Maximizing LLM Inference Throughput on H800 SuperPods
When serving Large Language Models (LLMs), the central challenge is maximizing throughput while maintaining low latency. To explore the performance frontier of modern GPU clusters, we pushed a disaggregated LLM inference architecture to its limits on a 13×8 H800 DGX SuperPod. Our objective was to measure the maximum effective throughput—or 'goodput'1—for both the prefill and decode stages of LLM serving. This was done while adhering to strict Service Level Objectives (SLOs): a Time to First Token (TTFT) under 2 seconds and an Inter-Token Latency (ITL) below 50ms. We tested a variety of server-side disaggregated configurations, including (P3x3)D4, P4D9, and P4D6. Across these setups, our system achieved an impressive input throughput of approximately 1.3 million tokens/second and a maximum output throughput of 20,000 tokens/second. However, a clear pattern emerged: in most high-load scenarios, the prefill stage became the primary performance bottleneck, critically impacting the Time to First Token.
Guided by the 1.4 decode-to-prefill node ratio derived from the DeepSeek workload2, we hypothesized that larger prefill node groups (e.g., P=3) combined with smaller Tensor Parallelism (TP) sizes (TP=24) could boost server-side goodput. We started by assessing performance with SGLang's bench_one_batch_server.py script3 to test the raw responsiveness of the URL API endpoint. For more robust measurements, we then switched to genai-bench4 to evaluate output throughput under various concurrency levels.
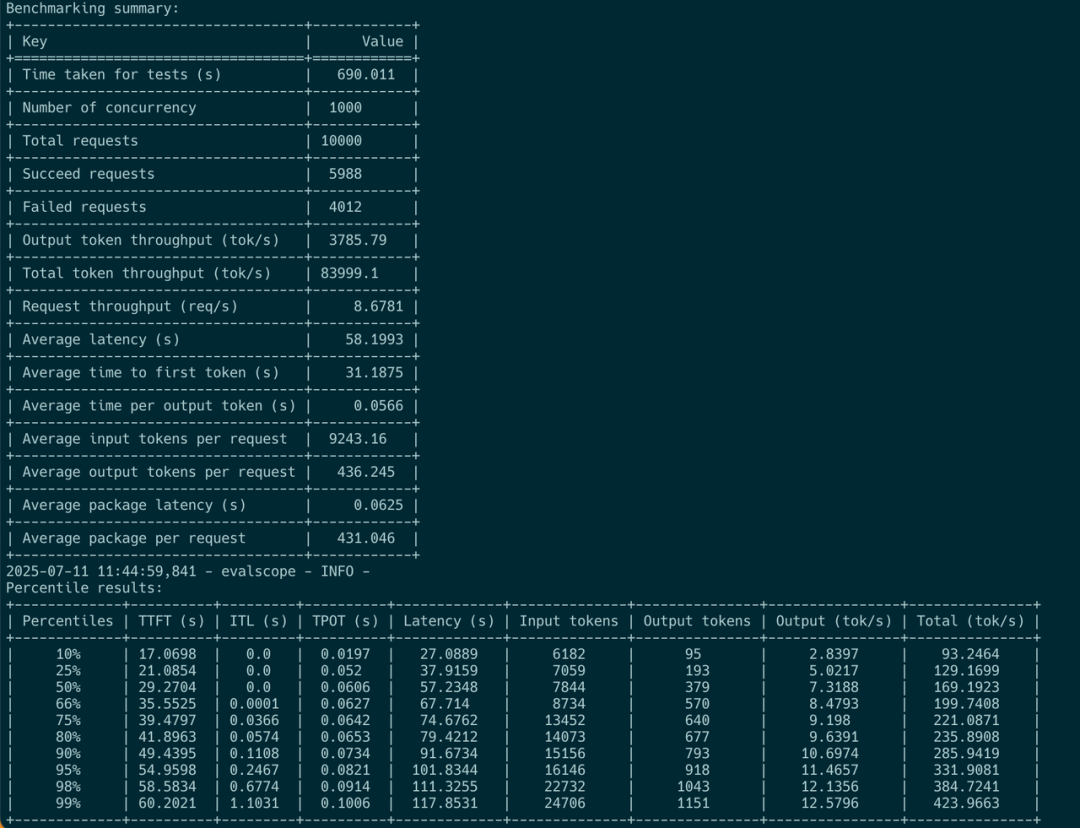
On the client side, we used evalscope5 for real-time observation and evaluation of our OpenAI-compatible API. For small input requests, the system performed well, maintaining an output of 25,000 tokens/sec at a concurrency of 50, and increasing to 55,000 tokens/sec at a concurrency of 150. However, we encountered a performance wall when the product of batch_size × input_length crossed a certain threshold. At that point, the TTFT skyrocketed—a behavior we suspect is tied to limitations in KV cache transfer speeds6.
This led to another key insight for optimizing LLM inference: to maximize goodput, maintaining a specific ratio of Input Sequence Length (ISL) to Output Sequence Length (OSL) is critical. Our tests showed a 4:1 ratio to be optimal. When pushing for high throughput by increasing batch size and sequence length, the total latency becomes dominated by TTFT. To maintain high GPU utilization and healthy goodput, it is crucial to keep concurrency below 128 to prevent TTFT from spiraling. This balancing act proved particularly effective on our H800 DGX SuperPod system, as uncontrolled TTFT destabilizes output throughput and severely degrades overall server-side performance.
The Shift to Disaggregated Architecture for LLM Inference
In a traditional, colocated (non-disaggregated) inference architecture, both prefill and decode tasks run on the same set of GPUs. Before Q2 2024, vLLM used an interleaved scheduling scheme for prefill and decode tokens, which was later upgraded to a continuous scheduling mechanism to improve GPU utilization7.
However, this approach does not address a fundamental problem in LLM serving: the computational demands of the prefill and decode stages are vastly different. Continuously batching full, un-chunked prefill tokens from new requests alongside decode tokens from ongoing requests inevitably inflates decode latency. The result is a high Inter-Token Latency (ITL), which makes the system feel sluggish and unresponsive.
