The field of artificial intelligence is undergoing a fundamental transformation, driven by the development and rapid evolution of the Transformer architecture. These models have not only established new benchmarks in Natural Language Processing (NLP) but have also become a foundational technology across numerous AI domains.
Powered by a unique attention mechanism and an inherent capacity for parallel processing, the Transformer model represents a significant advance in our ability to process and generate human language with remarkable accuracy and efficiency.
First introduced by Google researchers in the 2017 paper "Attention Is All You Need," the Transformer architecture is the engine behind influential models like ChatGPT. It has been the cornerstone of OpenAI's language model development and a key component in projects such as DeepMind's AlphaStar.
In this era of generative AI, a clear understanding of Transformer models is essential for data scientists, engineers, and NLP practitioners. As the core technology behind many of today's most significant AI breakthroughs, this article provides a detailed examination of the architecture that is reshaping our world.
What is a Transformer Model? Core Concepts
At its core, the Transformer was designed to solve sequence-to-sequence tasks, such as machine translation. Any task that involves converting an input sequence (e.g., a sentence in English) into an output sequence (the same sentence in French) is a primary application. The model's name reflects this function—it transforms one sequence into another.
A Transformer model is a neural network architecture that learns context and relationships within sequential data. It learns to understand and generate human-like text by analyzing the patterns and connections between words in vast datasets.
Transformers represent the current state-of-the-art for most NLP tasks, moving beyond the classic encoder-decoder architecture. While previous models relied on Recurrent Neural Networks (RNNs) to process sequences element by element, Transformers introduced a new approach by eliminating recurrence entirely.
Transformers are masterfully designed to grasp context and meaning by analyzing the relationships between every element in a sequence simultaneously. They achieve this almost entirely through a powerful mathematical technique called attention.
A Brief History of Transformer AI
The Transformer model burst onto the scene in 2017 with the landmark Google research paper, "Attention Is All You Need." It quickly became one of the most influential developments in modern machine learning.
This wasn't just a theoretical breakthrough. The concept was quickly implemented in popular frameworks, notably in TensorFlow's Tensor2Tensor package. The Harvard NLP group further accelerated its adoption by publishing an annotated guide to the paper, complete with a PyTorch implementation.
Its introduction sparked an explosion of innovation in what is now often called Transformer AI. This revolutionary model laid the groundwork for a new generation of large language models (LLMs), including the highly influential BERT. By 2018, these developments were already being hailed as a watershed moment for NLP.
Then, in 2020, researchers at OpenAI announced GPT-3. Within weeks, the internet was flooded with stunning examples of its versatility. People used it to generate poetry, write code, compose songs, and even design websites, capturing the public's imagination like never before.
In a 2021 paper, scholars at Stanford University aptly named these powerful, general-purpose models "foundation models," highlighting their fundamental role in reshaping the AI landscape. Their work underscored how Transformers have not only revolutionized the field but have also pushed the frontiers of what AI can achieve, heralding a new era of possibilities.
"We are in an era where simple methods like neural networks are giving us an explosion of new capabilities," says Ashish Vaswani, a former senior research scientist at Google and a co-author of the original Transformer paper.
The Paradigm Shift: Why Transformers Replaced RNNs
Before Transformers arrived, Recurrent Neural Networks (RNNs), and their more advanced variant LSTMs, were the go-to solution for handling sequential data. An RNN works by processing a sequence one element at a time, maintaining an internal "memory" of what it has seen so far.
The Transformer was inspired by the encoder-decoder structure common in RNNs. However, it completely abandoned their core principle of recursion in favor of the attention mechanism.
Beyond just improving performance on existing tasks, Transformers unlocked a new architecture for tackling a wide range of problems, from text summarization and image captioning to speech recognition.
So, what was holding RNNs back? They were notoriously inefficient for complex NLP tasks for two main reasons:
- The Sequential Bottleneck: RNNs process data one word at a time. This sequential nature makes it impossible to parallelize the computation, leading to incredibly long training times on large datasets.
- Long-Range Dependencies: Because of their step-by-step process, RNNs struggle to remember the context from words that appeared much earlier in a long sentence or paragraph. This is known as the vanishing gradient problem, where the model effectively "forgets" distant context.
The shift to Transformers was driven by their elegant solution to both of these problems. By processing all words at once and using the attention mechanism to weigh the importance of every word in relation to every other word, Transformers became the natural and far more powerful successor to RNNs.
