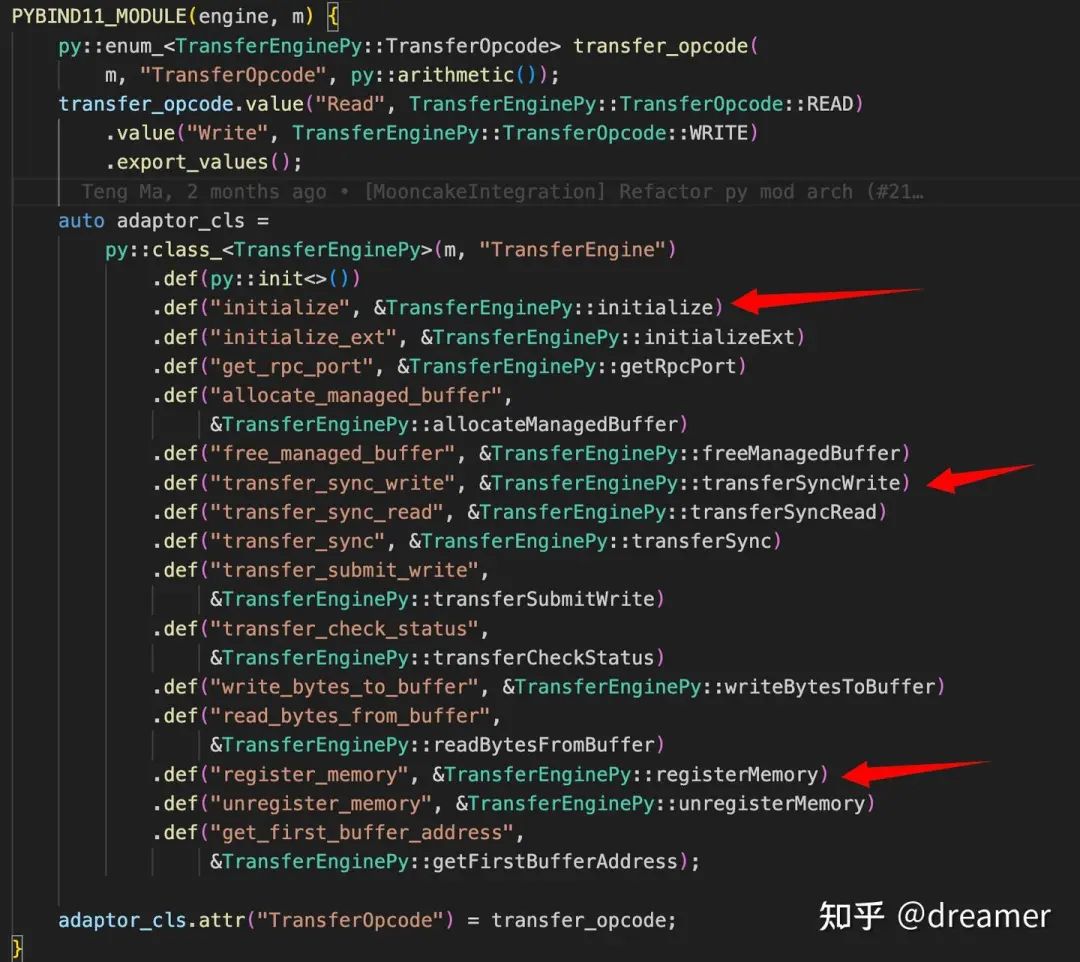
Core C++ Functions:
TransferEnginePy(): Initializes the engine.initialize(): Sets up transfer resources.transferSyncWrite(): Executes synchronous data transfer.registerMemory(): Manages memory registration.
Supplement: RDMA Primer for LLM Inference
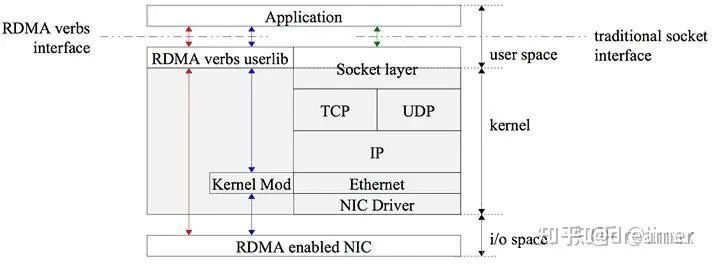
RDMA (Remote Direct Memory Access) allows direct memory access between computers, bypassing CPUs and operating systems. Supported protocols include InfiniBand, RoCE, and iWARP.
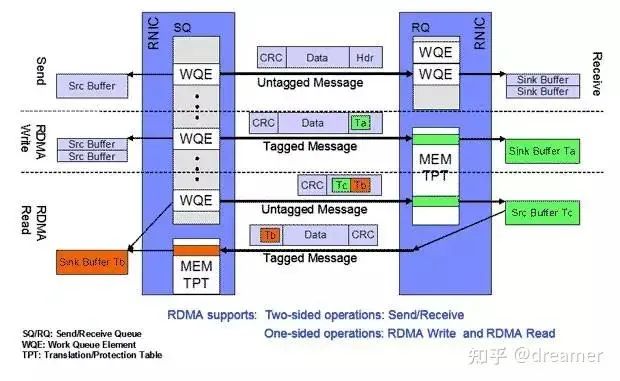
Mooncake uses one-sided RDMA operations (READ and WRITE), enabling direct memory access with minimal CPU involvement. The RDMA-enabled NIC manages transfers, making the process fast and efficient.
Key Performance Metrics for LLM Inference

Common metrics for evaluating LLM inference systems include:
- Throughput
- Latency (Time Per Output Token, Time To First Token)
- SLA compliance
- GPU utilization
Conclusion
SGLang, powered by Mooncake's disaggregated inference engine and advanced RDMA, is redefining large model inference. By separating and optimizing prefill and decode phases, and leveraging hybrid scheduling and resource management, SGLang unlocks new efficiency and scalability for LLM deployments. These architectural insights are essential for building high-performance AI inference systems.