To combat this, the chunk-prefill feature was introduced in PR#31308. This technique allows prefill tokens from new requests to be broken into smaller chunks and batched with decode tokens from active requests. As the diagram below illustrates for a homogeneous deployment, this feature helps lower ITL and boost GPU utilization.

But even chunked prefill doesn't fully resolve the core computational mismatch. The decoding process, for instance, typically relies on CUDA Graph to capture and optimize multi-step generation computations. When a decode task is batched with a chunked prefill, CUDA Graph cannot be used, introducing significant overhead.
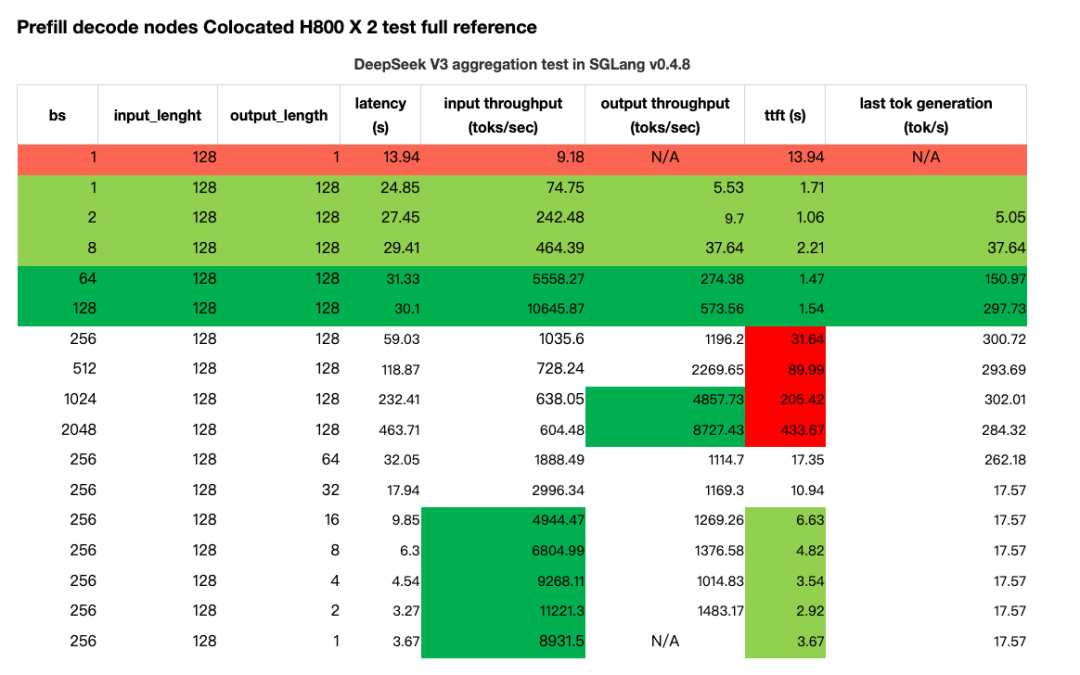
Furthermore, as observed by the DistServe team891 with a 13B dense model—and confirmed by our own experiments with a massive 671B MoE model—in a colocated system, once batch_size × output_length exceeds a certain point (e.g., 128 batch size × 128 output length), the computational cost of prefill explodes, regardless of the chunk size.
This is what led to the proposal of a disaggregated serving architecture in reference [4]. This disaggregated architecture separates prefill and decode tasks onto different, specialized groups of GPUs. Building on this foundation, DeepSeek further slashed latency and boosted throughput using their DeepEP and MLA technologies, which were quickly integrated into SGLang. On a P4D18 deployment, their system achieved an astonishing 73.7k tokens/node/sec (input) and 14.8k tokens/node/sec (output) while meeting SLOs.
Optimizing the Prefill/Decode (P/D) Ratio on H800
The success of disaggregation has led to a common misconception: that the number of prefill (P) nodes should never exceed the number of decode (D) nodes. In reality, DeepSeek never publicly disclosed the exact P-to-D node ratio used in their production systems10.
However, we can perform a back-of-the-envelope calculation based on their published data. They reported a daily service volume of 608B input tokens and 168B output tokens. Using their stated token processing speeds, we can reverse-engineer the approximate number of nodes dedicated to each stage:
- Total Prefill Nodes: 955
- Total Decode Nodes: 1314
This gives us a Decode/Prefill node ratio of roughly 1.4 (1314 / 955). If we apply this to their P4D18 group configuration, the ratio of groups would be 3.27 : 1, calculated as (955 nodes / 4 nodes per group) : (1314 nodes / 18 nodes per group). This pointed us toward (P3x2)D4, (P3x3)D4, and (P4x2)D4 as promising candidates for our own tests.
For our H800 13x8 DGX SuperPod setup, our analysis consistently showed that the prefill stage was the most likely system bottleneck. This insight drove our strategy: we limited the Tensor Parallelism (TP) size to a maximum of 4. A larger TP size would slow down inference, while a smaller one would not reserve enough memory for the KV cache—a classic engineering trade-off.
In our tests, the (P3x3)D4 and P4D6 configurations delivered significantly better TTFT than P9D4. This is primarily because they use a smaller TP setting and possess greater overall prefill computation capacity.