Now, let's dive into how they actually work.
How Transformer Architecture Works: An In-Depth Look
Originally designed for machine translation, the Transformer architecture excels at converting an input sequence into an output sequence. It was the first model of its kind to rely entirely on self-attention to compute representations of its input and output, without using the sequence-aligned loops of RNNs or convolution. At its heart, the Transformer maintains a classic encoder-decoder structure.
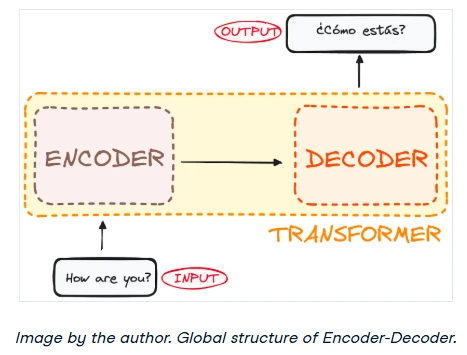
If we imagine a Transformer as a black box for language translation, it would take a sentence in one language and produce its translation in another.

Peeking inside that black box, we find two main components: an encoder and a decoder.
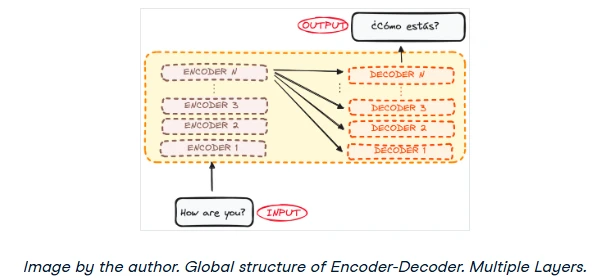
In reality, the encoder and decoder aren't single components but stacks of identical layers. The original paper used a stack of 6 encoders and 6 decoders, but this number is adjustable. All encoders in the stack share the same architecture, and all decoders do as well. The input flows through each encoder, with the final output becoming the input for every decoder in the stack.
Now that we have the 30,000-foot view, let's zoom in on the encoder and decoder to understand how they work their magic.
The Encoder: Processing the Input Sequence
The encoder's job is to read the input sequence and generate a rich, context-aware representation. Unlike older models that processed words in isolation, the Transformer's encoder understands each word by considering its relationship to all other words in the sentence.
Here's a look at its internal structure:
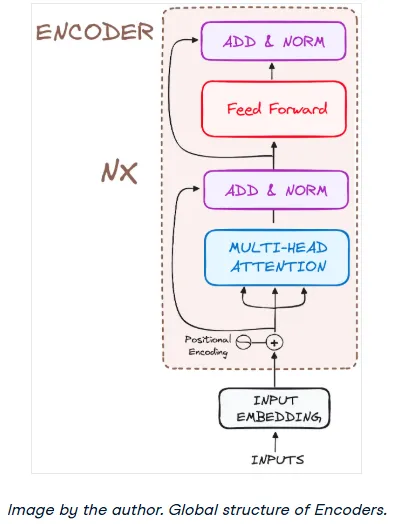
Let's walk through its workflow step-by-step.
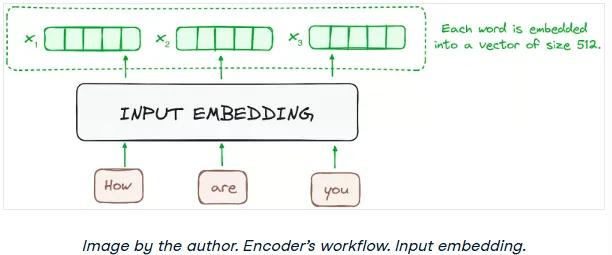
Step 1: Input Embedding
The journey begins at the bottom-most encoder. Here, an embedding layer converts the input tokens (words or sub-words) into numerical vectors. These vectors, or embeddings, capture the semantic meaning of the tokens.
Every encoder in the stack expects a list of vectors, each with a fixed size (e.g., 512 dimensions in the original paper). For the first encoder, these are the word embeddings. For all subsequent encoders, the input is the output from the encoder directly below it.