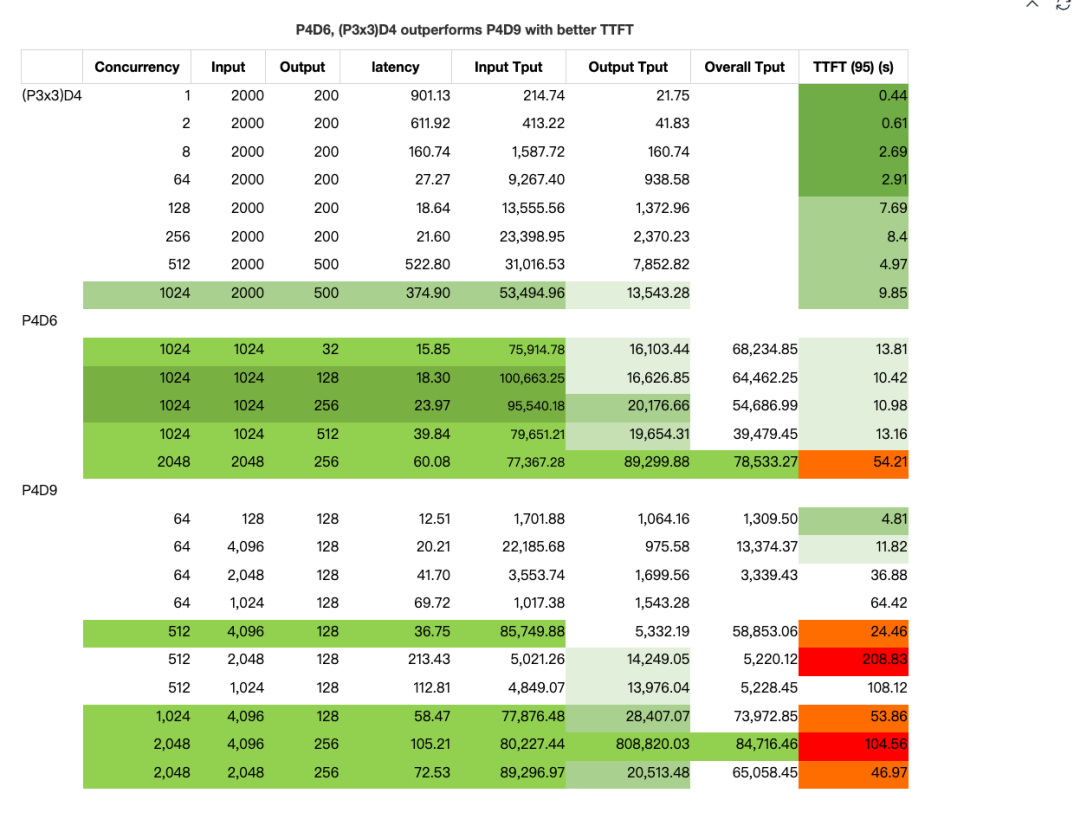
Using SGLang v0.4.8 and our own fine-tuned model (similar to DeepSeek V3, 0324 version), we validated these results at scale across both colocated and disaggregated deployments.
For input sequence lengths ranging from 128 to 4096 tokens and shorter output lengths from 1 to 256 tokens, we tuned various batch sizes and reached the following conclusions:
Deploying a massive 671B MoE model (with 8 out of 256 experts enabled, plus P * 8 redundant experts) presents different challenges than deploying a 13B dense model like in the DistServe paper891. We found that its prefill goodput is inversely affected by the product of output_length × batch_size; as this product grows, goodput steadily decreases before hitting its floor. A detailed statistical analysis is available in the appendix.
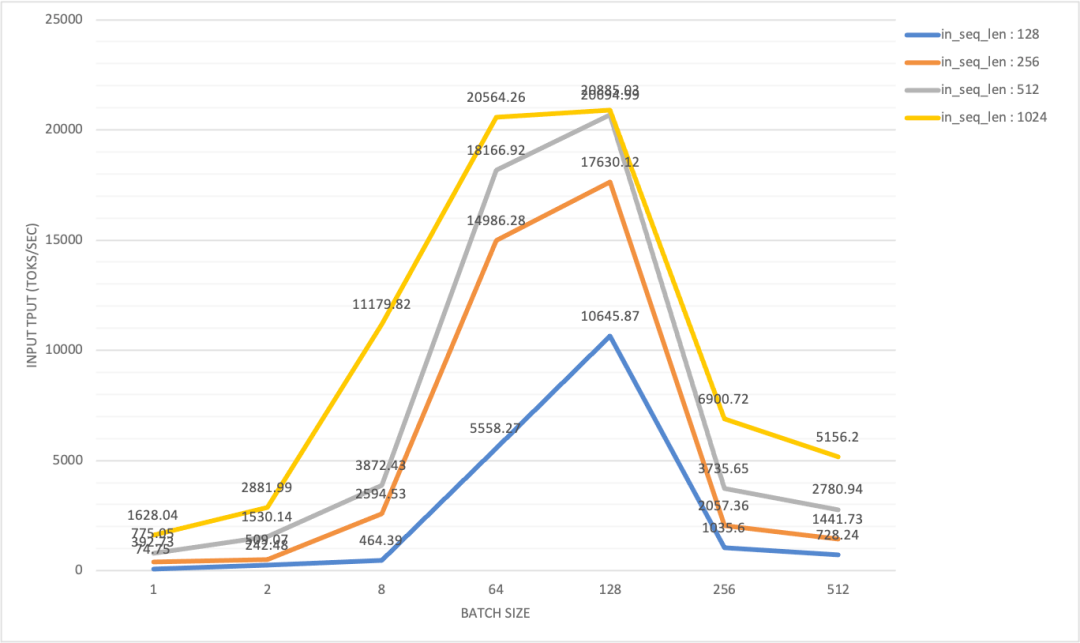
In an H800 x 2 (DGX SuperPod) test configuration with InfiniBand interconnects, the maximum input throughput hovered around 20k tokens/sec:
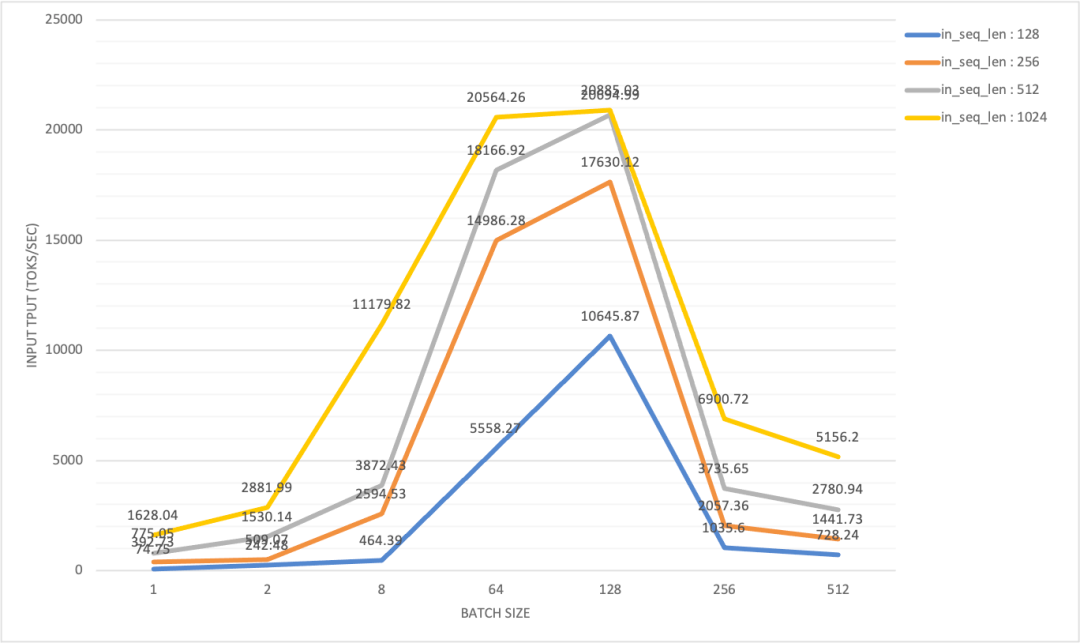
When the product of batch size and output length surpassed 128×128, we saw a dramatic drop in input throughput, accompanied by a sudden, sharp spike in TTFT. In contrast, the output throughput climbed steadily with the batch size, eventually reaching its peak.
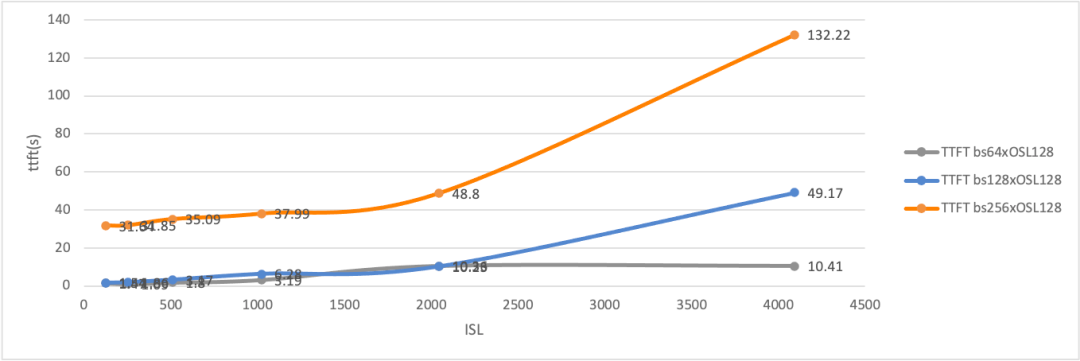
These statistics all point to one conclusion: maximizing prefill and decode throughput requires fundamentally different workload patterns. In a disaggregated architecture, the effective throughput (goodput) of prefill nodes—even with an optimal chunk-prefill size and TP scale—is ultimately capped by the KV cache transfer speed, which becomes the bottleneck at a certain batch size6.
Inside SGLang: Load Balancing in a Disaggregated Architecture
SGLang's Load Balancer service supports configurations with multiple prefill (P) and decode (D) nodes by accepting multiple master addresses for each role. This allows users to fine-tune the Tensor Parallelism (TP) scale, as prefill nodes can be configured with a smaller TP scale than decode nodes to achieve better TTFT.
Currently, two load balancers are available: the newer RustLB and the original MiniLoadBalancer. Both follow the same HTTP interface, redirecting requests to the appropriate prefill and decode servers, and their internal logic for handling incoming requests is identical.
The main issue with the current SGLang load balancer is its simplicity: it does not select a prefill and decode server pair based on real-time traffic or load. This means it cannot guarantee true load balancing across the prefill server pool.
During request processing, the prefill server always returns its result first to complete the KV cache generation. Drawing inspiration from Dynamo's workflow11, we've drafted a simplified flowchart of the SGLang P/D architecture using RustLB to clarify the process.
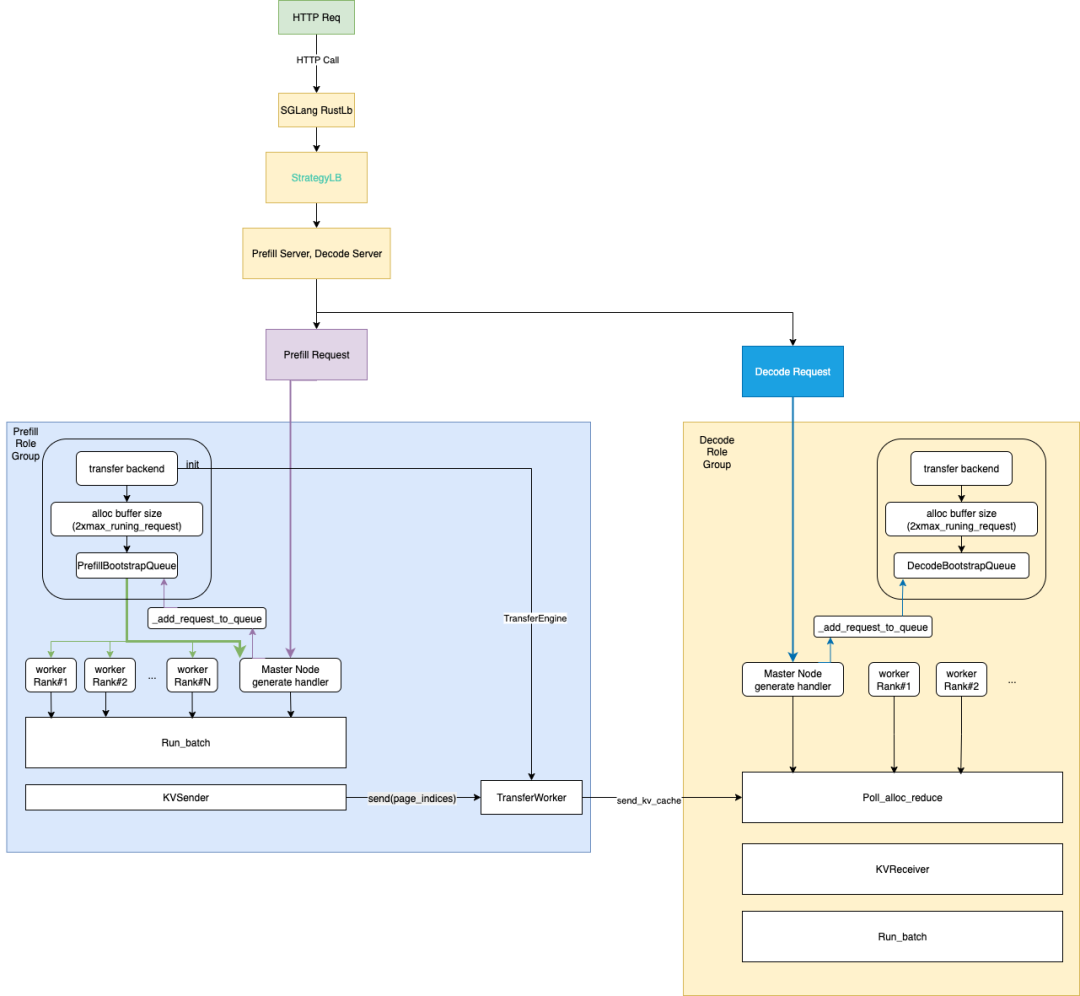
Each prefill and decode process launches a background thread running a persistent event loop. This loop collects requests, batches their inputs with the required KV cache, and initiates the inference task.