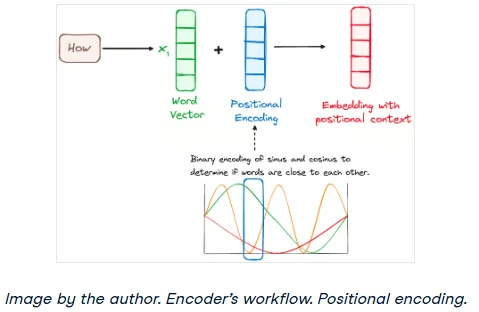
Step 2: Encoder Positional Encoding
Since Transformers process all words simultaneously, they have no inherent sense of word order. Is "the dog chased the cat" the same as "the cat chased the dog"? Of course not. To solve this, we inject information about the position of each token.
This is done through positional encoding. A vector containing positional information is added to each input embedding. The original paper proposed a clever method using sine and cosine functions of different frequencies. This technique creates a unique positional "signature" for each spot in the sequence, allowing the model to learn the importance of word order.
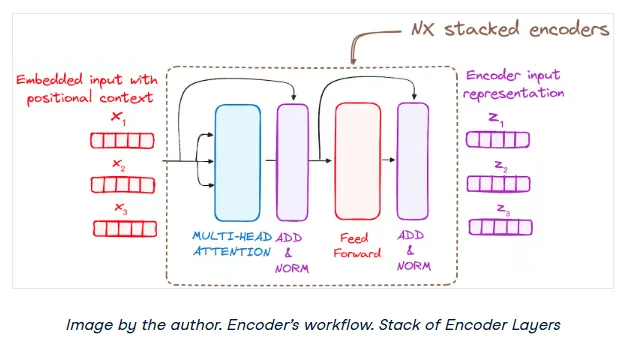
Step 3: The Encoder Layer Stack
An encoder is made up of a stack of identical layers (the original paper used 6). Each layer's purpose is to further refine the contextual understanding of the input sequence.
A single encoder layer has two main sub-modules:
- Multi-Head Self-Attention
- A Position-wise Feed-Forward Network
Crucially, it also uses residual connections and layer normalization around each of these sub-modules.
Understanding the Multi-Head Self-Attention Mechanism
This is where the magic happens. In the encoder, the attention mechanism is called self-attention because the sequence is paying attention to itself. This allows the model to weigh the importance of every word in the input sequence as it processes a specific word. For instance, in the sentence "The animal didn't cross the street because it was too tired," self-attention helps the model understand that "it" refers to "the animal," not "the street."
It calculates these relationships using three vectors for each input token:
- Query (Q): The current word's "question" about other words.
- Key (K): Other words' "labels" or "identifiers."
- Value (V): The actual substance or meaning of the other words.
The idea is to match the Query of one word with the Keys of all other words to determine how much attention to pay, and then use those attention scores to create a weighted sum of the Values.
Instead of doing this just once, Transformers use Multi-Head Attention. The Q, K, and V vectors are split into multiple smaller pieces, or "heads." Each head performs the attention calculation in parallel, allowing the model to learn different types of relationships simultaneously.
The detailed architecture is as follows:
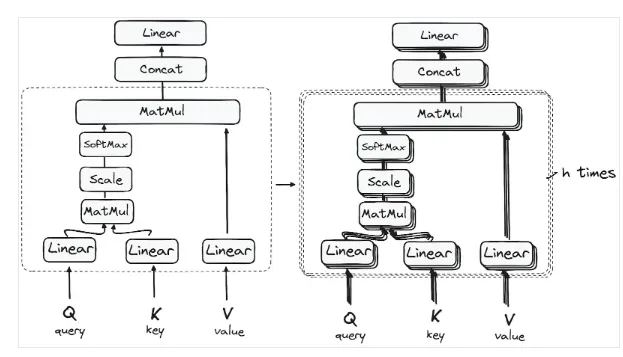
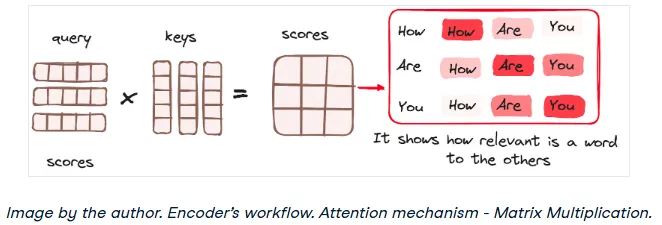
1. Matrix Multiplication — Dot Product of Query and Key
First, we calculate a score matrix by taking the dot product of the Query matrix and the Key matrix. This score matrix determines how much focus each word should place on every other word in the sequence. A higher score means more attention.