Experimental Setup: H800 SuperPod and SGLang Configuration
We conducted a systematic investigation of all feasible P/D disaggregated deployment configurations on 13 H800 DGX SuperPod servers. Our deep dive into SGLang v0.4.8's disaggregated mode involved evaluating online inference from both server-side and client-side perspectives.
To prepare, we aligned our hardware and software environments with the latest open-source community standards. A crucial first step is warming up the service by sending several batches of queries via the cURL API before starting formal measurements. This is necessary because SGLang's event loop worker threads require significant time for Just-In-Time (JIT) kernel compilation on a cold start.
Hardware: The H800 DGX SuperPod
The H800 SuperPod hardware used in our experiment is organized into racks as shown below:
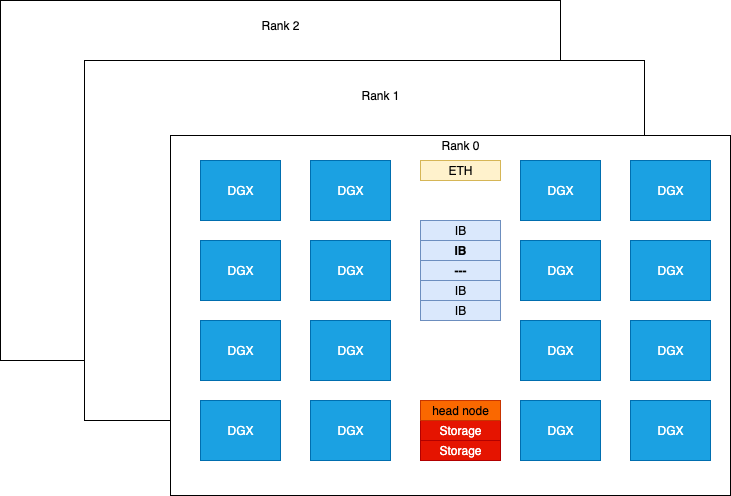
The NVIDIA H800 DGX offers computational performance comparable to the H100 DGX, with key differences in its weaker processing for FP64/FP32 data types and roughly half the communication bandwidth due to a reduced NVLINK configuration. Each H800 card is paired with a Mellanox CX-7 (MT2910) network card, interconnected via an InfiniBand switch, providing a peak bidirectional bandwidth of 50 GB/s.
In our NCCL tests, a single node achieved an nccl_all_reduce bus bandwidth of 213 GB/s. A dual-node test yielded 171 GB/s, and a cross-rack test clocked in at 49 GB/s.
Software: Tuning DeepEP and SGLang
In our P/D disaggregated tests, communication relies heavily on DeepEP and NVSHMEM. We built DeepEP from scratch (deep-ep==1.1.0+c50f3d6) in a custom Docker environment. We currently use Mooncake (mooncake-transfer-engine==v0.3.4) as the backend for disaggregation, as its latest transfer engine offers a 10x speedup over previous versions.
Our first task was tuning DeepEP. Our benchmarks revealed that bf16 performance was far superior to OCP fp8e4m3. We experimented with various combinations of NCCL and NVSHMEM environment variables, but compatibility issues with libtorch limited successful combinations. A successful tuning run should exhibit performance like this:
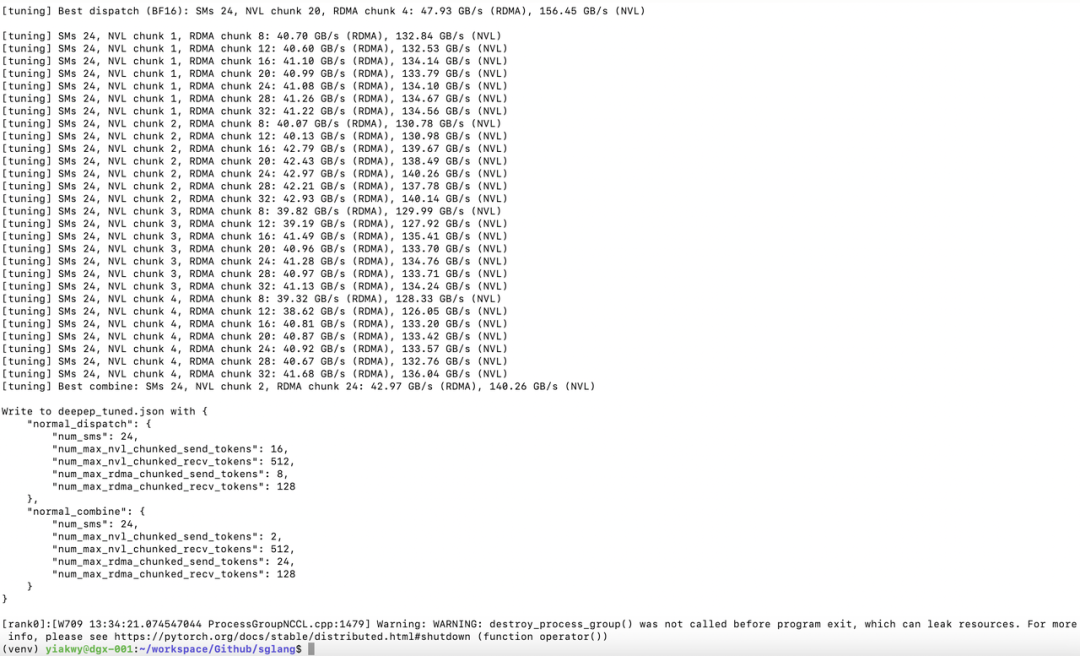
In SGLang v0.4.8, DeepGEMM is not enabled by default, and there are no out-of-the-box tuning configurations for the fused MoE Triton kernel on H800. Therefore, we custom-tuned the fused MoE Triton kernel to generate a configuration optimized for the H800. We ultimately enabled both DeepEP and DeepGEMM's JIT GEMM kernel to accelerate the prefill stage.
Deep Dive: Optimal Configurations for MoE Model Inference
Due to H800 system memory limitations, the deployment units for Prefill and Decode had to be chosen carefully. Global configurations, applicable to both roles, include key tunable parameters like WORLD_SIZE, TP, DP, max_running_request_size, and page_size. We recommend setting max_running_request_size to 128 and page_size to 32. For Prefill nodes, deepep_mode is set to normal; for Decode nodes, it's set to low_latency. Additionally, setting a small to medium chunk-prefill size for prefill nodes is one of the most effective ways to reduce TTFT.
Since we consistently observed prefill becoming the system bottleneck at high batch sizes, we enabled the faster GEMM implementation from DeepGEMM by default and standardized on moon-cake (0.3.4). We iterated through different P/D configurations to find the optimal server-side partition that maximized throughput in our client-side benchmarks.
Although we couldn't quite match DeepSeek's stellar performance under SLOs, we found that our P4D6 and (P3x3)D4 configurations clearly outperformed P4D9. For example, with a batch size of 1024, an input length of 1K, and an output length of 256, the system achieved an input throughput of about 95k tokens/sec and an output throughput of 20k tokens/sec. The TTFT was around 9-10 seconds, accounting for less than 30% of the total latency.
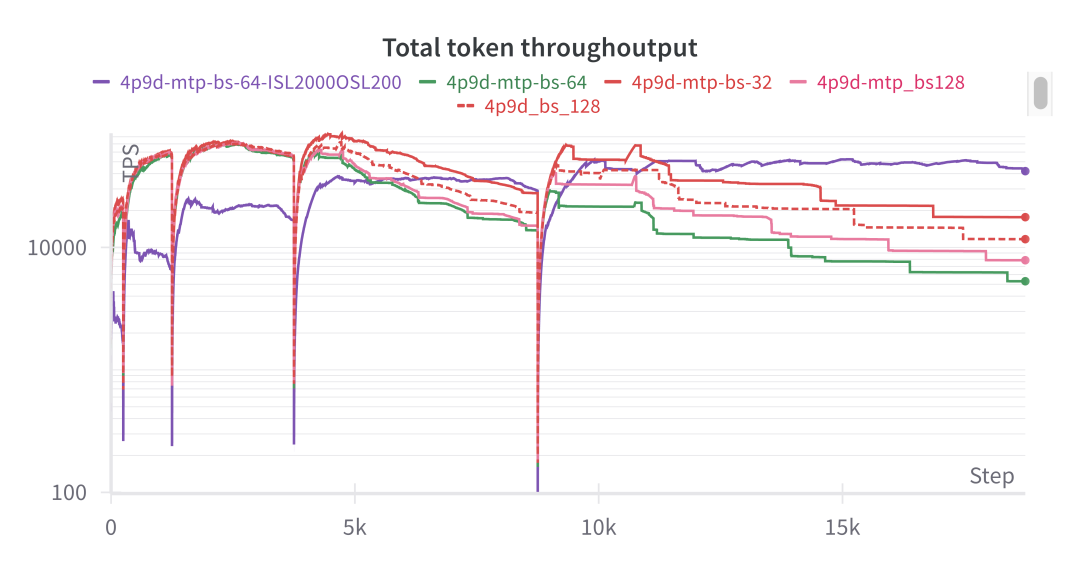
For the P2D2 configuration, limited KV cache reservation space led to frequent Out of Memory (OOM) errors on the client side with a batch size of 1024. When batch_size × input_length exceeded 128, we saw a sharp increase in TTFT, and the output throughput measurement in SGLang became unreliable.