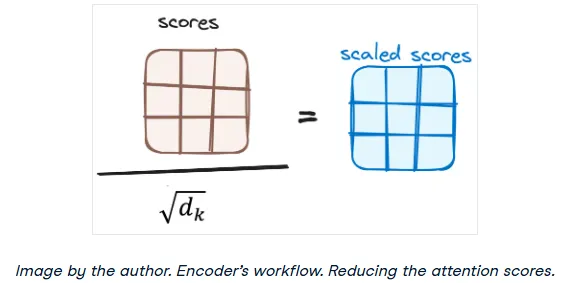
2. Scaling Down the Attention Scores
The scores are then scaled down by dividing them by the square root of the dimension of the key vectors. This is a simple but crucial step to ensure more stable gradients during training, preventing the scores from becoming too large.
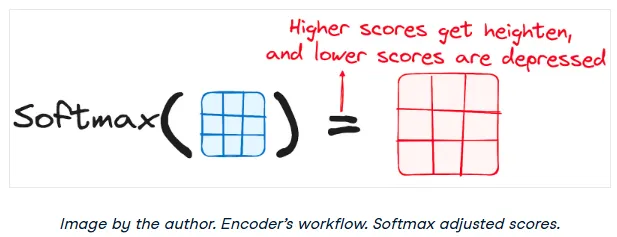
3. Applying Softmax to the Scaled Scores
Next, a softmax function is applied to the scaled scores. This converts the scores into probabilities, all summing to 1. The softmax function amplifies the high scores and diminishes the low ones, effectively forcing the model to focus on the most relevant words.
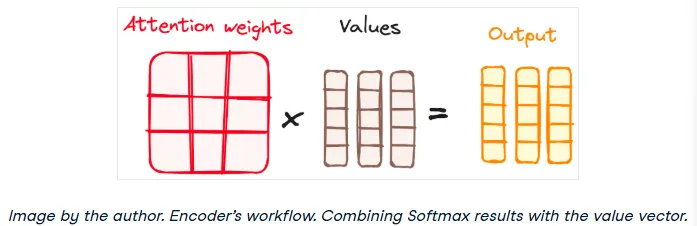
4. Combining Softmax Results with the Value Vector
Finally, the softmax probabilities (the attention weights) are multiplied by the Value vector. This has the effect of "drowning out" the irrelevant words (those with low attention scores) and keeping the words that are important. The result is an output vector that contains a contextual representation of the word.
And that's the output of a single attention head!
So, why is it called Multi-Head Attention? Because this entire process happens in parallel across multiple heads. Each head can learn a different aspect of the language. For example, one head might focus on syntactic relationships, while another focuses on semantic ones. The outputs from all heads are then concatenated and passed through a final linear layer to produce the final output of the multi-head attention block. This diversity is what makes the mechanism so powerful.
Residual Connections and Layer Normalization
Each sub-layer in the encoder (both the attention block and the feed-forward network) has a residual connection around it, followed by layer normalization. The residual connection simply adds the input of the sub-layer to its output. This helps combat the vanishing gradient problem and allows for much deeper networks. The layer normalization then re-scales the output to have a mean of 0 and a standard deviation of 1, ensuring stability.
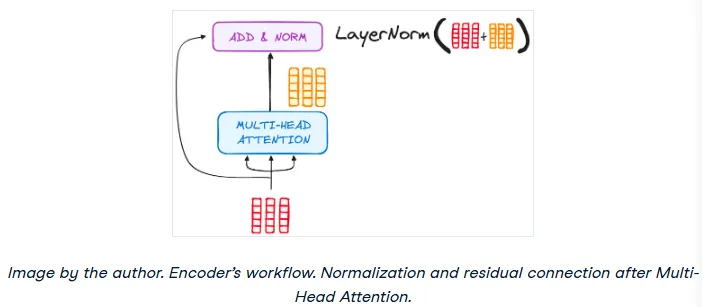
Feed-Forward Network
The output from the attention sub-layer then passes through a position-wise feed-forward network. This is a relatively simple network consisting of two linear layers with a ReLU activation function in between. It provides an additional transformation step, further processing the output from the attention mechanism. This entire block also has a residual connection and layer normalization.
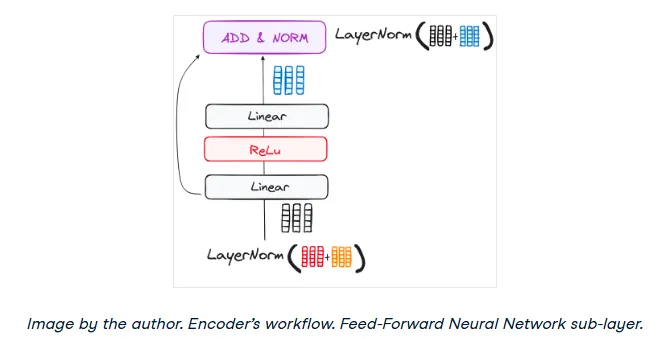
Step 4: The Encoder's Output
The output of the final encoder layer is a set of attention-rich vectors, one for each input token. This sequence of vectors contains the original information plus a deep contextual understanding learned from the attention mechanisms. This output is then passed to each of the decoder layers, guiding them to pay attention to the right parts of the input sequence.
You can think of the encoder stack like building a tower. Each layer adds a new level of understanding, allowing the model to learn diverse and powerful attention patterns, which significantly boosts the predictive power of the network.
The Decoder: Generating the Output Sequence
The decoder's job is to take the encoder's output and generate the target text sequence, one word at a time. Its structure is very similar to the encoder's, but with a few key differences. It features two Multi-Head Attention layers, a position-wise feed-forward layer, and also uses residual connections and layer normalization.
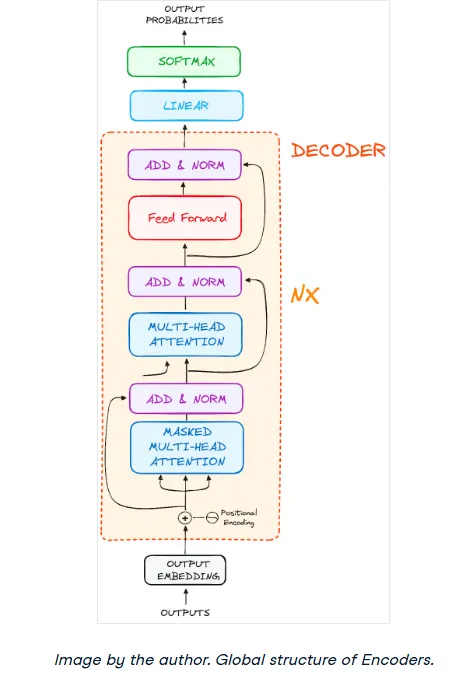
These components function much like their encoder counterparts, but the decoder's attention layers have distinct roles. The final step involves a linear layer and a softmax function to predict the next word.
Crucially, the decoder operates in an autoregressive fashion. It starts with a special "start" token and uses the list of words it has already generated as part of its input for the next step. This process continues until it generates a special "end of sequence" token.
Step 1: Output Embedding
Just like the encoder, the decoder's process begins by passing its input (the previously generated words) through an embedding layer.
Step 2: Decoder Positional Encoding
And again, like the encoder, these embeddings are combined with positional encodings to give the decoder a sense of the sequence order.
Step 3: The Decoder Layer Stack
The decoder also consists of a stack of identical layers (6 in the original paper). Each layer has three main sub-components:
- Masked Multi-Head Self-Attention
- Encoder-Decoder Multi-Head Attention
- Feed-Forward Neural Network
Step 3.1: Masked Self-Attention Mechanism
The first attention layer is a self-attention mechanism, but with a critical twist: it's masked. This masking prevents the decoder from "cheating" by looking ahead at words that come later in the sequence. When predicting the third word, the model should only have access to the first and second words.
For example, when calculating the attention score for the word "are" in "how are you," the model is prevented from peeking at the word "you."
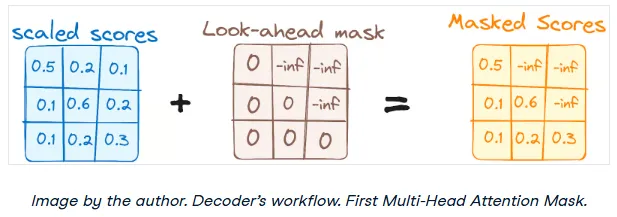
This ensures that the prediction for any given position can only depend on the known outputs at previous positions, which is essential for a generative model.