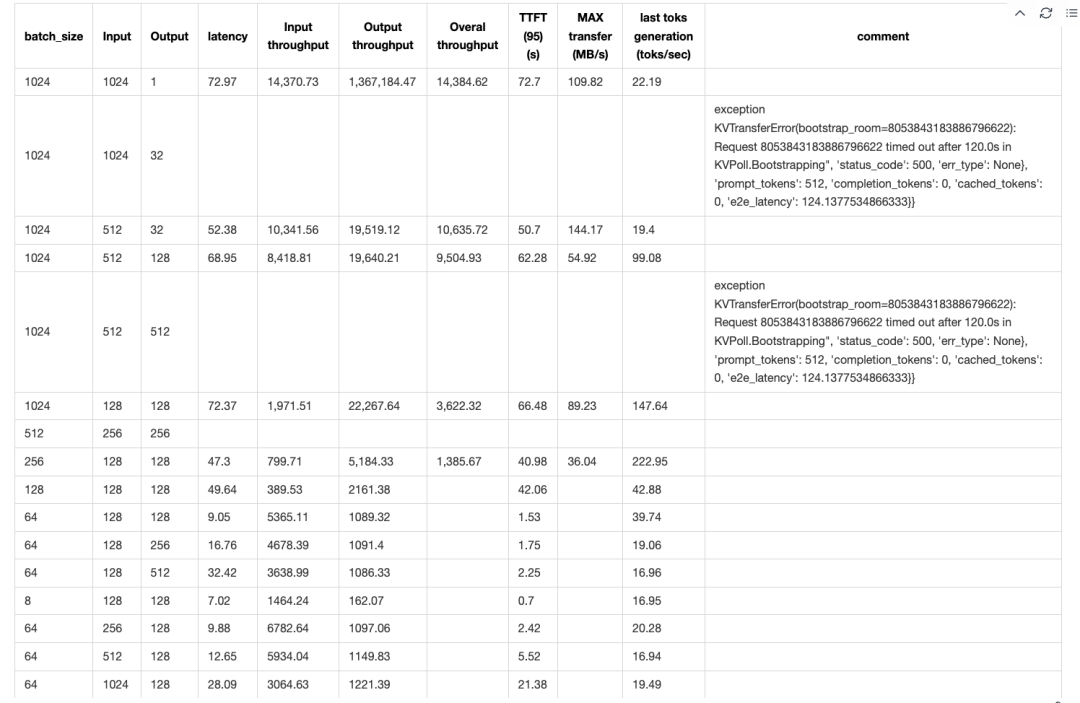
Based on these observations, we note that when batch_size × input_length exceeds 128 × 128 (using the P2D2 configuration as an example), KV cache transfer becomes the primary bottleneck, causing the entire system to become network I/O-bound on the data plane. Despite the 10x performance boost from the new transfer engine, this I/O-bound issue remains a persistent challenge.
It's worth noting that when the ratio of input sequence length to output sequence length is 4:1, GPU utilization on our H800 SuperPod is optimal, and the generation speed of the last token reaches its maximum.

Scaling Strategies: Analyzing P2D4 vs. P4D2 Configurations
In our P2D4 and P4D2 tests, a primary goal was to determine the best scaling direction to reduce TTFT and increase maximum throughput. As discussed, one effective way to lower TTFT is to decrease the chunk-prefill size while also reducing the data parallelism of the Prefill nodes.
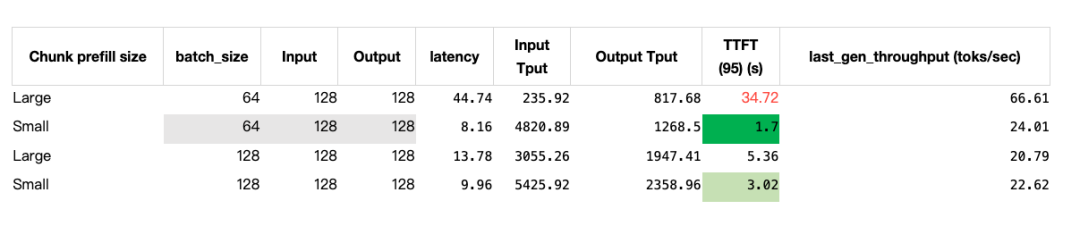
Enabling Data Parallelism and DP Attention (DP > 1) is non-negotiable; disabling them causes a significant drop in both TTFT and throughput.
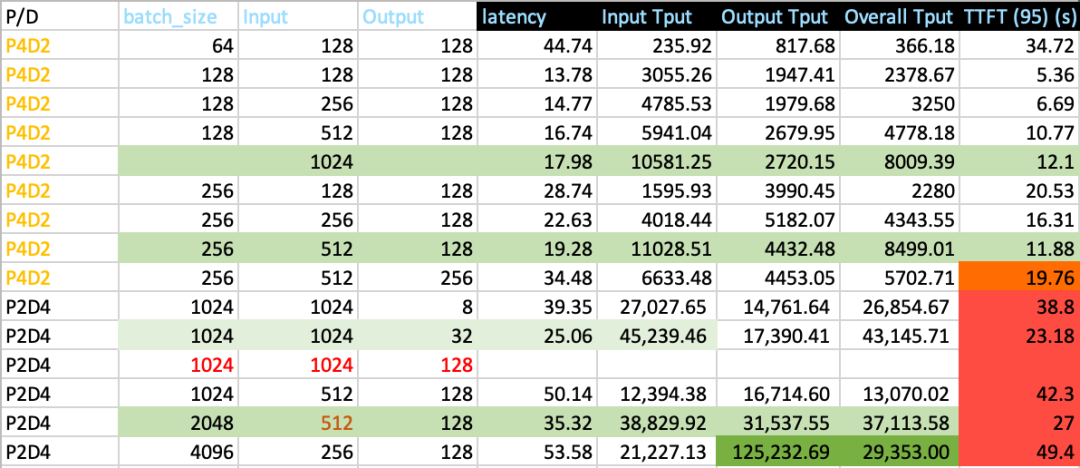
Based on these statistics, we conclude that in the P2D4 configuration, supporting an input sequence length greater than 1024 means most of the runtime is spent in the prefill stage. This makes TTFT nearly identical to the overall latency.

This led us to consider increasing the proportion of prefill nodes, targeting a ratio r where 1 < r < 2. In the P4D6 disaggregated test, the average Time to First Token (TTFT) climbed to around 10 seconds. When batch_size × input_length exceeded 2048 × 1024, TTFT began to increase with a steep slope.
Re-evaluating the 'Golden' P4D9 SGLang Configuration
The P4D9 configuration is often cited as the 'golden configuration' recommended by the SGLang team10, but in our H800 SuperPod tests, it failed to deliver satisfactory throughput. With an input length of 4K and an output length of 256, its overall throughput was capped at just 80,000 tokens/s.

We verified this in our user-side online tests. For short queries, the total output token throughput observed from the client's SDK was a mere 8,000 tokens/s.