Step 3.2: Encoder-Decoder Multi-Head Attention (Cross-Attention)
In the second attention layer, the encoder and decoder finally meet. This layer performs cross-attention. It takes the Queries from the previous decoder layer (the masked self-attention output) and matches them against the Keys and Values from the encoder's final output.
This is the most important step for translation or question-answering, as it allows the decoder to focus on the most relevant parts of the input sentence when generating the output sentence.
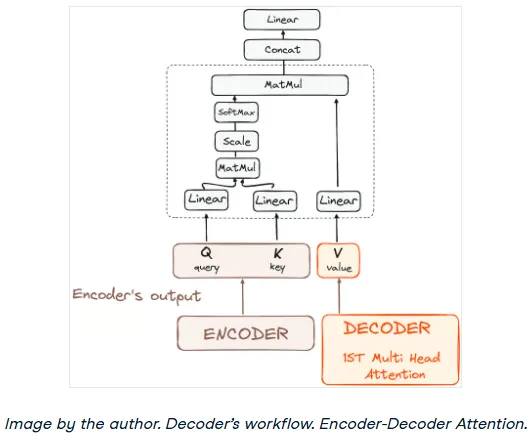
This mechanism effectively integrates the contextual information from the encoder with the sequence being generated by the decoder.
Step 3.3: Feed-Forward Network
Similar to the encoder, the output of the cross-attention layer is passed through a position-wise feed-forward network for further processing.
Step 4: Linear Classifier and Softmax for Generating Output Probabilities
The journey culminates as the output from the final decoder layer is fed into a final linear layer, which acts as a classifier. The size of this layer is equal to the size of the vocabulary (the total number of unique words the model knows).
The output of this linear layer (a vector of raw scores called logits) is then passed through a softmax function. The softmax converts these scores into probabilities, with each probability corresponding to a word in the vocabulary. The word with the highest probability is selected as the next word in the sequence.
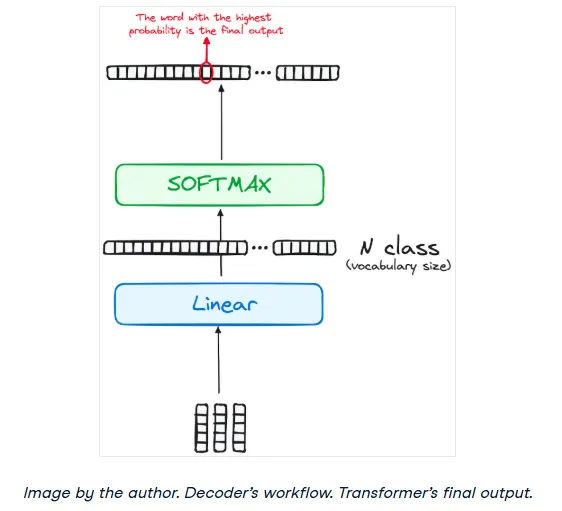
Normalization and Residual Connections
Just like in the encoder, each sub-layer (Masked Self-Attention, Cross-Attention, Feed-Forward Network) is wrapped with a residual connection and followed by layer normalization.
The Decoder's Output
The decoder generates the output sequence one token at a time. After predicting a word, it appends that word to its input and runs the entire process again to predict the next word. This cycle continues until the model predicts a special end-of-sequence token.
And remember, the decoder can also be a stack of N layers. This layered architecture allows the model to learn increasingly complex patterns, distributing its focus across different attention heads and layers to significantly boost its predictive power.
The final architecture, as seen in the original paper, looks like this:
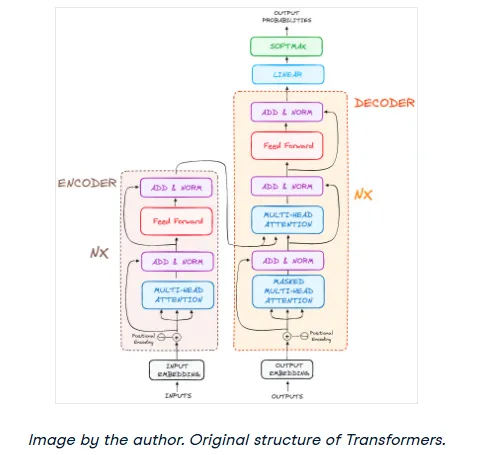
Real-World Examples: BERT, LaMDA, and ChatGPT
BERT
Released by Google in 2018, BERT (Bidirectional Encoder Representations from Transformers) was a game-changer. It's an open-source framework that revolutionized NLP with its unique bidirectional training. Unlike previous models that read text in one direction, BERT learns context from both the left and right sides of a word simultaneously.
This deep, bidirectional understanding allowed BERT to achieve state-of-the-art performance on a wide range of tasks, from question-answering to sentiment analysis. Google quickly integrated it into its search engine to better understand natural language queries, marking a huge leap forward in search technology.
LaMDA
LaMDA (Language Model for Dialogue Applications) is a Transformer-based model from Google, specifically fine-tuned for conversational AI. Announced at Google I/O 2021, LaMDA is designed to generate more natural, open-ended, and contextually relevant dialogue, making it ideal for advanced chatbots and virtual assistants. Its focus on fluid conversation marks a significant step toward more human-like AI interaction.
GPT and ChatGPT
Developed by OpenAI, the GPT (Generative Pre-trained Transformer) series is renowned for its incredible ability to generate coherent and contextually rich text. Starting with GPT-1 in 2018 and leading to the massively influential GPT-3 in 2020 and beyond, these models excel at content creation, conversation, translation, and even coding.
ChatGPT, a variant fine-tuned for dialogue, brought the power of large language models to the mainstream, showcasing their ability to generate stunningly human-like responses and sparking a global conversation about the future of AI.
The ecosystem of foundation models, particularly Transformers, is expanding at a breakneck pace. There is also a growing trend towards open-sourcing these powerful models, led by platforms like Hugging Face's Model Hub, which hosts thousands of pre-trained models for developers to use and build upon.
How Transformer Performance is Measured
So, how do we know if these models are any good? Evaluating the performance of Transformer models involves a systematic approach using standardized tests and metrics.
Machine Translation Tasks
For machine translation, models are tested on standard datasets like WMT (Workshop on Machine Translation), which provides challenging language pairs. Performance is measured using metrics like BLEU, METEOR, and TER, which assess the accuracy and fluency of the translation compared to a human-generated reference.
Question Answering (QA) Standards
To evaluate QA models, researchers use datasets like SQuAD (Stanford Question Answering Dataset), Natural Questions, and TriviaQA. These datasets contain questions paired with context passages. Models are scored on their ability to find the correct answer within the text, using metrics like F1-score (a balance of precision and recall) and Exact Match.
Natural Language Inference (NLI) Benchmarks
NLI tasks test a model's ability to understand the logical relationship between two sentences (entailment, contradiction, or neutral). Datasets like SNLI, MultiNLI, and ANLI are used for this purpose. The primary metric is simply accuracy—how often the model correctly identifies the relationship.
Transformers vs. RNNs and CNNs: A Comparison
In the world of neural networks, how do Transformers stack up against other major architectures like RNNs and CNNs?
As we've discussed, Recurrent Neural Networks (RNNs) were built for sequential data. Their strength was their ability to maintain a memory of previous steps. However, this sequential processing was also their biggest weakness, creating a computational bottleneck and making it difficult to handle long-range dependencies. Transformers solve both problems with parallel processing and the attention mechanism, making them a far superior choice for most complex NLP tasks.
On the other hand, Convolutional Neural Networks (CNNs) are the undisputed champions of computer vision. They use filters (kernels) to scan over spatial data like images, efficiently extracting features and patterns. While excellent for spatial hierarchies, CNNs are not inherently designed for sequential information. They struggle to capture the long-range, ordered context that is critical for understanding language.
In short, each architecture is specialized. CNNs are for spatial data (images), while Transformers have become the dominant force for sequential data (language) due to their unparalleled ability to model complex, long-range relationships.
Conclusion: The Future is Built on Transformers
Transformers have catalyzed a paradigm shift in artificial intelligence. By replacing recurrence with a sophisticated self-attention mechanism, these models process sequential data with unprecedented efficiency and contextual awareness. Their capacity for parallelization and their ability to capture long-range dependencies have shattered previous performance benchmarks, accelerating progress across the field.
Pioneering models like Google's BERT and OpenAI's GPT series are testaments to the architecture's power, enhancing applications from search engines to scientific research.
Today, the Transformer architecture is an indispensable pillar of modern machine learning. It is the foundational technology driving the current AI boom, and its influence continues to expand. As researchers explore more efficient and scalable variations of the architecture, Transformers are poised to unlock new frontiers in multimodal AI, robotics, and beyond, solidifying their role as a cornerstone of future innovation.