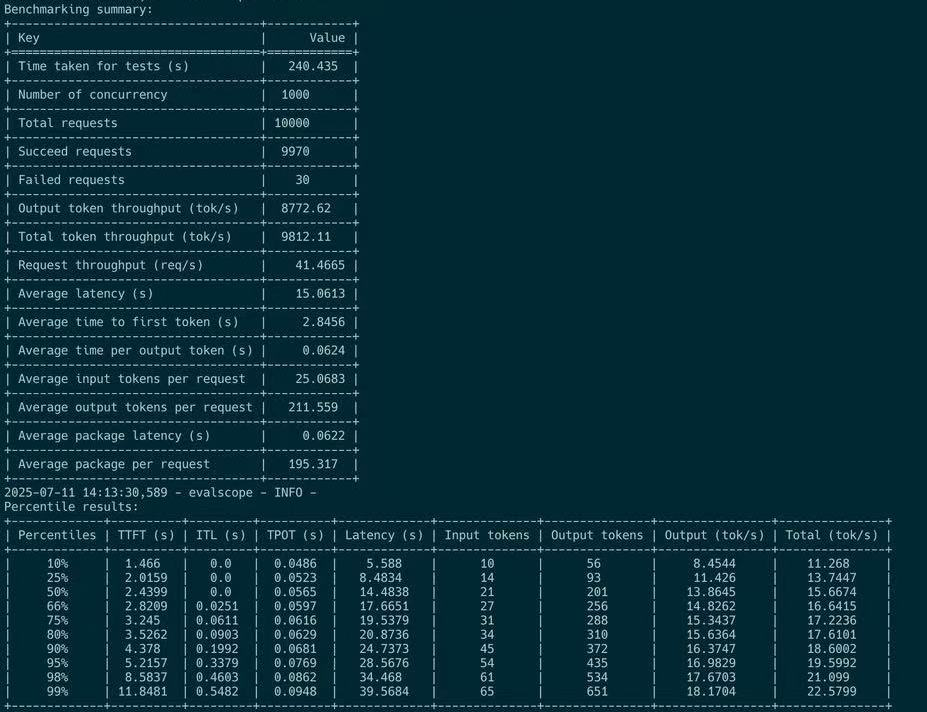
For long queries, the situation was even worse, with the client-side SDK observing a maximum throughput of only 400 tokens/s.
Key Findings for Optimizing LLM Inference on H800
Our comprehensive study of hosting a 671B parameter MoE model on a 13x8 H800 SuperPod using SGLang's disaggregated architecture yielded several key findings:
-
Prefill Dominates Performance: We confirmed that configurations with larger Prefill groups relative to Decode groups and smaller Tensor Parallelism (TP) sizes lead to superior TTFT and higher overall goodput. For production systems, using a smaller
chunked-prefillsize is also a critical tuning parameter for improving responsiveness. -
MoE Models Introduce Unique Bottlenecks: For large-scale MoE models, we observed that TTFT increases sharply when the product of
input_length×batch_sizeexceeds a specific threshold. This necessitates careful management of themax_running_request_sizeparameter to maintain performance under load.
Our optimized (P3x3)D4 configuration achieved an overall goodput of nearly 80,000 tokens/sec in short-query scenarios, a significant improvement over the 10,000 tokens/sec goodput from a comparable 2xH800 colocated deployment. The disaggregated architecture, by treating multiple nodes as a single logical unit tailored to the distinct computational needs of prefill and decode, offers a substantial leap in throughput. However, this power introduces operational fragility, as the failure of a single GPU can impact an entire service unit. Achieving a production-ready balance between deployment scale and reliability remains a critical challenge.
Our future work will focus on optimizing the underlying communication libraries to further enhance the performance of the Prefill nodes and continue to drive down the Time to First Token.
Authors
Lei Wang, Yujie Pu, Andy Guo, Yi Chao, Yiwen Wang, and Wei Xue.
Acknowledgements
We thank Mr. Yiwen Wang and Prof. Wei Xue for their invaluable support and suggestions. Thanks to Andy Guo for handling the client-side testing, Yujie Pu for the deployment to validate MTP and the (P3x3)D4 configuration, and Yi Chao for assisting with resource arrangement. We also extend our sincerest gratitude to the SGLang core team and community for their engineering contributions and rapid feedback.
Footnotes
-
Throughput is Not All You Need: Maximizing Goodput in LLM Serving using Prefill-decode Disaggregation, Junda Chen, Yinmin Zhong, Shengyu Liu, Yibo Zhu, Xin Jin, Hao Zhang, 3 March 2024, accessed online on 12 July 2024. ↩ ↩2 ↩3
-
DeepSeek OpenWeek: Infrastructure and Performance Insights, https://github.com/deepseek-ai/open-infra-index?tab=readme-ov-file ↩
-
SGLang bench_one_batch_server.py script, https://github.com/sgl-project/sglang/issues/6017, retrieved on 12 July 2024. ↩
-
SGLang genai-bench: Performance Benchmarking Tool, https://github.com/sgl-project/genai-bench, accessed online on 18 July 2024 ↩
-
Evaluation Framework for Large Models, ModelScope team, 2024, https://github.com/modelscope/evalscope, retrieved on 12 July 2024. ↩
-
MoonCake transfer engine performance, https://kvcache-ai.github.io/Mooncake/performance/sglang-benchmark-results-v1.html, accessed online 18 July 2024 ↩ ↩2
-
Orca: A Distributed Serving System for Transformer-Based Generative Models, Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun, OSDI 2022, https://www.usenix.org/conference/osdi22/presentation/yu ↩
-
SARATHI: efficient LLM inference by piggybacking decodes with chunked prefills, https://arxiv.org/pdf/2308.16369 ↩ ↩2 ↩3
-
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized large language model serving, Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, Hao Zhang, 6 Jun 2024, https://arxiv.org/pdf/2401.09670 ↩ ↩2
-
Large-scale EP deployment guide, https://lmsys.org/blog/2024-05-05-large-scale-ep/, accessed online on 12 July 2024 ↩ ↩2
-
Dynamo Workflow Architecture, https://github.com/ai-dynamo/dynamo/blob/main/docs/images/dynamo_flow.png, accessed online on 18 July 2024 ↩
{kind=link}